
Simplifying Media Innovation at Netflix with Archer
Simplifying Media Innovation at Netflix with Archer
Imagine you are developing a quick prototype to sift through all the frames of the movie Bright to find the best shots of Will Smith with an action-packed background. Your goal is to get the computer vision algorithm right with high confidence without worrying about:
- Parallel processing
- Cloud infrastructures like EC2 instances or Docker Container Systems
- The location of ultra high definition (UHD) video sources
- Cloud storage APIs for saving the results
- Retry strategy should the process fail midway
- Asset redeliveries from the studios
In the past, our developers have had to think of all of these things and as you can see, it’s quite taxing when the goal is to simply get the algorithm right. In this blog post, we will share our journey into how we built a platform called Archer where everything is handled transparently enabling the users to dive right into the algorithm.


About us
We are Media Cloud Engineering (MCE). We enable high scale media processing which includes media transcoding, trailer generation, and high-quality image processing for artwork. Our compute farm runs tens of thousands of EC2 instances to crank through dynamic workloads. Some examples of compute-hungry use cases include A/B tests, catalog-wide re-encoding for
Our journey
Before Archer, distributed media processing in the cloud was already possible with an in-house developed media processing platform, codename Reloaded. Despite its power and flexibility, development in the Reloaded platform required careful design of dynamic workflow, data model, and distributed workers while observing software development best practices, continuous integration (CI), deployment orchestration, and a staged release train. Although these are the right things to do for feature rollout, it is an impediment and distraction for researchers who just wanted to focus on their algorithms. To gain agility and shield themselves from the distractions of cloud deployment our users were running their experiments on local machines as much as possible. But here the scale was limited. They eventually needed to run their algorithms against a large content catalog to get a better signal.
We looked into distributed computing frameworks like Apache Spark, Kubernetes, and Apache Flink. These frameworks were missing important features like first class support for media objects, custom docker image for each execution, or multi-tenant cluster support with fair resource balancing.

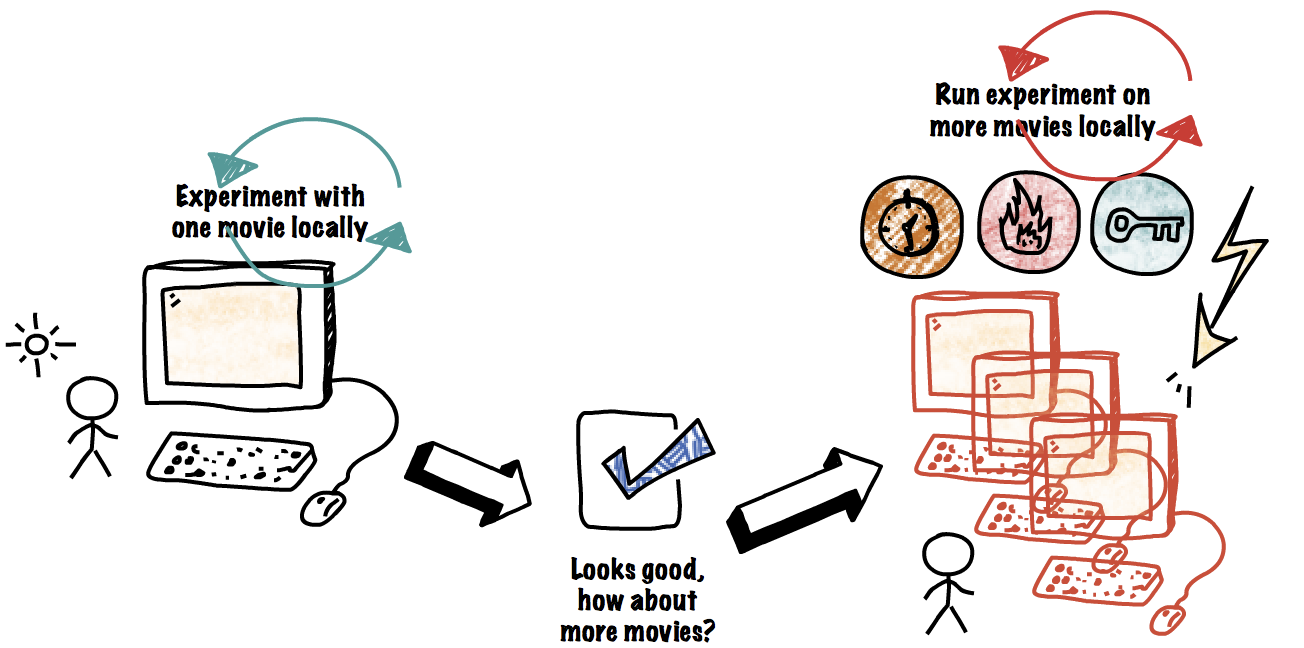
Then we realized that we could combine the best attributes from the Reloaded with the patterns found in the popular distributed computing frameworks and the synthesis mitigated the difficulties mentioned previously, providing an easy-to-use platform that runs at scale for ad-hoc experiments and certain types of production use cases.
Archer
Archer is an easy to use MapReduce style platform for media processing that uses containers so that users can bring their OS-level dependencies. Common media processing steps such as mounting video frames are handled by the platform. Developers write three functions: split, map and collect; and they can use any programming language. Archer is explicitly built for simple media processing at scale, and this means the platform is aware of media formats and gives white glove treatment for popular media formats. For example, a ProRes video frame is a first class object in Archer and splitting a video source into shot based chunks [1] is supported out of the box (a shot is a fragment of the video where the camera doesn’t move).
Many innovative apps have been built using Archer, including an application that detects dead pixels caused by defective digital cameras, an app that uses machine learning (ML) to tag audio and an app that performs automated quality control (QC) for subtitles. We’ll get to more examples later.


High-level view
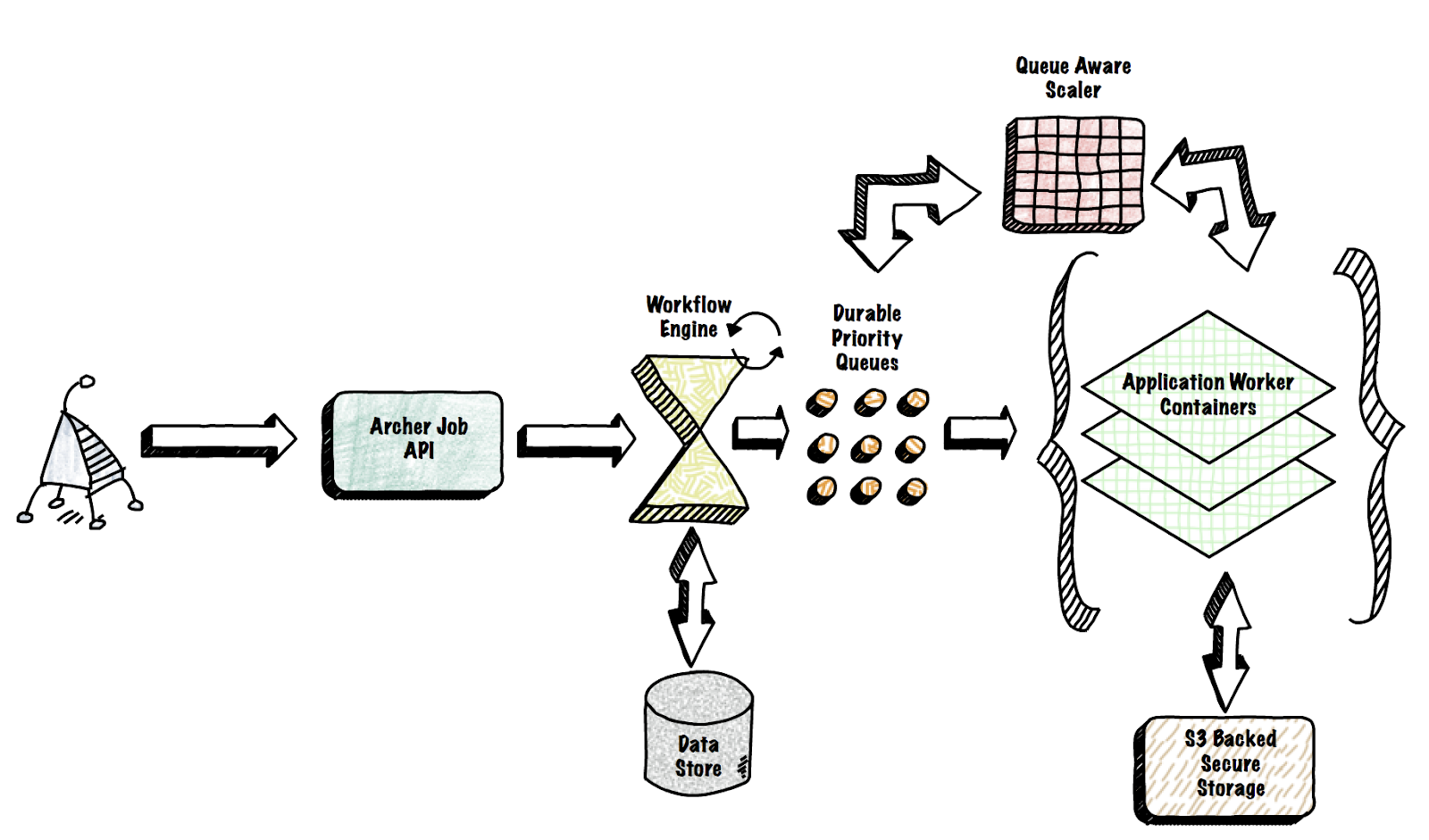
From a 10,000 foot view, Archer has multiple components to run jobs. Everything starts with a REST API to accept the job requests. The workflow engine then picks the request and drives the MapReduce workflow, dispatching work as messages to the priority queue. Application workers listen on the queue and execute the media processing functions supplied by the user. Given the dynamic nature of the work, Archer uses a queue aware scaler to continuously shift resources to ensure all applications get enough compute resources. (See Archer presentation at @Scale 2017 conference for a detailed overview and demo).
Simple to use
Simplicity in Archer is made possible with features like efficient access to large files in the cloud, rapid prototyping with arbitrary media files and invisible infrastructure.
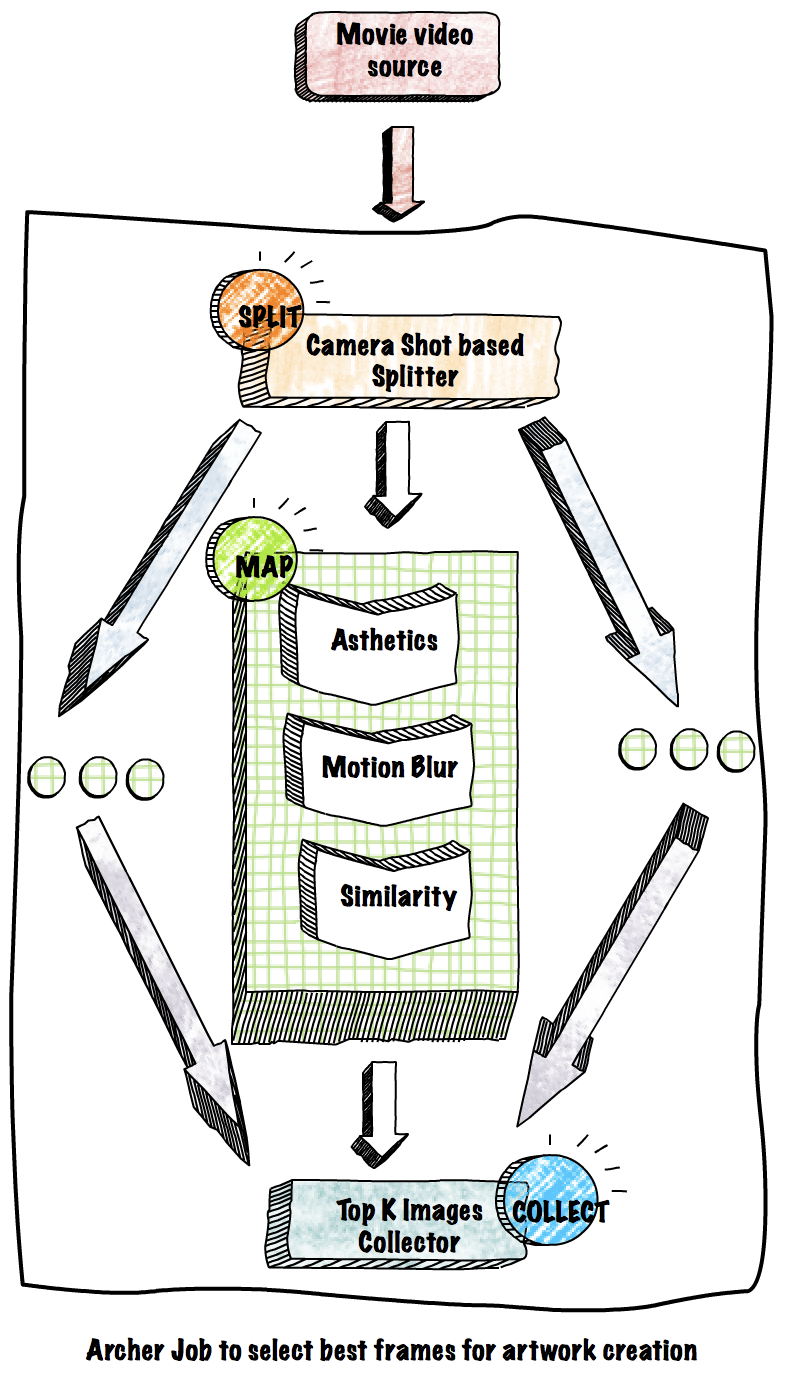
MapReduce style — In Archer, users think of their processing job as having three functions: split, map and collect. The job of the split function is to split media into smaller units. The map function applies a media processing algorithm to each split. The collect function combines the results from the map phase. Users can implement all three functions with the programming language of their choice or use built-in functions. Archer provides built-in functions for common tasks such as a shot based video frame splitter and a concatenating collector. It’s very common to build an application by only implementing map function and use built-ins for splitter and collector. Archer users contribute reusable functions to the platform as built-ins.
Video frames as images — Most computer vision (CV) algorithms like to work with JPEG/PNG images to detect complex features like motion estimation and camera shot detection. Video source formats use custom compression techniques to represent original sources, and decoding is needed to convert from the source format to images. To avoid the need to repeat the same code to decode video frames (different for each source format), Archer has a feature to allow users to pick image format, quality, and crop params during job submission.
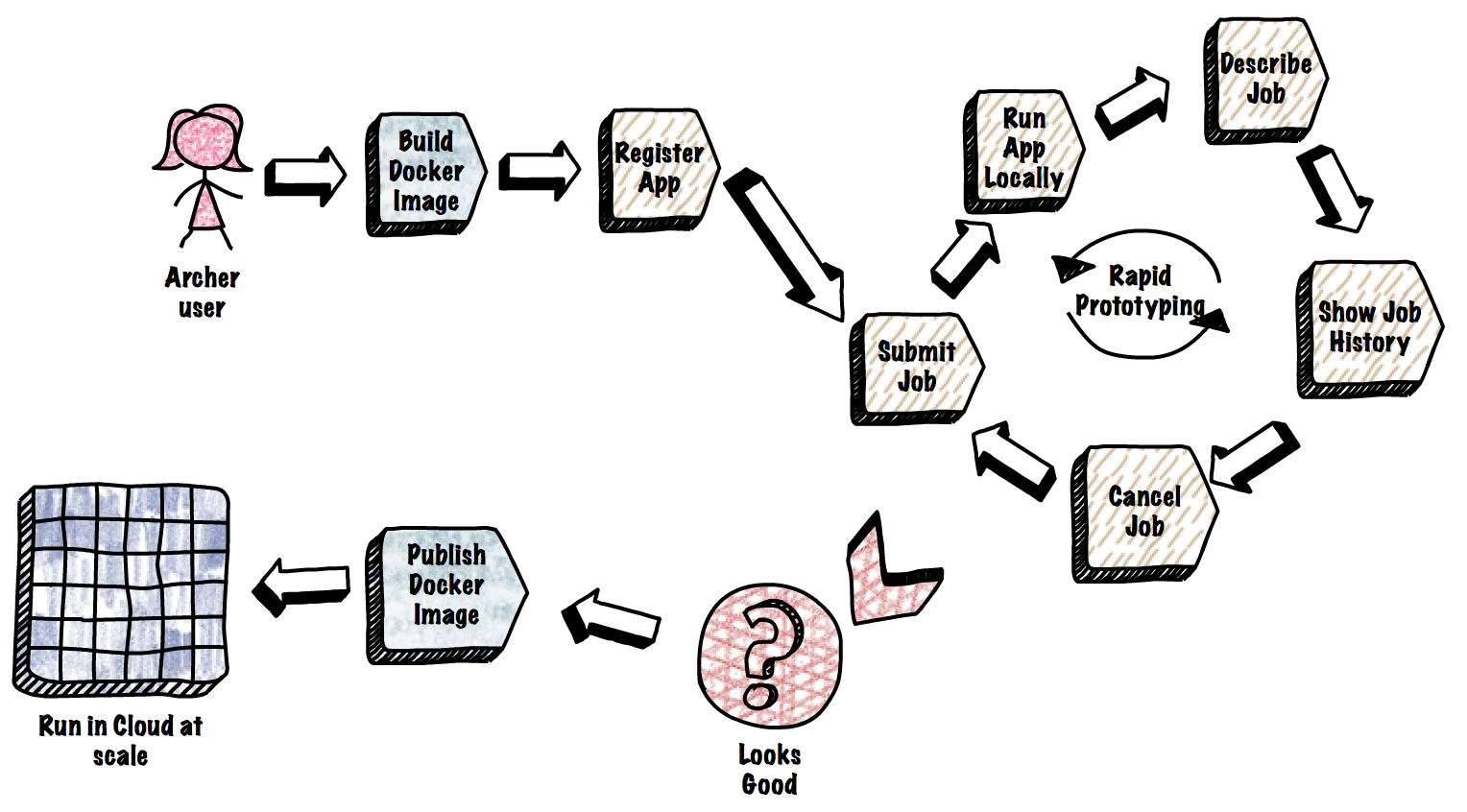
Container-based runtime — Archer users package their application as a docker image. They run the application locally or in the cloud in the same way. The container-based local development allows users to get an application into a working state quickly and iterate rapidly after that, then with a few commands, the application can be run in the cloud at scale. The Docker-based environment allows users to install operating system (OS) dependencies of their choice and each application can choose their OS-dependencies independent of other applications. For example, experiments run in Archer may install snapshot versions of media tools like ffmpeg and get quick feedback while production apps will depend on released versions. Archer uses Titus (container management platform at Netflix) to run containers at scale.


Access to content catalog — Most Archer applications need access to media sources from the Netflix content catalog. The Archer job API offers a content selector that lets users select the playable of their choice as input for their job execution. For example, you can run your algorithm against the UHD video source of the film Bright by just knowing the movie id. There is no need to worry about the location of the video source in the cloud or media format of the source.
Local development — The Developer Productivity team at Netflix has built a tool called Newt (Netflix Workflow Toolkit) to simplify local developer workflows. Archer uses Newt to provide a rich command line interface to make local development easy. Starting a new Archer job or downloading results is just a command away. These commands wrap local docker workflows and interactions with the Archer job API. It’s also easy to build applications in the programming language of choice.

Enabled by Archer
With a simple platform like Archer, our engineers are free to dream about ideas and realize them in a matter of hours or days. Without Archer to do the heavy lifting, we may not have attempted some of these innovations. Our users leveraged tens of millions of CPU hours to create amazing applications. Some examples:
- Dynamic Optimizer — a perceptual video encoding optimization framework.
- Subtitle authoring — shot change and burnt-in text location data surfaced by Archer applications are used for subtitle authoring.
- Optimal image selection — to find images that are best suited for different canvasses in the Netflix product interface.
- Machine assisted QC — to help in various QC phases. This assistance includes text on text detection, audio language checks, and detecting faulty video pixels.












Wrapping up
Archer is still in active development, and we are continually extending its capabilities and scale. The more experience we have with it, the more possibilities we see. Here are some of the items on our roadmap
- Enhance robustness with multi-region support
- SLAs and guaranteed capacity for different users and applications
- First-class support for audio sources (we already support video)
- A higher degree of runtime isolation between the platform and application
- Rich development experience for Python users
In an upcoming blog post, we will be writing about the secure media storage service that underpins Archer and other projects at Netflix.
The Archer platform is still relatively new. But the concept is daily being validated by the many teams at Netflix who are adopting it and producing innovative advances in the Netflix product. Enthusiasm and usage are growing, and so also is our need for engineering talent. If you are excited to work on large-scale distributed computing problems in media processing and think out of the box by applying machine learning and serverless concepts, we are hiring (MCE, Content Engineering). Also, check out research.netflix.com to learn more about research & data science at Netflix.
References
[1] S. Bhattacharya, A. Prakash, and R. Puri, Towards Scalable Automated Analysis of Digital Video Assets for Content Quality Control Applications, SMPTE 2017 Annual Technical Conference, and Exhibition, Hollywood & Highland, Los Angeles, California, 2017