
Streaming Video Experimentation at Netflix: Visualizing Practical and Statistical Significance
Streaming Video Experimentation at Netflix: Visualizing Practical and Statistical Significance
Streaming video experimentation at Netflix seeks to optimize the Quality of Experience (QoE for short) of the videos we stream to our 130 million members around the world. To measure QoE, we look at a wide variety of metrics for each playback session, including play delay; the rates of rebuffers (playback interruptions when the video buffer empties), playback errors, and user-initiated aborts; the average bitrate throughout playback; and
Many of our experiments are “systems tests”: short-running (hours to a week) A/B experiments that seek to improve one QoE metric without harming others. For example, we may test the production configuration of the
The treatment effects in these streaming experiments tend to be heterogeneous with respect to network conditions and other factors. As an example, we might aim to reduce play delay via predictive precaching of the first few seconds of the video that our algorithms predict a member is most likely to play. Such an innovation is likely to have only a small impact on the short play delays that we observe for high quality networks — but it may result in a dramatic reduction of the lengthy play delays that are more common on low throughput or unstable networks.
Because treatments in streaming experimentation may have much larger impacts on high (or low) values of a given metric, changes in the mean, the median, or other summary statistics are not generally sufficient to understand if and how the test treatment has changed the behaviour of that metric. In general, we are interested in how the distributions of relevant metrics differ between test experiences (called “cells” here at Netflix). Our goal is to arrive at an inference and visualization solution that simultaneously indicates which parts of the distribution have changed, and both the practical and statistical significance of those changes.
We’ve had success summarizing distributions of metrics within test cells, and how those distributions differ between cells, using quantile functions and differences between quantile functions, with uncertainty derived from fast bootstrapping procedures. Our engineering colleagues have quickly adapted to test results being reported via quantile functions, as they can tap into pre-existing intuition from familiar concepts.
The Quantile Function
The quantile function Q(?) is the inverse of the cumulative distribution function for a given random variable. It accepts as argument a probability ? (between zero and one) and returns a threshold value such that draws of the random variableare less than this value with probability ?. Formally,
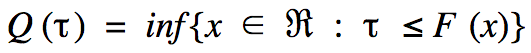
where F(x) is the cumulative distribution function for the random variable X. Q(0.50) returns the median, Q(0.95) returns the 95th percentile, and so forth.
Quantile functions are a great way to summarize distributions, as statisticians and non-statisticians alike have a fair amount of intuition about them. Concepts like medians, deciles, and percentiles — all special cases of quantiles — are mainstays of popular press reporting on economic matters (“What Percent Are You?”) and are familiar from standardized test scoring.
Here is a simulated example (with no relation to actual values, and with y-values suppressed)of data that might result from a streaming experiment aimed at reducing play delay for some subset of members:


In this example, Cell 1 corresponds to the current production experience, and the other Cells correspond to three proposed parameter configurations. Note that the y-axis is in units of seconds, and that point estimates of the median and other familiar quantiles can easily be read from the plot. In this case, the quantile functions for the Cells 1 and 4 are nearly identical, whereas Cells 2 and 3 feature decreases and increases, respectively, in all quantiles of play delay as compared with Cell 1.
Next, we need to determine if the differences between the treatment cells and the control cell are both practically and statistically significant.
Practical and Statistical Significance in One Chart
To quantify how distributions of a given metric differ between the cells, we plot the difference between each treatment cell quantile function and the quantile function for the current production experience (Cell 1).

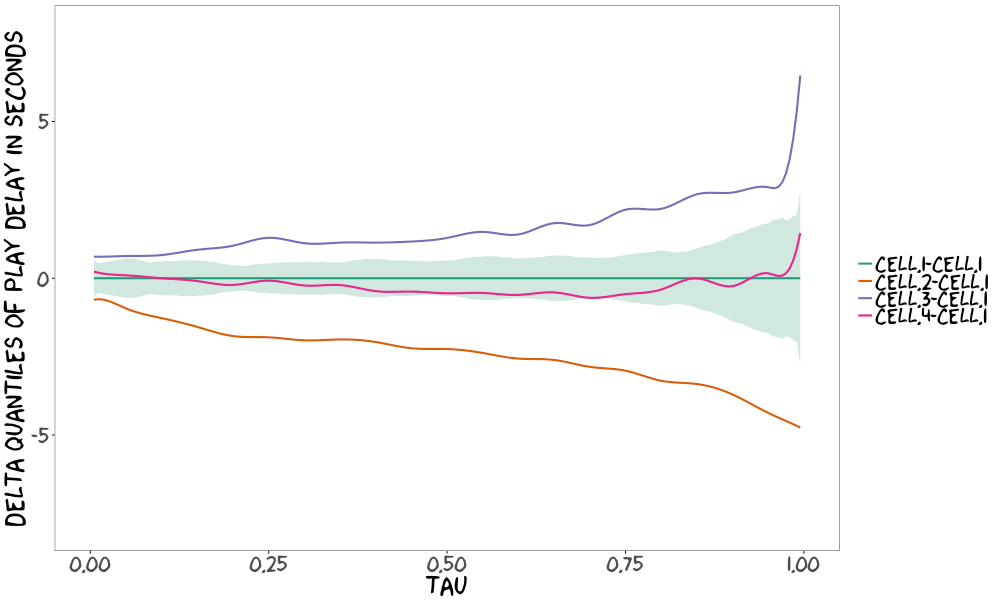
As the Y-axes of these “delta quantile” plots are in the original units of the metric, all of the intuition that we have about that metric can be brought to bear to understand the practical significance of the differences between test cells. In this simulated example above, Cell 2 successfully reduces the long tail of play delay: the upper quantiles of play delay are about 5 seconds lower than in Cell 1, indicating that we’ve improved this metric for viewers with the worst experience. This is an easy to intuit summary of the test result.
To quantify the statistical significance of differences between the quantile functions, we use two different bootstrapping procedures. First, to understand the variability within the production experience, we bootstrap that cell against itself by resampling (with replacement) twice, estimating the quantile function in each case, and then calculating the delta quantile function. Repeating this procedure, and then calculating confidence intervals as a function of ?, yields the uncertainty envelope plotted above (some more technical details are below). Provided a balanced experimental design, these confidence intervals tell us about the distribution of the delta quantile function under the null assumption that the distribution of the metric is invariant across the test cells.
In our simulated play delay example, the quantile function for Cell 4 is not statistically significant from that of Cell 1. In contrast, Cells 2 and 3 feature, respectively, statistically significant reductions and increases in most quantiles as compared with Cell 1, with the differences largest in magnitude for the upper quantiles. One advantage of this approach to uncertainty quantification is that we can quickly assess the significance of each test treatment with respect to the production experience. A downside is that the variability in the estimates of the treatment quantile functions are not taken to account.
As a second uncertainty quantification, in this case for a specific delta quantile function, we bootstrap each treatment cell against the production cell by resampling (with replacement) from each; estimate the quantile functions; take differences; and then calculate confidence envelopes. This procedure, which remains valid even if the sample sizes differ between cells, takes into account the uncertainty in the estimated quantile functions of both the production experience and treatment experience, and will yield wider, more conservative confidence envelopes if the uncertainty in the treatment cell quantile function is larger than that of the control cell. The downside is that it becomes unruly to visualize more than one uncertainty envelope in a single plot.
Here is the difference between the Cell 2 and Cell 1 quantile functions, along with the uncertainty envelope, for our simulated play delay example:


This one plot provides an illustration of the statistical (uncertainty envelope) and practical (y-axis is units of seconds) significance of the test treatment, and how they vary across the quantiles. Simple questions like “how much has the 95th percentile changed, and is that change significant?” can be answered by inspection.
Some technical details
Two interesting technical aspects of our bootstrap procedure are the significance adjustment to account for comparisons across many quantiles, and the speed gains achieved by operating on compressed data structures.
Multiple Comparisons. The confidence envelopes on the delta quantile functions are initially calculated pointwise: for each value of ?, we take the 0.025 and 0.975 percentiles of the bootstrap samples. Such intervals have, nominally, 95% probability of covering the true change at each value of ?. What we want are simultaneous, or path-wise, intervals that feature nominal 95% probability of the uncertainty envelope covering the true function in its entirety. To produce simultaneous uncertainty intervals, we adjust the point-wise confidence level according to the Bonferroni Correction — using an estimate of the number of independent values of the delta-quantile function (see Solow and Polasky, 1994):
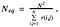
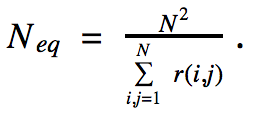
Here, r(i,j) is the sample correlation coefficient between the delta-quantile function evaluated at the ith and jth values of ?, calculated across the bootstrap samples, and N is the number of ? values at which the quantile functions are estimated. Note that as N increases, the correlations r(i,j) for nearby ? values will likewise increase, with the result that the value of Neq saturates for sufficiently large values of N, and the simultaneous uncertainty envelopes do not continue to grow wider as N increases.
Fast Bootstrapping on Big Data. Streaming experiments at Netflix can involve tens of millions of data points, and our goal is to perform the statistical analysis on the fly, so reports can be interactive. We therefore require that the bootstrapping procedures described above be very fast, even on large data sets.
Our approach is to approximate the data for each test cell using a compressed data object with a limited number of unique values. In particular, we approximate each empirical quantile function using several thousand evenly spaced points on the unit interval. Intuitively, this approximation assumes that changes in the metric smaller than dQ(?) = Q(? + 1/N) — Q(?) , where N is of order several thousand, are not of practical importance. Note that dQ(?) varies with ?; in the context of the play delay example, the distribution is right-skewed so that dQ(?) increases with ?. Intuitively, we assume that small changes in play delay may be important for those members who generally experience short play delays, whereas the smallest practically important change is a much larger for those members accustomed to lengthy play delays.
The data for each test cell is then represented as a set of (value, count) pairs, and we can bootstrap on the counts using draws from a multinomial. Further speed gains are achieved by exploiting the Poisson approximation to the Multinomial, an established approach to bootstrapping that is also embarrassingly parallel.
As a result of the approximation, the computational cost of the bootstrapping is independent of the size of the original data set, and is set instead via the number of unique values used to approximate the original quantile function. The only step that scales with the cardinality of the original data is the compression step, which, in our implementation, requires a global sort and linear approximation.
Most any approach to data binning or compression, such as histograms or data sketches like the t-digest, can be used for fast bootstrapping on large data sets. In all cases, the resampling required by the bootstrap can be achieved via the Poisson approximation to the multinomial. As t-digests can readily be combined, the next step we are exploring is to pre-calculate t-digests for every possible combination of dimension filters that may be of interest for a given experiment, such as device type and Netflix subscription plan. When an analyst selects a particular slice of the data, the relevant t-digests can be combined and used as inputs to the fast bootstrapping algorithm.
Summary
Quantile functions, and the difference in quantile functions between test experiences, have proven to be meaningful and intuitive tools for summarizing how the distributions of streaming Quality of Experience metrics, such as play delay or average bitrate, differ between test experiences. A key advantage of quantile and delta quantile functions is that the y-axes are in the meaningful units of the metric: plots readily provide a sense of practical significance to our engineering partners. Statistical significance is provided by confidence intervals derived from fast bootstrapping achieved by reducing the cardinality of the original data.
This is just one way that we are improving streaming experimentation at Netflix, and the quantile function is a good summary of only some of our metrics. We are actively working on fast bootstrapping techniques for ratios, rates, zero-inflated observations, and other challenging metrics. Another line of our research involves fitting flexible conditional quantile functions in one or two dimensions, with the required regularization parameter estimated via cross validation and uncertainty estimated using the distributed “bag of little bootstraps.” More to follow in future posts.
We are always open to new ideas on how we can improve. Interested in learning more or contributing? Please reach out!