
Quasi Experimentation at Netflix
Quasi Experimentation at Netflix
Colin McFarland, Michael Pow, Jeremy Glick
Experimentation informs much of our decision making at Netflix. We design, analyze, and execute experiments with rigor so that we have confidence that the changes we’re making are the right ones for our members and our business. We have many years of experience running experiments in all aspects of the Netflix product, continually improving our UI, search, recommendations, video streaming, and more. Consequently, we’ve dramatically increased the maturity of the platform for A/B testing and the culture surrounding it. However, while A/B testing is a useful tool for many types of hypotheses, there are a few reasons that some hypotheses cannot be tested with an A/B test:
- It’s just not technically feasible to have individual-level randomization of users as we would in a classical A/B test
- We can randomize but expect interference between users assigned to different experiences, either through word-of-mouth, mass media, or even our own ranking systems; in short, the stable unit treatment value assumption(SUTVA) would be violated, biasing the results
For example: We may aim to better understand the interaction effects of promoting a specific title in our member in-product experience while also doing so via out-of-home marketing efforts. Are the effects additive or do they cannibalize from one another?
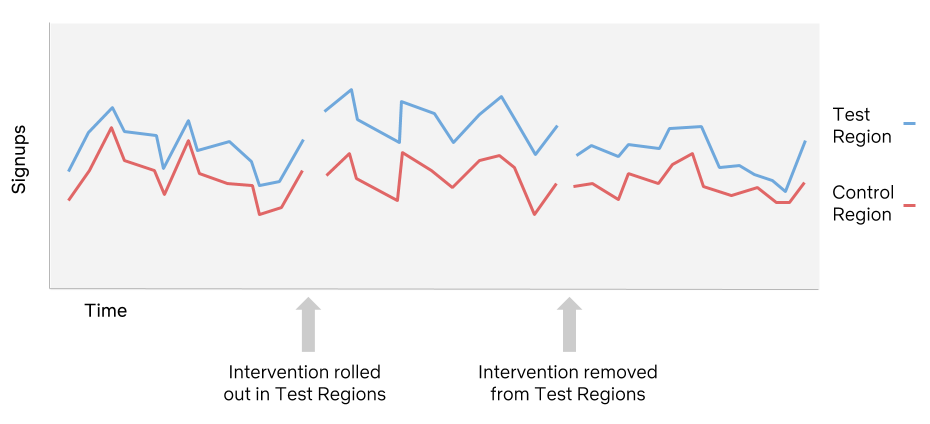
How are we to measure the impact of the change? Usually, we’d like to run a classic individual-level randomized experiment but randomizing which individuals see a billboard ad, as an example, is not possible. However, while we cannot randomly assign individuals, we can randomly choose some cities within which to show billboards and other cities to leave without.
Now we can look for changes in the test regions at-specific-times as compared to the control regions at-specific-times. Since random changes happen all the time, we need to look historically to figure out what kinds of changes are normal so we can identify the impact of our test. We call this a quasi-experiment, because groups of individuals are assigned based on location rather than assigning each individual at random, and without the individual randomization there is a much larger chance for imbalance due to skewness and heterogeneous differences. The results of a quasi-experiment won’t be as precise as an A/B, but we aspire towards a directional read on causality.
Improvements and Opportunities
How can we get more precise results from studies like the previous out-of-home marketing example? The majority of our development to date has been focused on improved test designs, not improved statistical models. Better models help most when there is rich data to support them, and for the marketing study, we know almost nothing about new members before they sign up. Instead, we can improve statistical power by increasing the number of comparisons we make. When the marketing materials are taken down, it is another opportunity to measure their impact, assuming a return to baseline signup rates.
Then we can put up out-of-home marketing in the unexposed regions, measure its impact, and take it down again for yet another measurement. In even more complex designs, we might not have any pure “control” regions at all, but if we ensure that there are always regions that are not changing at the time of intervention, we can still get a measurement of the impact.

In other situations, we might benefit more from more sophisticated models. For example, Netflix runs a content delivery network called Open Connect to stream content to our users. When we try to improve our delivery systems, we often need to make the change on an entire Open Connect server, without being able to randomize individual streams. Testing the impact of the improvements becomes another quasi-experiment, randomized at the server level. But we know much more about what is happening on the servers than we do about prospective members living in different cities. It is likely that we can make major improvements on our estimates through improved modeling as well as improved test design. For example, we could use pre-test information about which kinds of content are more or less likely to be served from each server; animation in SD is easier to stream successfully than action movies in UHD. Should we use blocking or matching designs? Or control for these differences using covariates?
Scaling Quasi Experiments
Over the past year, our marketing team has started to run a lot more quasi experiments to measure the business impact of marketing movies & TV shows across various canvases (in the member experience, in TV commercials, in out-of-home advertising, in online ads, etc.) towards the broader goal of maximizing the enjoyment of our content by our members.
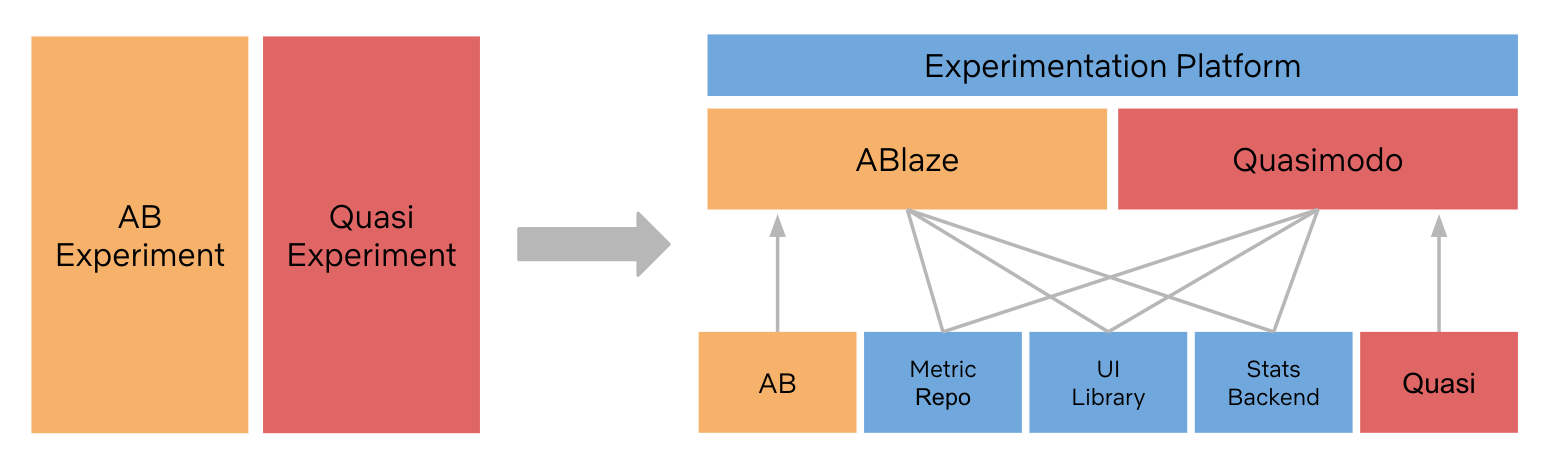
Our success with quasi experimentation in marketing at Netflix subsequently spurred interest across many other teams to scale their own quasi experiment efforts, i.e. we’ll be running a lot of quasi experiments. To scale further, we’re developing a new product, called “Quasimodo” within the wider Experimentation Platform, to automate some aspects of the scientists workflow so we can free up our scientists and run more quasi-experiments in parallel.
We have 3 key ideas shaping our focus for Quasimodo:
- Netflix teams think most about the hypothesis generation and results interpretation, without worrying about the mechanical and operational aspects of running a quasi experiment
- We leverage best practices from A/B testing and consider how best to build a holistic experimentation platform to supports the ambitious scale of our efforts at Netflix
- A cross-functional team of scientists can constantly collaborate on the best ways to design and analyze quasi experiments, since this is an emerging area. It’s crucial they can then graduate those ideas into a platform to benefit a wider audience of experimenters at Netflix

This is the first blog in a series around quasi-experiments here at Netflix. In the next blog we’ll look deeper at experimental design and analysis of quasi experiments and share some of the features we’ve developed already to help scale quasi experiments. If these are the sort of challenges you’d like to help us with, we’re hiring.