
鄰近 演算法 理論
K近鄰模型由三個基本要素組成:
距離度量;
k值的選擇;
分類決策規則
K近鄰演算法的核心在於找到例項點的鄰居。
估算不同樣本之間的相似性(SimilarityMeasurement)通常採用的方法就是計算樣本間的“距離”(Distance),相似性度量方法有:歐氏距離、餘弦夾角、曼哈頓距離、切比雪夫距離等。
歐氏距離
歐氏距離(EuclideanDistance)是最易於理解的一種距離計算方法,源於歐氏空間中的兩點之間的距離公式。

曼哈頓距離
紅線代表曼哈頓距離,綠色代表歐氏距離,也就是直線距離,而藍色和黃色代表等價的曼哈頓距離。曼哈頓距離又叫作出租車距離或城市街區距離。

切比雪夫距離

餘弦夾角

K值的選擇
從最開始的例子可以看到, 當K=3時,綠色圓點被分為了紅色三角形一類。K=5時,綠色圓點被分為藍色正方形一類。說明,k值的選擇會對k近鄰法的結果產生重大影響。
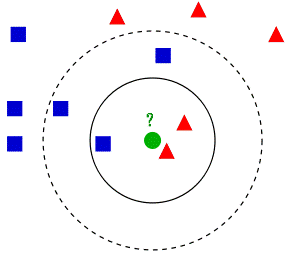
(1)k值較小,只有與輸入例項較近(相似)的訓練例項才會對預測結果起作用,預測結果會對近鄰例項點非常敏感。如果近鄰例項點恰巧是噪聲,預測就會出錯。容易發生過擬合。
(2)若k較大,與輸入例項較遠的(不相似的)訓練例項也會對預測起作用,容易使預測
出錯。k值的增大就意味著整體的模型變簡單。
(3)如果k=N,那麼無論輸入例項是什麼,都將簡單地預測它屬於在訓練例項中最多的類。這時,模型過於簡單,完全忽略訓練例項中的大量有用資訊,是不可取的。
在應用中,k值一般取較小值。通常通過經驗或交叉驗證法來選取最優的k值。
分類決策準則
投票表決:
少數服從多數,輸入例項的k個近鄰中哪個類的例項點最多,就分為該類。
加權投票法(改進):
根據距離的遠近,對K個近鄰的投票進行加權,距離越近則權重越大(比如權重為距
離的倒數)。
K近鄰演算法思想
KNN具體演算法實現過程如下:
(1)計算當前待分類例項與訓練資料集中的每個樣本例項的距離;
(2)按照距離遞增次序排序;
(3)選取與待分類例項距離最小的k個訓練例項;
(4)統計這k個例項所屬各個類別數;
(5)將統計的類別數最多的類別作為待分類的預測類別。
使用演算法的一般流程
演算法的一般流程:
(1)資料處理:準備,分析資料,進行歸一化等。
(2)訓練演算法:利用訓練樣本訓練分類器(模型)。
(3)測試演算法:利用訓練好的分類器預測測試樣本,並計算錯誤率。
(4)使用演算法:對於未知類別的樣本,預測其類別。
測試k近鄰分類器效能的流程:
(1)資料處理:歸一化等(具體情況具體對待)
(2)測試演算法:根據K近鄰分類演算法(函式classify0())預測測試樣本類別,並計算錯誤率。
(3)使用演算法:當輸入新的未知類別樣本,利用演算法預測結果。
如何測試分類器效能
獲取分類器以後,需測試分類器的效果,可以通過檢測分類器給出的答案是否符合我們預期的結果。比如,可以使用已知答案的資料(已知類別標籤),當然答案不能告訴分類器,檢測由分類器給出的結果(預測類別)是否與資料的真實結果(真實類別)一致。
一個分類器的效能的好壞最簡單的評價方法就是,計算其分類錯誤率。錯誤率即為測試資料中分類錯誤的資料個數除以測試資料總數。
錯誤率越低分類器的分類效能越好,錯誤率越高,分類效能就越差。
如何測試分類器效能
通常提供的資料集沒有區分訓練樣本和測試樣本。
如下為簡單交叉驗證:
從資料集中選取90%作為訓練樣本來訓練分類器;而使用剩下的10%的樣本資料來測試分類器。
其中10%的測試資料應該是從所提供的資料集中隨機抽取的,可以多次隨機抽取取平均的結果作為最終的檢測分類器的錯誤率。