
機器學習演算法及程式碼實現--K鄰近演算法
阿新 • • 發佈:2018-12-27
機器學習演算法及程式碼實現–K鄰近演算法
1、K鄰近演算法
將標註好類別的訓練樣本對映到X(選取的特徵數)維的座標系之中,同樣將測試樣本對映到X維的座標系之中,選取距離該測試樣本歐氏距離(兩點間距離公式)最近的k個訓練樣本,其中哪個訓練樣本類別佔比最大,我們就認為它是該測試樣本所屬的類別。

2、演算法步驟:
1)為了判斷未知例項的類別,以所有已知類別的例項作為參照
2)選擇引數K
3)計算未知例項與所有已知例項的距離
4)選擇最近K個已知例項
5)根據少數服從多數的投票法則(majority-voting),讓未知例項歸類為K個最鄰近樣本中最多數的類別
3、距離
Euclidean Distance 定義
其他距離衡量:餘弦值(cos), 相關度 (correlation), 曼哈頓距離 (Manhattan distance)
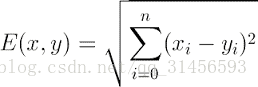
其他距離衡量:餘弦值(cos), 相關度 (correlation), 曼哈頓距離 (Manhattan distance)
4、例子
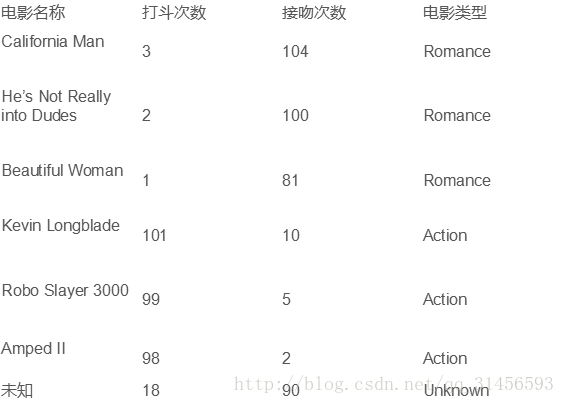
將其對映到2維空間
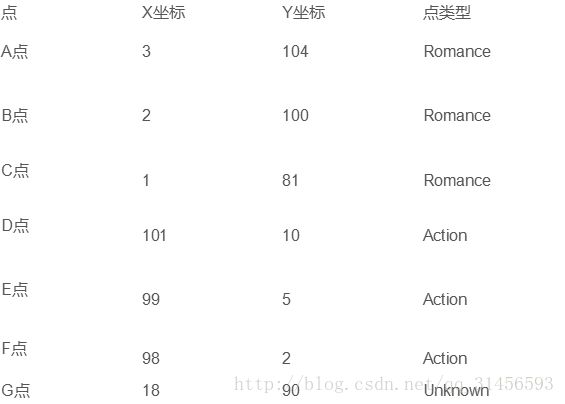
求距G點最近的k點中哪一類點最多,就可以預測G點型別。
5、演算法優缺點:
優點
1)簡單
2)易於理解
3)容易實現
4)通過對K的選擇可具備丟噪音資料的健壯性
缺點
1)需要大量空間儲存所有已知例項 2)演算法複雜度高(需要比較所有已知例項與要分類的例項) 3) 當其樣本分佈不平衡時,比如其中一類樣本過大(例項數量過多)佔主導的時候,新的未知例項容易被歸類為這個主導樣本,因為這類樣本例項的數量過大,但這個新的未知例項實際並木接近目標樣本 
6、 改進版本
考慮距離,根據距離加上權重
比如: 1/d (d: 距離)
程式碼
# -*- coding: utf-8 -*-
from sklearn import neighbors
from sklearn import datasets
# 呼叫knn分類器
knn = neighbors.KNeighborsClassifier()
# 匯入資料集
iris = datasets.load_iris()
print iris
# 訓練
knn.fit(iris.data, iris.target)
# 預測
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]]