
文字切割演算法-基於投影的切割
前言:
文字識別的關鍵之所在就是單個文字的切割,切割的準確度極大的影響了文字識別的正確率。本文基於傳統橫縱投影的思想對文字進行切割,使用java與python實現了本演算法。
基本思路:
1、橫向掃描,切出每一行
2、對每一行進行縱向掃描,得出每一個字
經過對原始影象的相關處理,得出如下二值圖(僅有黑白色)。這裡的‘相關處理’是很複雜的,涉及影象學相關知識,我是通過opencv進行處理的。本文主要對切割演算法進行討論,圖片處理部分望讀者自行了解。

(待切割圖)
橫向掃描
橫向掃描就是依次從左往右統計,得出這一行黑色點的數量。比如上圖尺寸為1200*430,經過橫向掃描就可以得到430個數值,這個數值表示在1200個點中黑色點的數量。我們把這430個數直觀的展示出來,可以得到下圖:
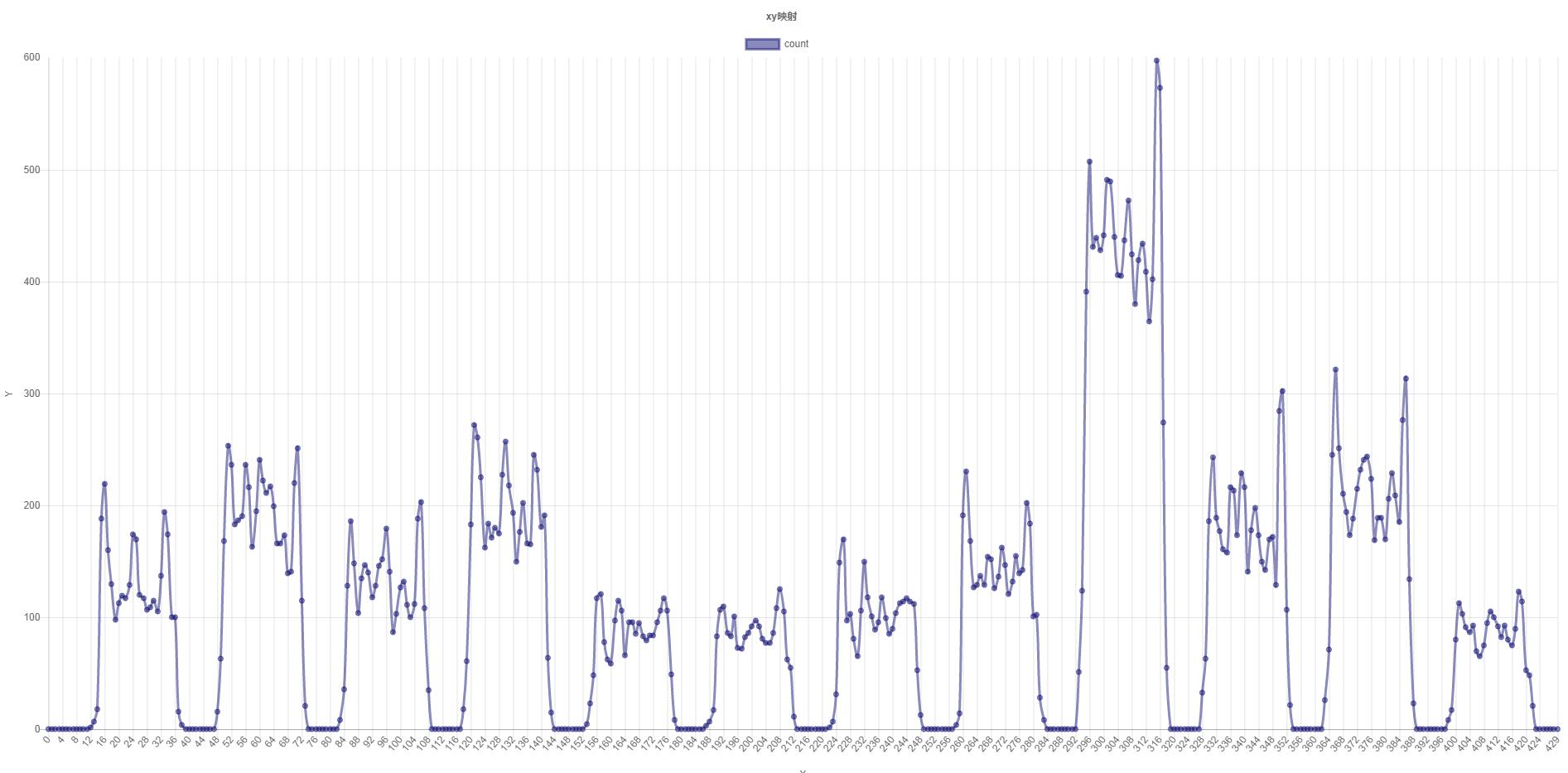
(橫向切割統計圖,x:行數 y:黑色點數)
在上圖中,y軸數值不為0的區域就是文字存在的地方,為0的區域就是每行之間相隔的距離。我們通過如下規則就可以找出每一行文字的起始點和終止點,以定位該行文字區域:1、如果前一個數為0,則記錄第一個不為0的座標;2、如果前一個數不為0,則記錄第一個為0的座標。形象的說就是從出現第一個非空白行(開始有字)到出現第一個空白行(沒有字)這段區域就是文字存在的區域。

(橫向切割說明圖)
縱向掃描
縱向掃描與橫向掃描同理。針對橫向掃描切割出的區域,進行縱向掃描,得出每一個字。
我們對橫向掃描得出的第一行進行縱向掃描,可以得到1200個數值,如下圖:
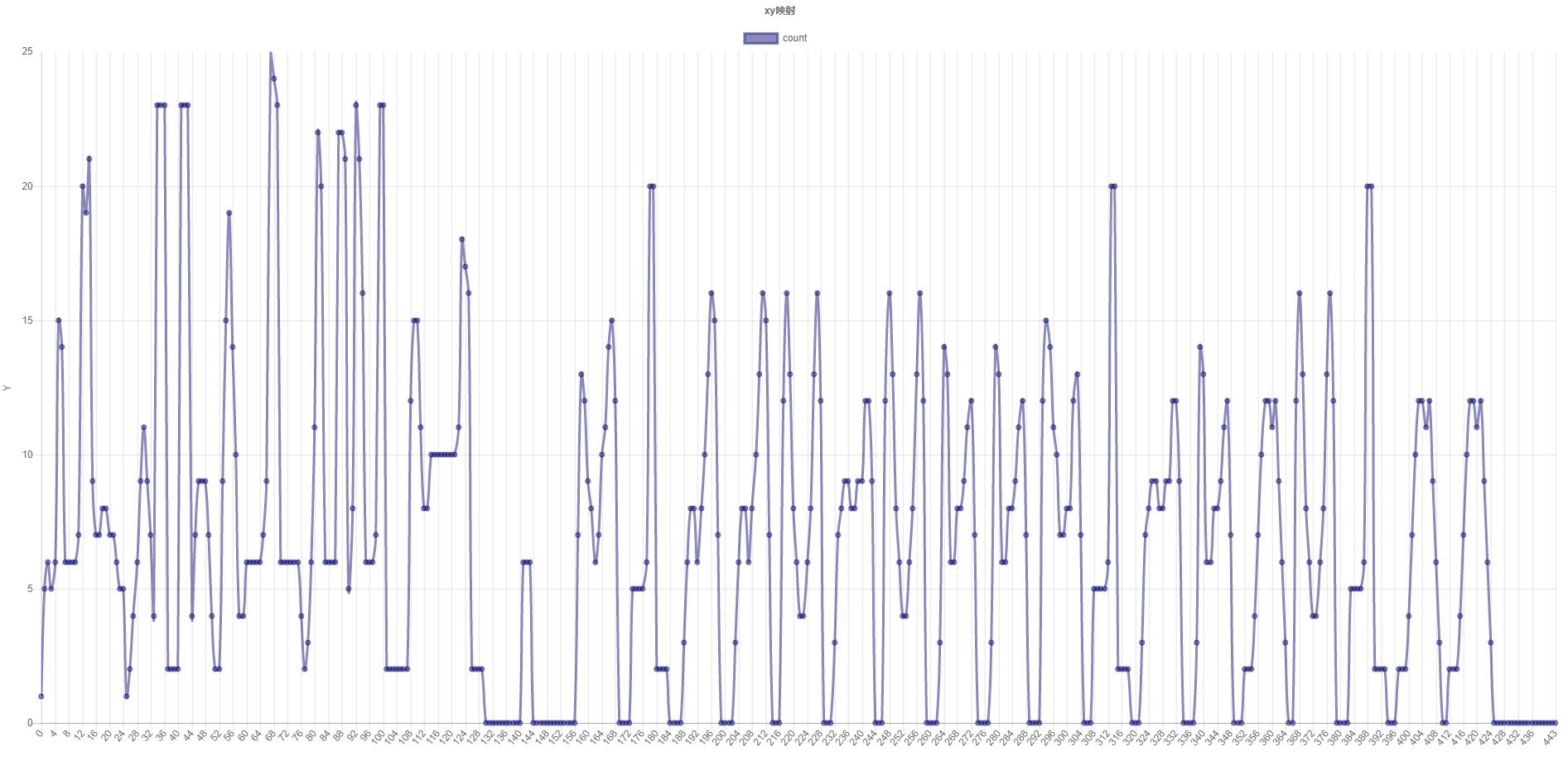
(橫向切割統計圖,x:行數 y:黑色點數 省略了部分割槽域)
再運用橫向掃描的思維,對縱向掃描的資料進行切割,就可以得出單個文字了。
切割結果

(切割結果)
可以看到切割結果有些不理想,會存在很多連在一起的字。
結果分析
演算法對於數字切割十分理想,但是對於漢字會存在切割失敗的現象。分析發現部分漢字兩兩之間沒有空白區域,是連在一起的,所以縱向掃描演算法就無法準確切割。如下圖所示:
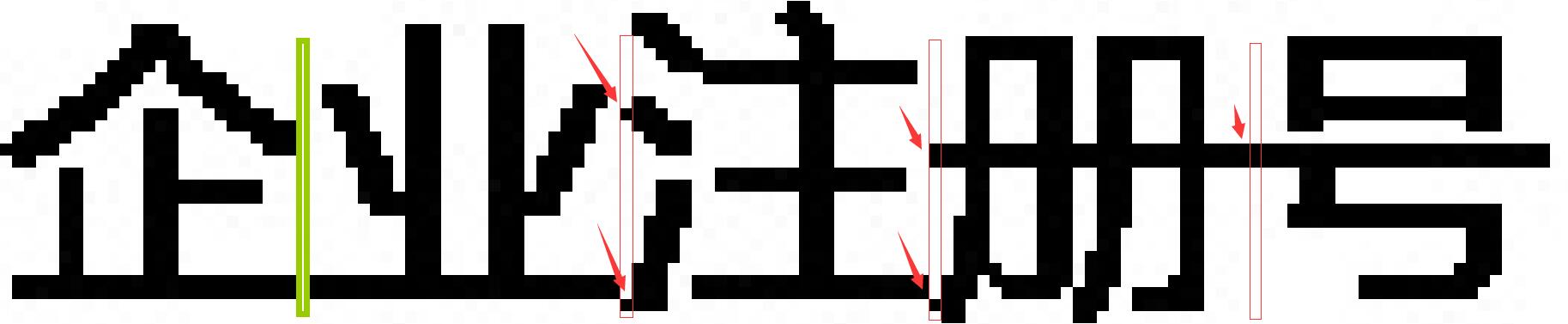
所以直接使用投影進行切割,這種方法是不可行的。我們需要對該演算法進行優化,以便得出更為準確的結果。優化演算法敬請期待下篇(文字切割演算法-投影切割優化)。
專案原始碼:我的github(https://github.com/printlin/tmOcr/tree/master)