
Merkle Tree演算法詳解
Merkle Tree是Dynamo中用來同步資料一致性的演算法,Merkle Tree是基於資料HASH構建的一個樹。它具有以下幾個特點:
1、資料結構是一個樹,可以是二叉樹,也可以是多叉樹(本BLOG以二叉樹來分析)
2、Merkle Tree的葉子節點的value是資料集合的單元資料或者單元資料HASH。
3、Merke Tree非葉子節點value是其所有子節點value的HASH值。
為了更好的理解,我們假設有A和B兩臺機器,A需要與B相同目錄下有8個檔案,檔案分別是f1 f2 f3 ....f8。這個時候我們就可以通過Merkle Tree來進行快速比較。假設我們在檔案建立的時候每個機器都構建了一個Merkle Tree。具體如下圖:
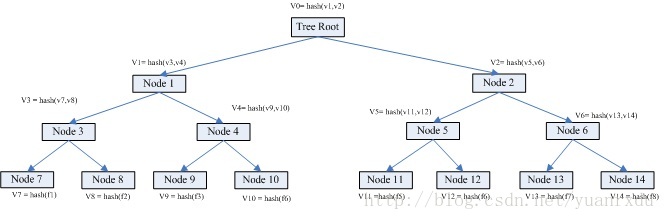
從上圖可得知,葉子節點node7的value = hash(f1),是f1檔案的HASH;而其父親節點node3的value = hash(v7, v8),也就是其子節點node7 node8的值得HASH。就是這樣表示一個層級運算關係。root節點的value其實是所有葉子節點的value的唯一特徵。
假如A上的檔案5與B上的不一樣。我們怎麼通過兩個機器的merkle treee資訊找到不相同的檔案? 這個比較檢索過程如下:
1、首先比較v0是否相同,如果不同,檢索其孩子node1和node2.
2、v1 相同,v2不同。檢索node2的孩子node5 node6;
3、v5不同,v6相同,檢索比較node5的孩子node 11 和node 12
4、v11不同,v12相同。node 11為葉子節點,獲取其目錄資訊。
5、檢索比較完畢。
以上過程的理論複雜度是Log(N)。實際過程是大於這個複雜度的,因為不同value的節點需要每個子節點進行比較。過程描述圖如下:
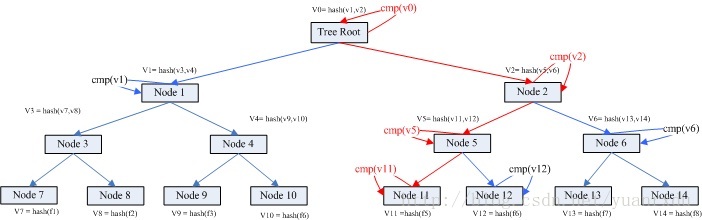
從上圖可以得知真個過程可以很快的找到對應的不相同的檔案。
如果A機器的目錄下增加了一個檔案f9。整個merkle tree就會變成這樣的:
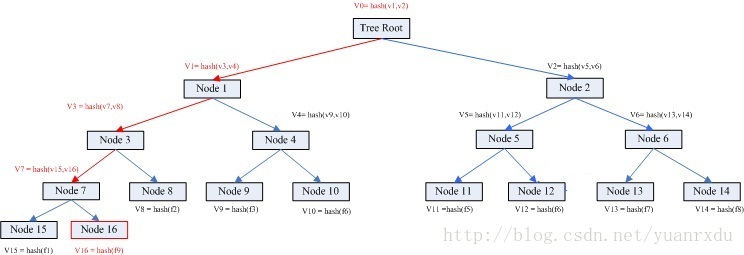
其中紅色字型是需要進行運算的步驟,整個過程是從葉子節點發起的,直接回溯到root節點為止。
假如目錄下的f1被刪除。整樹的運算變化圖如下:

紅色字型是需要進行的運算。
從上可以得知,merkle tree在大資料集合校驗可以提高校驗的效率的。從Dynamo論文中可以看出,大量使用merkle tree來同步分散式節點的檔案和寫操作,尤其是在服務節點異常後的情況,具體細節可以參看Dynamo論文中的描述。