
Understanding LSTM Networks(LSTM的網路結構)
Recurrent Neural Networks
人類不是每時每刻都從頭開始思考的。當你讀這篇文章的時候,你理解每個單詞是基於你對以前單詞的理解。你不會把所有的東西都扔掉,然後從頭開始思考。你的思想有毅力。傳統的神經網路無法做到這一點,這似乎是一個主要的缺點。
例如,假設你想對電影中每一點發生的事件進行分類。目前尚不清楚傳統的神經網路如何利用其對電影中先前事件的推理來告知後來的事件。遞迴神經網路解決了這個問題。它們是帶有迴圈的網路,允許資訊持續存在。


迴圈神經網路有迴圈
在上面的圖中,神經網路a塊,檢視一些輸入xt並輸出一個值ht。迴圈允許資訊從網路的一個步驟傳遞到下一個步驟。這些迴圈使得迴圈神經網路看起來有點神祕。然而,如果你再仔細想想,就會發現它們與正常的神經網路並沒有多大區別。遞迴神經網路可以看作是同一網路的多個副本,每個副本都將訊息傳遞給後繼網路。考慮一下如果我們展開迴圈會發生什麼:
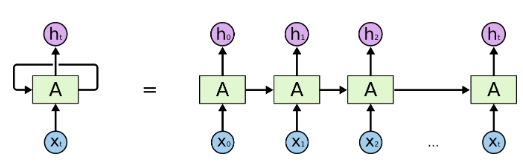
展開遞迴神經網路
這種鏈的性質揭示了迴圈神經網路與序列和列表密切相關。它們是神經網路的自然結構,用來處理這些資料。它們當然是有用的!在過去的幾年裡,將RNNs應用到各種問題上取得了令人難以置信的成功:語音識別、語言建模、翻譯、圖片字幕等等。
我將在Andrej Karpathy的一篇優秀的部落格文章《迴圈神經網路的不合理有效性》中留下對RNNs所能取得的驚人成就的討論。但它們真的很神奇。這些成功的關鍵是LSTMs的使用,LSTMs是一種非常特殊的迴圈神經網路,在很多工中都比標準版本好得多。幾乎所有基於遞迴神經網路的令人興奮的結果都是通過它們得到的。本文將探討的就是這些LSTMs。
The Problem of Long-Term Dependencies
RNNs的吸引力之一是,他們可能能夠將以前的資訊與當前的任務聯絡起來,比如使用以前的視訊框架,這可能會讓人們瞭解當前框架。如果RNNs能夠做到這一點,它們將非常有用。但他們能嗎?視情況而定。有時,我們只需要檢視最近的資訊就可以完成當前的任務。例如,考慮一個語言模型,它試圖根據前一個詞預測下一個詞。如果我們試圖預測雲中的最後一個詞是天空,我們不需要更多的上下文,很明顯下一個詞是天空。在這種情況下,相關資訊與所需資訊之間的差距很小,RNNs可以學習使用過去的資訊。

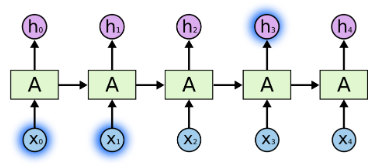
但也有一些情況我們需要更多的背景。“我在法國長大,法語說得很流利”。最近的資訊表明,下一個單詞可能是一種語言的名字,但如果我們想縮小語言的範圍,我們需要從更遠的地方來了解法國的背景。相關資訊與需要變得非常大的點之間的差距是完全可能的。
不幸的是,隨著差距的擴大,RNNs無法學習連線資訊。

從理論上講,RNNs完全有能力處理這種長期依賴關係。一個人可以仔細地為他們挑選引數來解決這種形式的玩具問題。遺憾的是,在實踐中,RNNs似乎無法學習它們。Hochreiter (1991) [德國]和Bengio等人(1994)對這個問題進行了深入的研究,他們發現了一些非常基本的原因,為什麼會有困難。
謝天謝地,LSTMs沒有這個問題。
LSTM Networks
長短時記憶網路通常被稱為LSTMs,是一種特殊的RNN,能夠學習長期依賴關係。它們是Hochreiter & Schmidhuber公司(1997)推出的,在後續的工作中被很多人提煉和推廣。它們在各種各樣的問題上都能很好地工作,現在被廣泛使用。
LSTMs被明確設計來避免長期依賴問題。長時間記住資訊實際上是他們的預設行為,而不是他們努力學習的東西!
所有的遞迴神經網路都有一個神經網路的重複模組鏈。在標準的RNNs中,這個重複模組將有一個非常簡單的結構,比如一個tanh層。


標準RNN中的重複模組包含一個單層
LSTMs也有這種鏈狀結構,但重複模組有不同的結構。不是單一的神經網路層,而是四層,以一種非常特殊的方式相互作用。
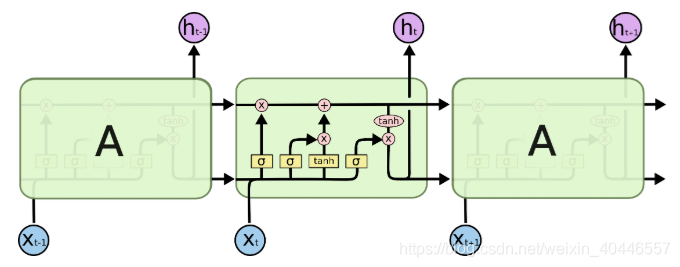
LSTM中的重複模組包含四個互動層
不要擔心正在發生的事情的細節。我們將在後面逐步介紹LSTM圖。現在,讓我們試著熟悉一下我們將要使用的符號。


在上面的圖中,每一行都攜帶一個完整的向量,從一個節點的輸出到其他節點的輸入。粉色的圓圈表示點對點的操作,比如向量加法,黃色的方框表示學習過的神經網路層。行合併表示連線,而行分叉表示內容被複制,副本被複制到不同的位置。
The Core Idea Behind LSTMs
LSTMs的關鍵是單元格狀態,即貫穿圖表頂部的水平線。細胞狀態有點像傳送帶。它沿著整個鏈直線向下,只有一些微小的線性相互作用。資訊很容易在不改變的情況下沿著它流動。

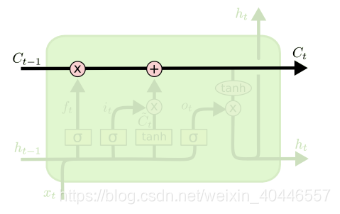
LSTM確實有能力刪除或新增資訊到細胞狀態,被稱為門的結構小心地調節。門是一種可選擇地讓資訊通過的方式。它們由一個s型神經網路層和一個點乘運算組成。

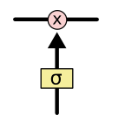
sigmoid層輸出0到1之間的數字,描述每個元件應該允許多少流量。0的值表示什麼都不通過,而1的值表示什麼都通過!LSTM有三個這樣的門,用來保護和控制細胞狀態。
Step-by-Step LSTM Walk Through
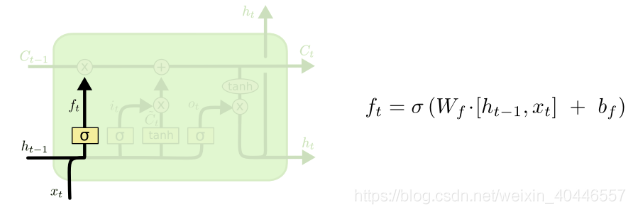
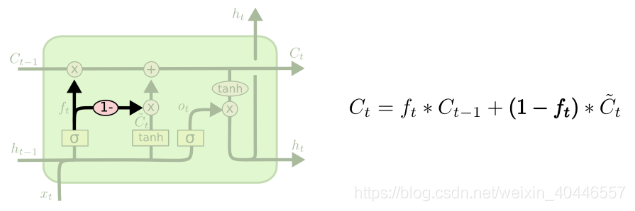
LSTM的第一步是決定從細胞狀態中丟棄什麼資訊。這個決定是由一個稱為“忘記門”(遺忘門)層的sigmoid層做出的。它檢視ht-1和xt,併為細胞狀態Ct-1中的每個數字輸出一個介於0和1之間的數字。1表示完全保留這個,0表示完全去掉這個。
讓我們回到我們的語言模型的例子,它試圖根據前面的例子預測下一個單詞。在這種情況下,細胞狀態可能包括當前主題的性別,以便正確使用代詞。當我們看到一個新的主題,我們想忘記舊主題的性別。

下一步是決定在單元格狀態下儲存哪些新資訊。這有兩部分。首先,一個稱為輸入門層的sigmoid層決定我們要更新哪些值。接下來,tanh層建立一個新的候選值向量,![]() ,可以新增到狀態中。
,可以新增到狀態中。
在接下來的步驟中,我們將結合這兩者來建立一個狀態更新。在我們的語言模型的例子中,我們希望在細胞狀態中新增新受試者的性別,以取代我們忘記的舊受試者。


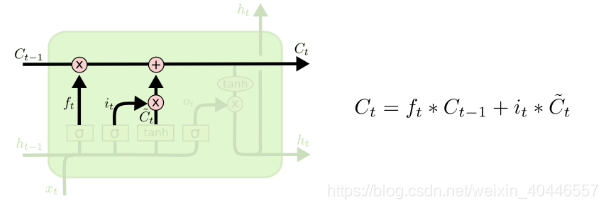
現在是時候更新舊的細胞狀態,Ct-1,到新的細胞狀態Ct。前面的步驟已經決定了要做什麼,我們只需要實際去做。我們把舊狀態乘以ft,忘記了之前決定要忘記的事情。然後加上![]() 。這是新的候選值,根據我們決定更新每個狀態值的程度進行縮放。
。這是新的候選值,根據我們決定更新每個狀態值的程度進行縮放。
在語言模型中,這是我們刪除舊主題的性別資訊並新增新資訊的地方,正如我們在前面的步驟中所決定的那樣。

最後,我們需要決定輸出什麼。此輸出將基於單元格狀態,但將是過濾後的版本。首先,我們執行一個sigmoid層,它決定輸出單元狀態的哪些部分。然後,我們將單元格狀態通過tanh(將值推到-1到1之間)乘以sigmoid門的輸出,這樣我們只輸出我們決定輸出的部分。
對於語言模型示例,由於它只是看到一個主語,所以它可能希望輸出與動詞相關的資訊,以防接下來發生什麼。例如,它可能輸出主語是單數還是複數,這樣我們就能知道一個動詞應該以什麼形式出現,如果接下來是什麼形式的話。


Variants on Long Short Term Memory
到目前為止我所描述的是一個非常普通的LSTM。但並非所有LSTMs都與上述相同。事實上,似乎幾乎每一篇涉及LSTMs的論文都使用了稍有不同的版本。
這些差別很小,但有一些值得一提。一種流行的LSTM變種,由 Gers & Schmidhuber (2000)加入了窺孔連線。這意味著我們讓gate層觀察cell狀態。

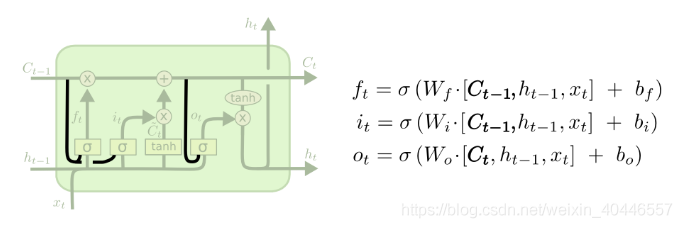
上面的圖表在所有的門上都加了窺視孔,但是許多論文會給出一些窺視孔而不是其他的。另一種變體是使用耦合遺忘和輸入門。我們不是單獨決定忘記什麼和新增什麼新資訊,而是一起做這些決定。我們只會忘記在它的位置輸入什麼東西。當我們忘記一些舊的東西時,我們只會給狀態輸入新的值。

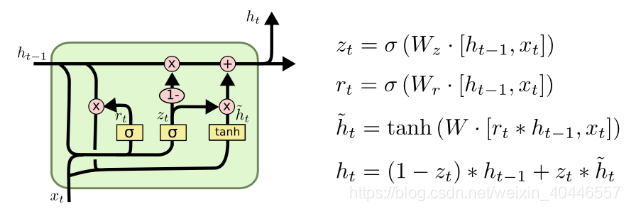
LSTM的一個稍微顯著的變化是門控迴圈單元,或GRU,由Cho等人(2014)介紹。它將忘記和輸入門合併到一個單獨的更新門中。它還合併了單元格狀態和隱藏狀態,並進行了一些其他更改。最終的模型比標準的LSTM模型更簡單,並且越來越流行。
這些只是最值得注意的LSTM變體中的幾個。還有很多其他的,如Yao等人(2015)的深度門控RNNs。還有一些完全不同的方法來處理長期依賴關係,比如Koutnik等人(2014)的Clockwork RNNs。
這些變體中哪一種最好?差異重要嗎?Greff等人(2015)對流行的變體做了一個很好的比較,發現它們都差不多。Jozefowicz等人(2015)測試了一萬多個RNN架構,發現其中一些在某些任務上比LSTMs更好。
Conclusion
早些時候,我提到了人們用RNNs取得的顯著成果。基本上所有這些都是通過LSTMs實現的。在大多數任務中,它們確實工作得更好!LSTMs被寫成一組方程,看起來很嚇人。希望在這篇文章中,一步一步地瞭解它們能讓他們更容易接近。
LSTMs是我們可以通過RNNs完成的一大步。人們自然會想:是否還有一大步?研究人員普遍認為:是的!還有下一步,就是注意了!其思想是讓RNN的每一步都從一些更大的資訊集合中挑選資訊。例如,如果使用RNN建立描述影象的標題,它可能會為輸出的每個單詞選擇影象的一部分。
事實上,Xu等人(2015)正是這麼做的,如果你想探索注意力,這可能是一個有趣的起點!使用注意力有很多令人興奮的結果,而且似乎還有很多即將到來,注意力並不是RNN研究中唯一令人興奮的線索。例如,Kalchbrenner等(2015)的網格LSTMs似乎非常有前途。在生成模型中使用RNNs,如Gregor, et al. (2015), Chung, et al.(2015),或Bayer &Osendorfer(2015)也很有趣。過去的幾年對於迴圈神經網路來說是一個激動人心的時期,而接下來的幾年將會更加激動人心!
參考連結:http://colah.github.io/posts/2015-08-Understanding-LSTMs/