
理解支援向量機(四)LibSVM工具包的使用
LibSVM是一款簡單易用的支援向量機工具包,包含了C和Java的開發原始碼。大家可以訪問其官網進行了解和下載相關檔案。
這裡以其官網的第一個資料集a1a 為例,練習使用多項式核和徑向基核來對資料集進行分類。
1、準備工作
由於從官網下的最新的2015.12月釋出的libsvm-3.21版本中已生成的exe檔案不支援Windows32位系統,所以使用的之前的一版libsvm-3.20。將其下下來開啟,裡面包含了以下檔案:
其中data裡面放的是LibSVM分享的資料集a1a;
gnuplot是一個影象繪畫工具,可以將資料視覺化。直接點選進行安裝,路徑可以自己選擇,本例中安裝路徑為F:\Program Files\gnuplot。
libsvm-3.20是一個已開發好的整合工具包,我們拿來直接用。將libsvm-3.20壓縮包解壓,路徑可以自己選擇,本例中解壓路徑為F:\Program Files\libsvm-3.20。
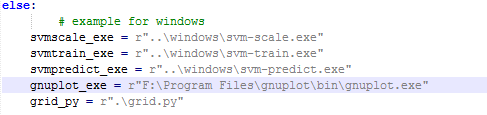
開啟tools資料夾,然後分別開啟easy.py和grid.py,將easy.py中出現在else語句中的gnuplot_exe和 grid.py中self.gnuplot_pathname修改為gnuplot.exe所在路徑,如下:

現在還差一個工具,就是python。沒有安裝python的可以從python官網 下載安裝。路徑可以自己選擇,本例中安裝路徑為F:\Program Files\Python。
以上幾步完成後,準備工作就結束了。
2、LibSVM的使用
0. 如果資料集較小的話,可以直接在libsvm-3.20中的tools 資料夾下使用命令:python easy.py training_file [testing_file]。否則處理過程如下:
1. 使用網格搜尋grid.py訓練出最優引數懲罰因子C和引數g,g也就是核函式公式中的
首先將data中的兩個資料集檔案複製到剛解壓的libsvm-3.20中的tools 資料夾下,然後開啟cmd命令列,通過cd進入到tools資料夾下,輸入如下命令,如圖:
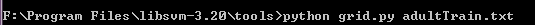
按回車後,程式開始執行,執行結束後,會出現如下結果:
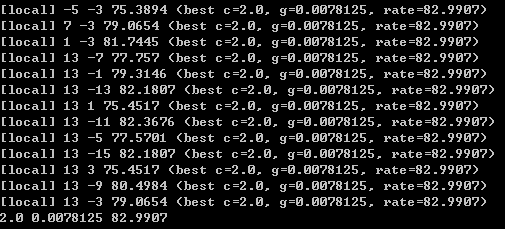
最後一行三個數字分別表示,尋找到的最優引數C=2.0,g=0.0078125,準確率=82.9907。
同時會在tools資料夾下生成一個gnuplot畫出結果圖片,如下:
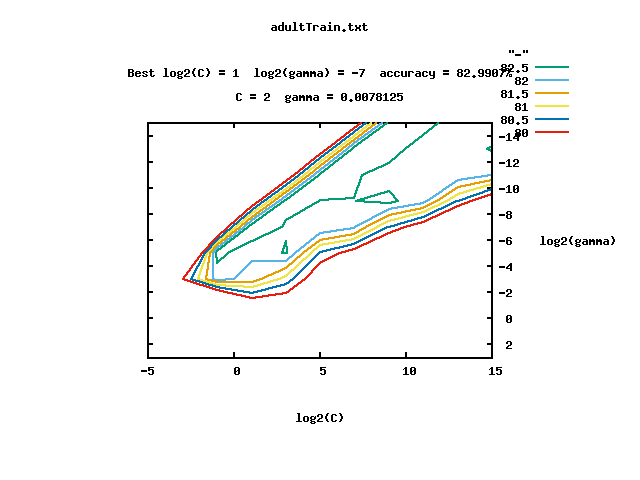
可以看到,gnuplot是對資料的視覺化表示。
2 訓練模型
在獲得最優引數後,我們就可以對訓練資料集進行訓練,來獲得訓練模型,步驟如下:
首先從cmd命令列中進入libsvm-3.20中的windows資料夾,可以看到資料夾中有svm-toy.exe、svm-scale.exe、svm-train.exe、svm-predict.exe四個可執行檔案,其中:
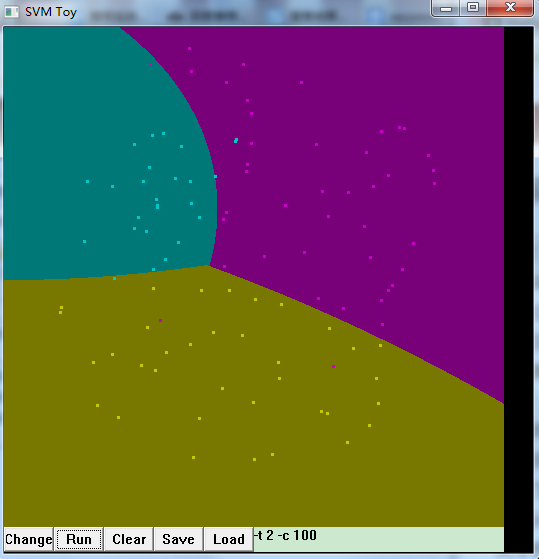
svm-toy.exe是一個視覺化應用程式,顯示了對平面中資料點的分類。有change、run、clear、save、load及引數設定框,預設最大分類數為3,大家可以點點看,效果如下:
svm-scale.exe是對輸入的資料特徵進行歸一化縮放,從而避免某些過大或過小特徵值對分類效果的影響。使用方式如下:
svm-scale [options] data_filename,其中options列表有以下幾種:
-l lower : x縮放最小值,預設為-1
-u upper : x縮放最大值,預設為1
-y y_lower y_upper : y scaling limits (default: no y scaling)
-s save_filename : save scaling parameters to save_filename
-r restore_filename : restore scaling parameters from restore_filename
svm-train.exe對訓練集訓練,產生訓練模型。使用方式如下:
svm-train [options] training_set_file [model_file],其中常用options列表有以下幾種:
-s svm_type : SVM型別 (預設0)
0 – C-SVC (多類分類器)
1 – nu-SVC (多類分類器)
2 – one-class SVM
3 – epsilon-SVR (迴歸)
4 – nu-SVR (迴歸)
-t kernel_type : 核函式型別 (預設 2)
0 – 線性核:
1 – 多項式核:
2 – 徑向基核:
3 – sigmoid核:
4 – precomputed kernel (kernel values in training_set_file)
-d degree : 多項式核最高項次數 (default 3)
-g gamma : 核函式中
-r coef0 : 多項式核與sigmoid核中的引數(default 0)
-c cost : 設定C-SVC, e -SVR和v-SVR的損失函式(default 1)
svm-predict.exe利用測試集和生成的訓練模型而得到預測模型,使用方式如下:
svm-predict [options] test_file model_file output_file,其中options列表有:
-b probability_estimates: 是否預測概率估計,用0或1表示(預設0);對於for one-class SVM ,只有0可選。
介紹完這幾個可執行檔案後,下面我們就要用它們來訓練和預測模型。
1.對於a1a資料集,特徵值為0或者1,故不需要使用svm-scale.exe來縮放資料,若有資料集的特徵值差異較大,應首先使用svm-scale.exe進行資料縮放。
2.命令列進入windows資料夾,輸入命令:svm-train.exe -c 2.0 -g 0.0078125 ../tools/adultTrain.txt ../tools/adultTrain.model,生成訓練模型檔案adultTrain.model,演示如下:
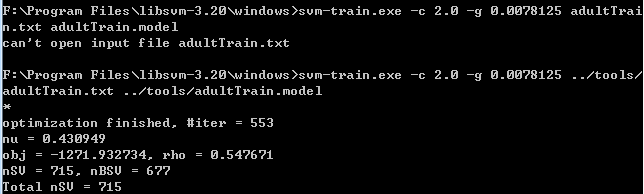
其中,iter表示迭代計算次數;
nu即核函式中的
obj為二次規劃求解的最小值;
rho為偏置b;
nSV為標準支援向量個數,即滿足0<
nBSV為邊界上的支援向量個數,即滿足
Total nSV為支援向量總個數。
3.輸入命令:svm-predict.exe ../tools/adultTest.t ../tools/adultTrain.model ../tools/audltPredict.model,利用測試集和訓練模型檔案獲得預測模型檔案,並得到模型在測試集上的分類準確率,顏色如下:

4.作為對比,同時訓練了多項式核函式(引數最優)和徑向基核函式(未引數最優),結果分別如下:


三者比較可知,選擇了引數最優的徑向基核在該資料集上的分類效果最好,準確率為84.0225。