
邏輯斯諦迴歸--Python程式碼實現
本文在原文的基礎上增加僅一些個人理解
前言
上一篇文章中,已經說明在邏輯斯諦迴歸模型中就是利用極大似然估計,來求出引數,然後根據輸入的,利用公式來預測
在本文中,當求出後,不再利用以及兩個公式分別計算出以及的概率,而是用一個函式來計算概率,當計算出的值接近於1時,也即是,當計算出的值接近於0時,也即是
正文
生成資料
本文中將使用模擬資料,我們可以從多維正態分佈中取樣
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(12)
num_observations = 5000
x1 = np.random.multivariate_normal([0, 0], [[1, .75],[.75, 1]], num_observations)
x2 = np.random.multivariate_normal([1, 4], [[1, .75],[.75, 1]], num_observations)
simulated_separableish_features = np.vstack((x1, x2)).astype(np.float32)
simulated_labels = np.hstack((np.zeros(num_observations),
np.ones(num_observations))) 正態分佈
可以看出,對於一個正態分佈有兩個重要的引數期望和方差
[1] 引數含義
觀測生成的資料
plt.figure(figsize=(12,8))
plt.scatter(simulated_separableish_features[:, 0], simulated_separableish_features[:, 1],
c = simulated_labels, alpha = .4)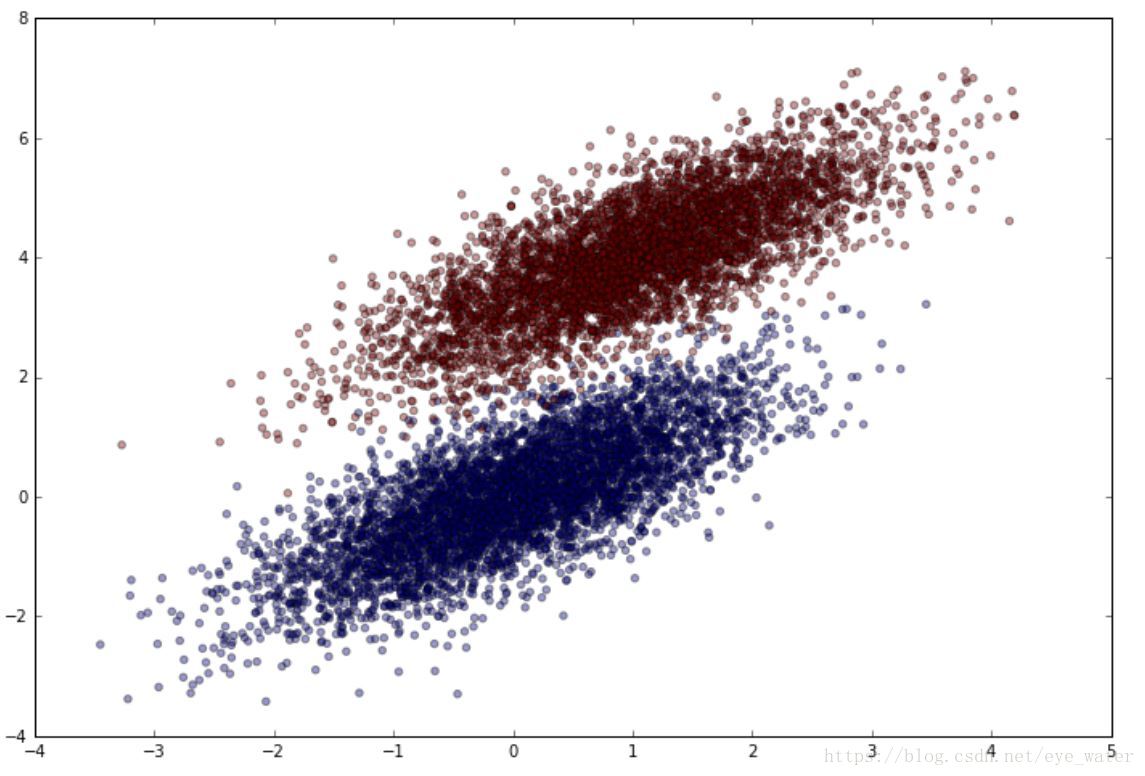
選擇預測函式
一般的線性模型都會使用聯絡函式將線性模型與預測值聯絡起來,在邏輯斯諦迴歸模型中,使用函式作為聯絡函式
def sigmoid(scores):
return 1 / (1 + np.exp(-scores))極大似然估計
為了最大化似然函式,我們需要似然函式的公式以及似然函式的梯度。幸運的是, 對於二分類問題來說似然函式可以轉變為對數似然函式。在極大似然估計中,我們可以不用影響權重引數評估來達到我們的目的,因為對數變換是單調的。
對數似然計算
可以把對數似然函式看作所有訓練資料的和
公式:
是目標分類(0或1),是輸入資料,是權重向量
梯度計算
我們需要一個計算對數似然函式的公式,可以對上面的公式進行求導並再形成一個矩陣
建立邏輯斯諦迴歸函式
def logistic_regression(features, target, num_steps, learning_rate, add_intercept = False):
if add_intercept:
intercept = np.ones((features.shape[0], 1))
features = np.hstack((intercept, features))
weights = np.zeros(features.shape[1])
for step in xrange(num_steps):
scores = np.dot(features, weights)
predictions = sigmoid(scores)
# Update weights with gradient
output_error_signal = target - predictions
gradient = np.dot(features.T, output_error_signal)
weights += learning_rate * gradient
# Print log-likelihood every so often
if step % 10000 == 0:
print log_likelihood(features, target, weights)
return weights關於for迴圈
可以與梯度下降法做一個比較

可以看到for迴圈裡面的步驟與梯度下降法大致一樣
不同的是,相比於梯度下降法,for迴圈中我們用定值learning_rate來代替,並且我們並沒有判定當函式增長幅度十分小時是否應當退出迴圈
執行Logistic Regression
weights = logistic_regression(simulated_separableish_features, simulated_labels,
num_steps = 300000, learning_rate = 5e-5, add_intercept=True)輸出
-4346.26477915
-148.706722768
-142.964936231
-141.545303072
-141.060319659
-140.870315859
-140.790259128
...
-140.725421355與Sk-Learn 中的 LogisticRegression 做比較
我們並不知道我們自己的演算法計算出的權重值是否正確,但是我們知道Sk-Learn 中的 LogisticRegression演算法是正確的,因此把我們自己計算出的權重值與Sk-Learn 中的 LogisticRegression計算出的權重值進行比較即可
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(fit_intercept=True, C = 1e15)
clf.fit(simulated_separableish_features, simulated_labels)
print(clf.intercept_, clf.coef_)
print(weights)輸出
[-13.99400797] [[-5.02712572 8.23286799]]
[-14.09225541 -5.05899648 8.28955762]看起來結果不錯,但是如果我們進行更多次的迴圈以及給出一個足夠小的learning_rate我們會得到一個更好的結果
為什麼?
當我們極大化對數似然函式時,我們用的是梯度上升法(和梯度下降法差不多,差別僅僅是一個負號)
梯度下降法有一個性質,當目標函式是凸函式時,梯度下降法的解是最優解
梯度上升法和梯度下降法僅僅相差一個負號,因此可以得出梯度上升法的性質:當目標函式是凹函式時,梯度下降法的解是最優解
[2]
精確度
最後,我們要利用求出來的權重值