決策樹與R語言(RPART)
阿新 • • 發佈:2019-01-04
關於決策樹理論方面的介紹,李航的《統計機器學習》第五章有很好的講解。
傳統的ID3和C4.5一般用於分類問題,其中ID3使用資訊增益進行特徵選擇,即遞迴的選擇分類能力最強的特徵對資料進行分割,C4.5唯一不同的是使用資訊增益比進行特徵選擇。
特徵A對訓練資料D的資訊增益g(D, A) = 集合D的經驗熵H(D) - 特徵A給定情況下D的經驗條件熵H(D|A)
特徵A對訓練資料D的資訊增益比r(D, A) = g(D, A) / H(D)
而CART(分類與迴歸)模型既可以用於分類、也可以用於迴歸,對於迴歸樹(最小二乘迴歸樹生成演算法),需要尋找最優切分變數和最優切分點,對於分類樹(CART生成演算法),使用基尼指數選擇最優特徵。
參考自部落格,一個使用rpart完成決策樹分類的例子如下:
- library(rpart);
- ## rpart.control對樹進行一些設定
- ## xval是10折交叉驗證
- ## minsplit是最小分支節點數,這裡指大於等於20,那麼該節點會繼續分劃下去,否則停止
- ## minbucket:葉子節點最小樣本數
- ## maxdepth:樹的深度
- ## cp全稱為complexity parameter,指某個點的複雜度,對每一步拆分,模型的擬合優度必須提高的程度
- ct <- rpart.control(xval=10, minsplit=20, cp=0.1)
- ## kyphosis是rpart這個包自帶的資料集
- ## na.action:缺失資料的處理辦法,預設為刪除因變數缺失的觀測而保留自變數缺失的觀測。
- ## method:樹的末端資料型別選擇相應的變數分割方法:
- ## 連續性method=“anova”,離散型method=“class”,計數型method=“poisson”,生存分析型method=“exp”
- ## parms用來設定三個引數:先驗概率、損失矩陣、分類純度的度量方法(gini和information)
- ## cost我覺得是損失矩陣,在剪枝的時候,葉子節點的加權誤差與父節點的誤差進行比較,考慮損失矩陣的時候,從將“減少-誤差”調整為“減少-損失”
- fit <- rpart(Kyphosis~Age + Number + Start,
- data=kyphosis, method="class",control=ct,
- parms = list(prior = c(0.65,0.35), split = "information"));
- ## 第一種
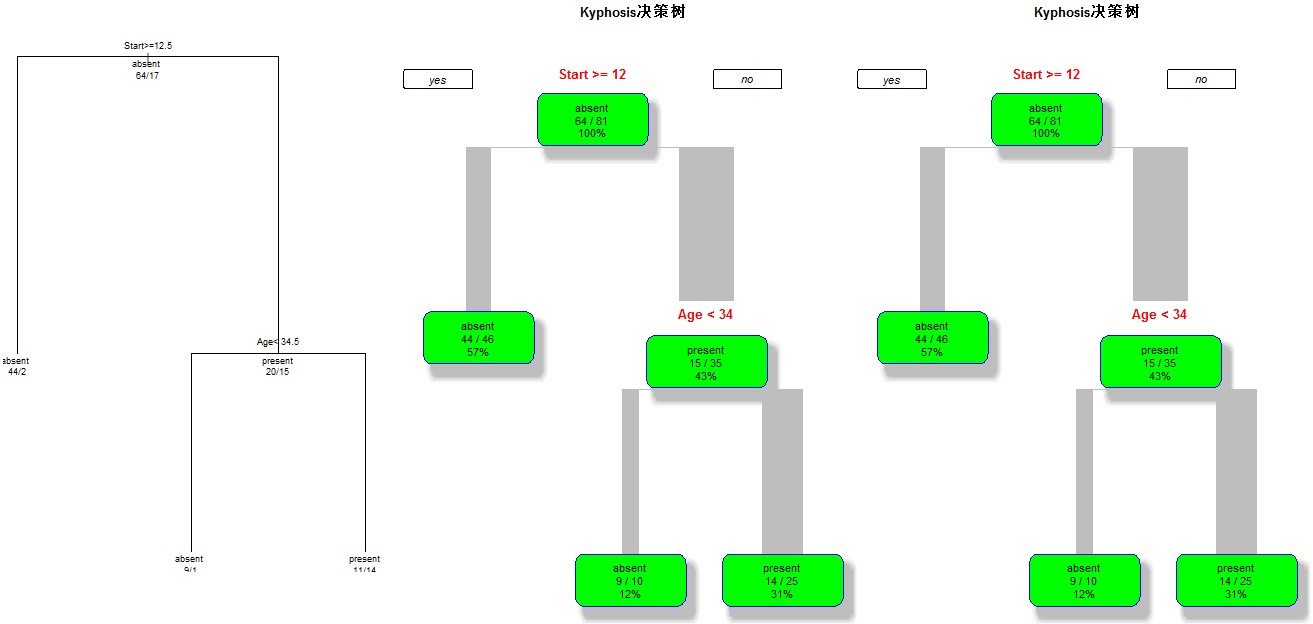
- par(mfrow=c(1,3));
- plot(fit);
- text(fit,use.n=T,all=T,cex=0.9);
- ## 第二種,這種會更漂亮一些
- library(rpart.plot);
- rpart.plot(fit, branch=1, branch.type=2, type=1, extra=102,
- shadow.col="gray", box.col="green",
- border.col="blue", split.col="red",
- split.cex=1.2, main="Kyphosis決策樹");
- ## rpart包提供了複雜度損失修剪的修剪方法,printcp會告訴分裂到每一層,cp是多少,平均相對誤差是多少
- ## 交叉驗證的估計誤差(“xerror”列),以及標準誤差(“xstd”列),平均相對誤差=xerror±xstd
- printcp(fit);
- ## 通過上面的分析來確定cp的值
- ## 我們可以用下面的辦法選擇具有最小xerror的cp的辦法:
- ## prune(fit, cp= fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"])
- fit2 <- prune(fit, cp=0.01);
- rpart.plot(fit2, branch=1, branch.type=2, type=1, extra=102,
- shadow.col="gray", box.col="green",
- border.col="blue", split.col="red",
- split.cex=1.2, main="Kyphosis決策樹");
效果圖如下: