
深度學習中啟用函式的優缺點
在深度學習中,訊號從一個神經元傳入到下一層神經元之前是通過線性疊加來計算的,而進入下一層神經元需要經過非線性的啟用函式,繼續往下傳遞,如此迴圈下去。由於這些非線性函式的反覆疊加,才使得神經網路有足夠的capacity來抓取複雜的特徵。
為什麼要使用非線性啟用函式?
答:如果不使用啟用函式,這種情況下每一層輸出都是上一層輸入的線性函式。無論神經網路有多少層,輸出都是輸入的線性函式,這樣就和只有一個隱藏層的效果是一樣的。這種情況相當於多層感知機(MLP)。
1、Sigmoid函式
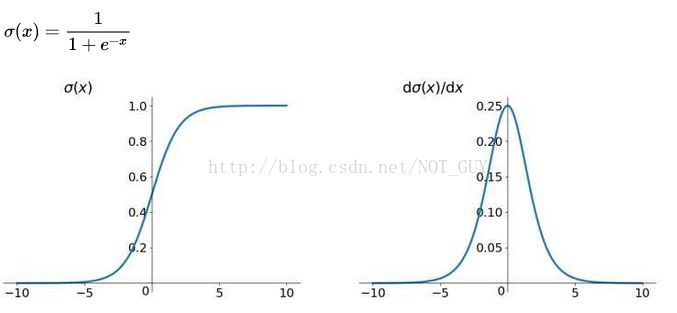
優點:(1)便於求導的平滑函式;
(2)能壓縮資料,保證資料幅度不會有問題;
(3)適合用於前向傳播。
缺點:(1)容易出現梯度消失(gradient vanishing)的現象:當啟用函式接近飽和區時,變化太緩慢,導數接近0,根據後向傳遞的數學依據是微積分求導的鏈式法則,當前導數需要之前各層導數的乘積,幾個比較小的數相乘,導數結果很接近0,從而無法完成深層網路的訓練。
(2)Sigmoid的輸出不是0均值(zero-centered)的:這會導致後層的神經元的輸入是非0均值的訊號,這會對梯度產生影響。以 f=sigmoid(wx+b)為例, 假設輸入均為正數(或負數),那麼對w的導數總是正數(或負數),這樣在反向傳播過程中要麼都往正方向更新,要麼都往負方向更新,導致有一種捆綁效果,使得收斂緩慢。
(3)冪運算相對耗時
2、tanh函式
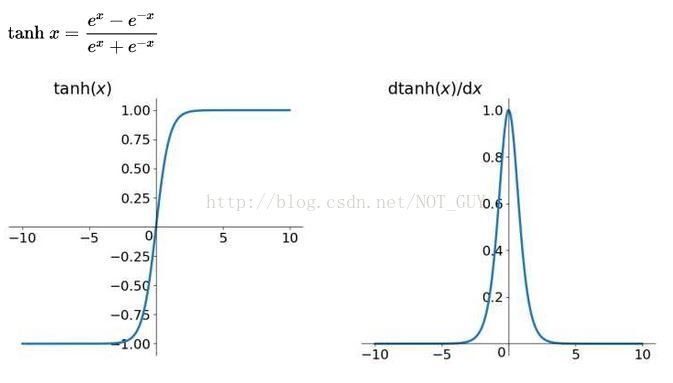
tanh函式將輸入值壓縮到 -1~1 的範圍,因此它是0均值的,解決了Sigmoid函式的非zero-centered問題,但是它也存在梯度消失和冪運算的問題。
其實 tanh(x)=2sigmoid(2x)-1
3、ReLU函式:全區間不可導
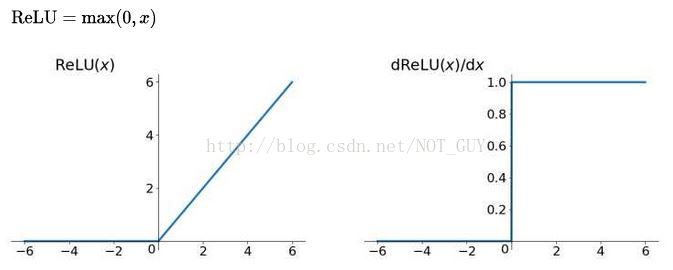
優點:(1)SGD演算法的收斂速度比 sigmoid 和 tanh 快;(梯度不會飽和,解決了梯度消失問題)
(2)計算複雜度低,不需要進行指數運算;
(3)適合用於後向傳播。
缺點:(1)ReLU的輸出不是zero-centered;
(2)Dead ReLU Problem(神經元壞死現象):某些神經元可能永遠不會被啟用,導致相應引數永遠不會被更新(在負數部分,梯度為0)。產生這種現象的兩個原因:引數初始化問題;learning rate太高導致在訓練過程中引數更新太大。 解決方法:採用Xavier初始化方法,以及避免將learning rate設定太大或使用adagrad等自動調節learning rate的演算法。
(3)ReLU不會對資料做幅度壓縮,所以資料的幅度會隨著模型層數的增加不斷擴張。
4、Leakly ReLU函式
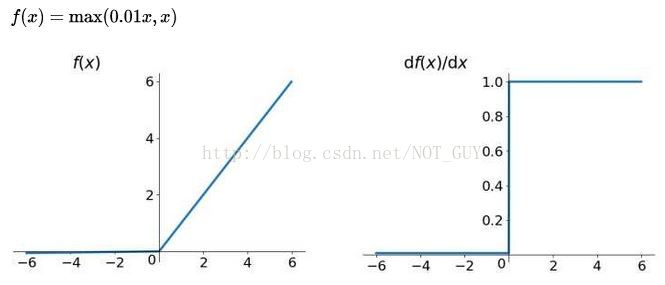
用來解決ReLU帶來的神經元壞死的問題,可以將0.01設定成一個變數a,其中a由後向傳播學出來。但是其表現並不一定比ReLU好。
5、ELU函式(指數線性函式)
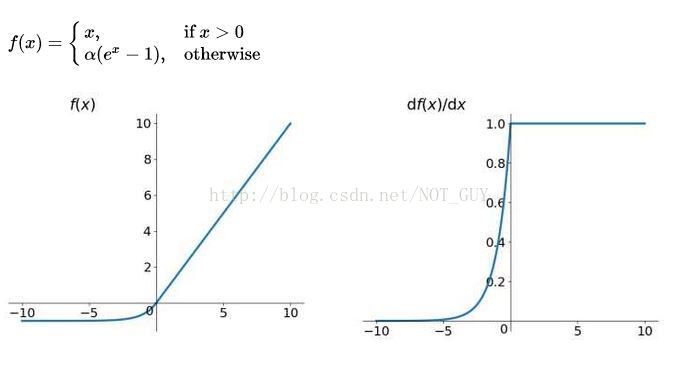
ELU有ReLU的所有優點,並且不會有 Dead ReLU問題,輸出的均值接近0(zero-centered)。但是計算量大,其表現並不一定比ReLU好。。