
理解交叉熵(cross_entropy)作為損失函式在神經網路中的作用
交叉熵的作用
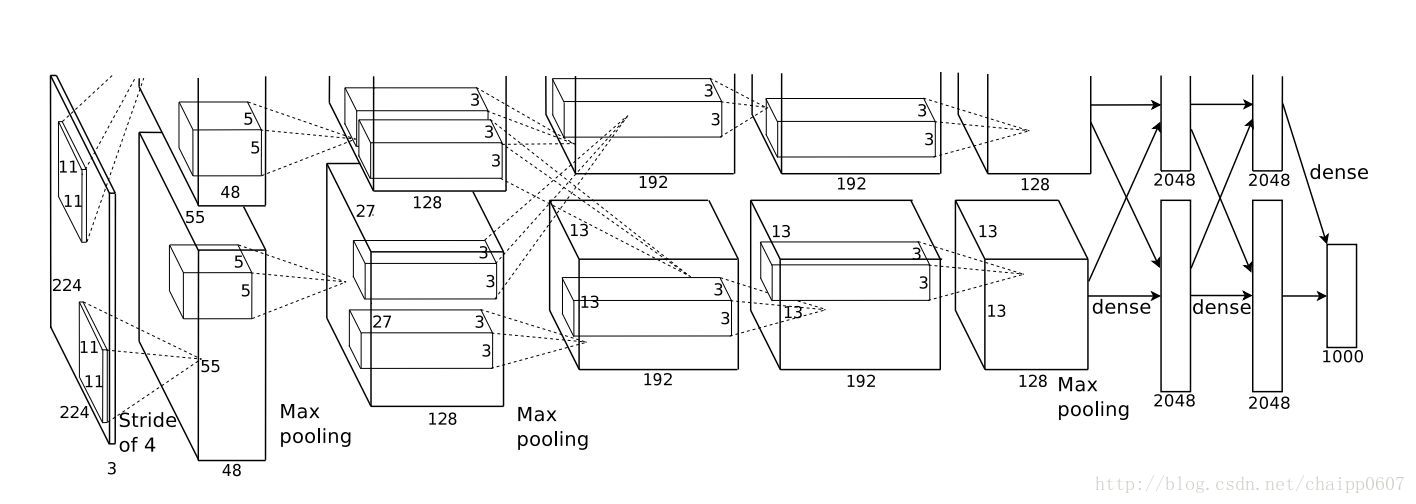
通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點:
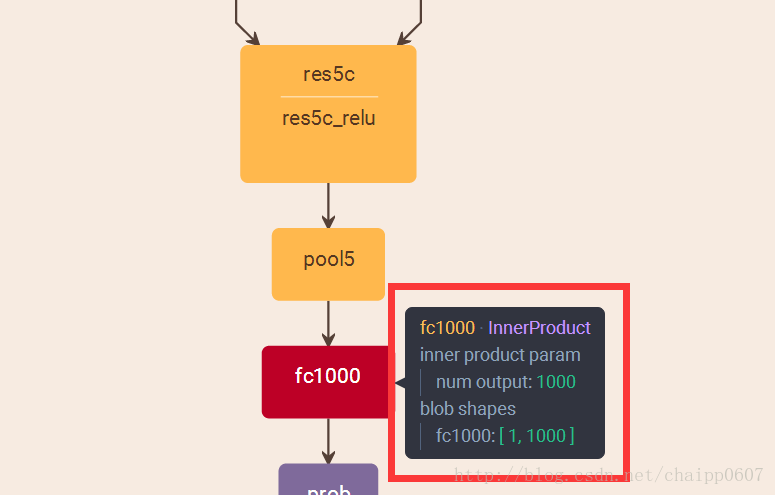
而即便是ResNet取消了全連線層,也會在最後有一個1000個節點的輸出層:
一般情況下,最後一個輸出層的節點個數與分類任務的目標數相等。假設最後的節點數為N,那麼對於每一個樣例,神經網路可以得到一個N維的陣列作為輸出結果,陣列中每一個維度會對應一個類別。在最理想的情況下,如果一個樣本屬於k,那麼這個類別所對應的的輸出節點的輸出值應該為1,而其他節點的輸出都為0,即[0,0,1,0,….0,0],這個陣列也就是樣本的Label,是神經網路最期望的輸出結果,交叉熵就是用來判定實際的輸出與期望的輸出的接近程度!
Softmax迴歸處理
神經網路的原始輸出不是一個概率值,實質上只是輸入的數值做了複雜的加權和與非線性處理之後的一個值而已,那麼如何將這個輸出變為概率分佈?
這就是Softmax層的作用,假設神經網路的原始輸出為y1,y2,….,yn,那麼經過Softmax迴歸處理之後的輸出為:
很顯然的是:
而單個節點的輸出變成的一個概率值,經過Softmax處理後結果作為神經網路最後的輸出。
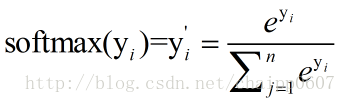
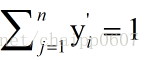
交叉熵的原理
交叉熵刻畫的是實際輸出(概率)與期望輸出(概率)的距離,也就是交叉熵的值越小,兩個概率分佈就越接近。假設概率分佈p為期望輸出,概率分佈q為實際輸出,H(p,q)為交叉熵,則:
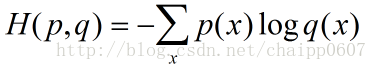
這個公式如何表徵距離呢,舉個例子:
假設N=3,期望輸出為p=(1,0,0),實際輸出q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1),那麼:
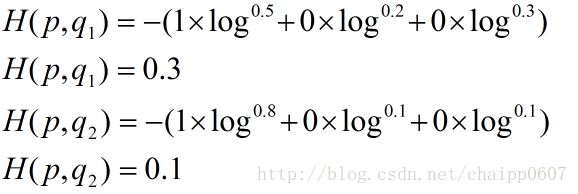
很顯然,q2與p更為接近,它的交叉熵也更小。
除此之外,交叉熵還有另一種表達形式,還是使用上面的假設條件:
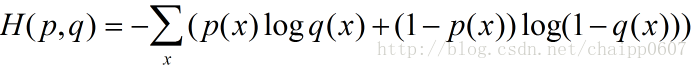
其結果為:
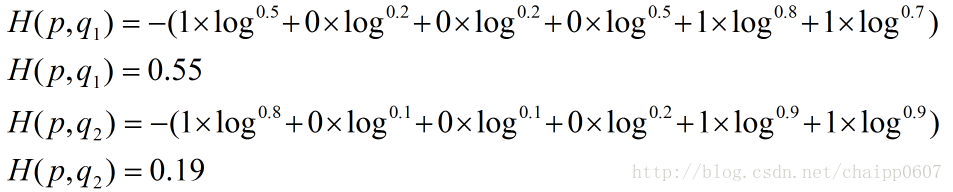
以上的所有說明針對的都是單個樣例的情況,而在實際的使用訓練過程中,資料往往是組合成為一個batch來使用,所以對用的神經網路的輸出應該是一個m*n的二維矩陣,其中m為batch的個數,n為分類數目,而對應的Label也是一個二維矩陣,還是拿上面的資料,組合成一個batch=2的矩陣:
所以交叉熵的結果應該是一個列向量(根據第一種方法):
而對於一個batch,最後取平均為0.2。
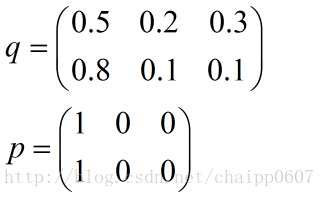
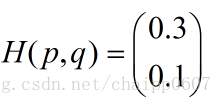
在TensorFlow中實現交叉熵
在TensorFlow可以採用這種形式:
cross_entropy = -tf.reduce 其中y_表示期望的輸出,y表示實際的輸出(概率值),*為矩陣元素間相乘,而不是矩陣乘。
上述程式碼實現了第一種形式的交叉熵計算,需要說明的是,計算的過程其實和上面提到的公式有些區別,按照上面的步驟,平均交叉熵應該是先計算batch中每一個樣本的交叉熵後取平均計算得到的,而利用tf.reduce_mean函式其實計算的是整個矩陣的平均值,這樣做的結果會有差異,但是並不改變實際意義。
除了tf.reduce_mean函式,tf.clip_by_value函式是為了限制輸出的大小,為了避免log0為負無窮的情況,將輸出的值限定在(1e-10, 1.0)之間,其實1.0的限制是沒有意義的,因為概率怎麼會超過1呢。
由於在神經網路中,交叉熵常常與Sorfmax函式組合使用,所以TensorFlow對其進行了封裝,即:
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(y_ ,y)
與第一個程式碼的區別在於,這裡的y用神經網路最後一層的原始輸出就好了。
轉:http://blog.csdn.net/chaipp0607/article/details/73392175
相關推薦
理解交叉熵(cross_entropy)作為損失函式在神經網路中的作用
交叉熵的作用通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點: 而即便是ResNet取消了全連線層,也會在最後有一個1000個節點的輸出層: 一般情況下
為什麼交叉熵可以作為損失函式?
通俗的理解: 熵:可以表示一個事件A的自資訊量,就是A包含多少資訊。 KL散度:可以用來表示從事件A的角度來看,事件B有多大不同。 交叉熵:可以用來表示從事件A的角度來看,如何描述事件B。 熵的公式:
理解交叉熵作為損失函式在神經網路中的作用
交叉熵的作用 通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點: 而即便是ResNet取消了全連線層,也會在最後有一個1000個節
為什麼用交叉熵作為損失函式
交叉熵(cross entropy)經常用來做機器學習中的損失函式。 要講交叉熵就要從最基本的資訊熵說起。 1.資訊熵 資訊熵是消除不確定性所需資訊量的度量。(多看幾遍這句話) 資訊熵就是資訊的不確定程度,資訊熵越小,資訊越確定。 信息熵=∑x=1n(信息x發生
深度學習基礎系列(五)| 深入理解交叉熵函式及其在tensorflow和keras中的實現
在統計學中,損失函式是一種衡量損失和錯誤(這種損失與“錯誤地”估計有關,如費用或者裝置的損失)程度的函式。假設某樣本的實際輸出為a,而預計的輸出為y,則y與a之間存在偏差,深度學習的目的即是通過不斷地訓練迭代,使得a越來越接近y,即 a - y →0,而訓練的本質就是尋找損失函式最小值的過程。 常見的
理解交叉熵損失(Cross-Entropy)
理解交叉熵損失 字符集編碼 字符集編碼的意義在於將資料集進行有效壓縮。 假設在一個文件中只出現了a、b、c、d、e 5種字元,其佔比如下表: 字元 a b c d e 佔比 0.1 0.1 0.2
神經網路中交叉熵代價函式 求導
最近看了幾篇神經網路的入門介紹知識,有幾篇很淺顯的博文介紹了神經網路演算法執行的基本原理,首先盜用伯樂線上中的一個11行python程式碼搞定的神經網路, import numpy as np # sigmoid function def nonlin(
一文搞懂交叉熵在機器學習中的使用,透徹理解交叉熵背後的直覺
關於交叉熵在loss函式中使用的理解 交叉熵(cross entropy)是深度學習中常用的一個概念,一般用來求目標與預測值之間的差距。以前做一些分類問題
tensorflow+faster rcnn程式碼理解(三):損失函式構建
前面兩篇部落格已經敘述了基於vgg模型構建faster rcnn的過程: tensorflow+faster rcnn程式碼理解(一):構建vgg前端和RPN網路 tensorflow+faster rcnn程式碼解析(二):anchor_target_layer、proposal_targ
理解神經網路中的目標函式
這篇部落格主要面向擁有一定機器學習經驗的人,會幫助你直觀理解在訓練神經網路時所用到的各種不同的目標函式。 Introduction 我寫這篇部落格的原因主要有 3 個: 其他部落格中經常會解釋優化演算法,例如 SGD(stochastic gradi
理解交叉熵和最大似然估計的關係
理解交叉熵作為神經網路的損失函式的意義: 交叉熵刻畫的是實際輸出(概率)與期望輸出(概率)的距離,也就是交叉熵的值越小,兩個概率分佈就越接近,即擬合的更好。 CrossEntropy=H(p)+DKL(p∣∣q)Cross Entropy= H(p)+DKL(p
熵、交叉熵及似然函式的關係
目錄 熵、交叉熵及似然函式的關係 1. 熵 1.1 資訊量 1.3 熵 2. 最大熵中的極大似然函式 2.1 指數型似然函式推導 2.2 最大
神經網路中的非線性啟用函式
目錄 0. 前言 1. ReLU 整流線性單元 2. 絕對值整流線性單元 3. 滲漏整流線性單元 4. 引數化整流線性單元 5. maxout 單元 6. logistic sigmoid 單元
神經網路中sigmoid 與代價函式
1.從方差代價函式說起 代價函式經常用方差代價函式(即採用均方誤差MSE),比如對於一個神經元(單輸入單輸出,sigmoid函式),定義其代價函式為: 其中y是我們期望的輸出,a為神經元的實際輸出【 a=σ(z), where z=wx+b 】。 在訓練神經網路過程中,我們通過梯度下降演算
卷積神經網路中感受野的理解和計算
什麼是感受野 “感受野”的概念來源於生物神經科學,比如當我們的“感受器”,比如我們的手受到刺激之後,會將刺激傳輸至中樞神經,但是並不是一個神經元就能夠接受整個面板的刺激,因為面板面積大,一個神經元可想而知肯定接受不完,而且我們同時可以感受到身上面板在不同的地方,如手、腳,的不同的刺激,如
[深度學習] 神經網路中的啟用函式(Activation function)
20180930 在研究調整FCN模型的時候,對啟用函式做更深入地選擇,記錄學習內容 啟用函式(Activation Function),就是在人工神經網路的神經元上執行的函式,負責將神經元的輸入對映到輸出端。 線性啟用函式:最簡單的linear fun
關於神經網路中隱藏層和神經元的深入理解
最近複習了一下基礎知識,看到MLP的結構,關於隱藏層和神經元有了新的一些理解。 隱藏層的意義 要說明隱藏層的意義,需要從兩個方面理解,一個是單個隱藏層的意義,一個是多層隱藏層的意義。 單個隱藏層的意義 隱藏層的意義就是把輸入資料的特徵,抽象到另一個維度空間,來
神經網路中epoch, iteration, batchsize相關理解和說明
batchsize:中文翻譯為批大小(批尺寸)。 簡單點說,批量大小將決定我們一次訓練的樣本數目。 batch_size將影響到模型的優化程度和速度。 為什麼需要有 Batch_Size : batchsize 的正確選擇是為了在記憶體效率和記憶體容量之間尋找最佳平衡。
神經網路中Epoch、Iteration、Batchsize相關理解和說明
看了半年論文,對這三個概念總是模稜兩可,不是很清楚。所以呢!我就花了半天時間,收集網上寫的很好的關於這三個概念的介紹,把他們總結到一起,希望能對大家有幫助!batchsize:中文翻譯為批大小(批尺寸)。簡單點說,批量大小將決定我們一次訓練的樣本數目。batch_size將影
為什麼神經網路中需要啟用函式(activation function)?
在看tensorflow的時候,發現書中程式碼提到,使用ReLU啟用函式完成去線性化為什麼需要啟用函式去線性化?查了一下quaro,覺得這個回答能看明白(順便問一句,截圖算不算引用??)---------------------------------------------