
理解交叉熵作為損失函式在神經網路中的作用
交叉熵的作用
通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點:
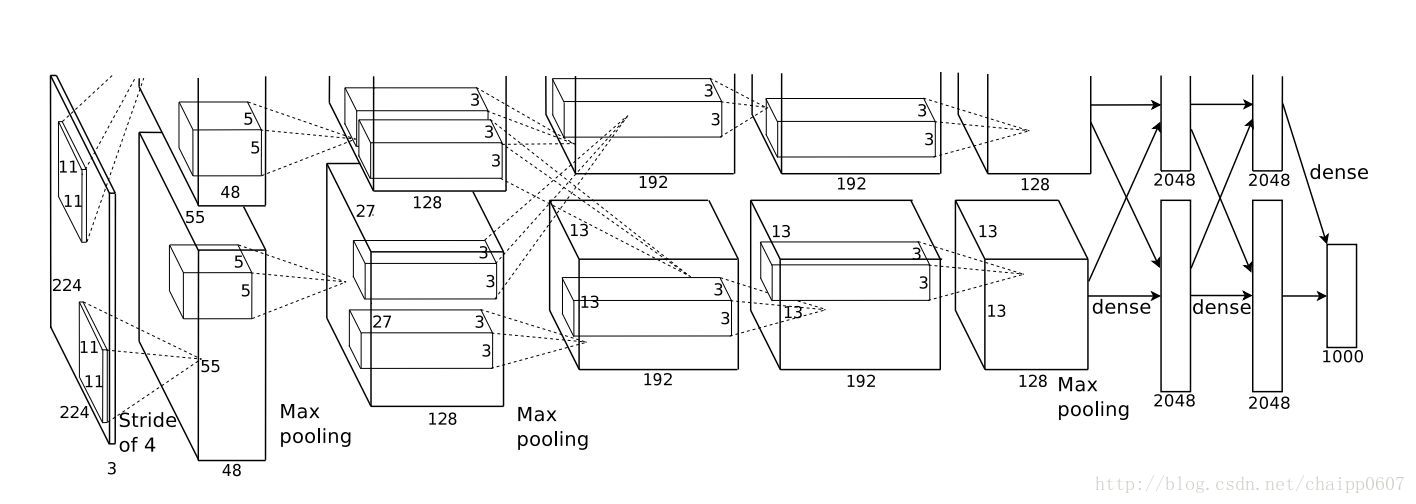
而即便是ResNet取消了全連線層,也會在最後有一個1000個節點的輸出層:
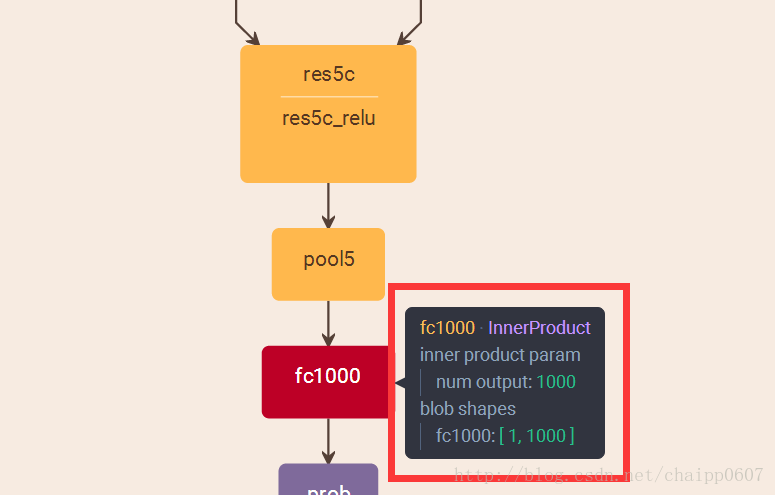
一般情況下,最後一個輸出層的節點個數與分類任務的目標數相等。假設最後的節點數為N,那麼對於每一個樣例,神經網路可以得到一個N維的陣列作為輸出結果,陣列中每一個維度會對應一個類別。在最理想的情況下,如果一個樣本屬於k,那麼這個類別所對應的的輸出節點的輸出值應該為1,而其他節點的輸出都為0,即[0,0,1,0,….0,0],這個陣列也就是樣本的Label,是神經網路最期望的輸出結果,交叉熵就是用來判定實際的輸出與期望的輸出的接近程度!
Softmax迴歸處理
神經網路的原始輸出不是一個概率值,實質上只是輸入的數值做了複雜的加權和與非線性處理之後的一個值而已,那麼如何將這個輸出變為概率分佈?
這就是Softmax層的作用,假設神經網路的原始輸出為y1,y2,….,yn,那麼經過Softmax迴歸處理之後的輸出為:
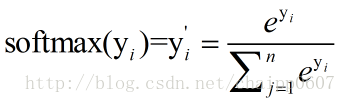
很顯然的是:
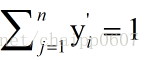
而單個節點的輸出變成的一個概率值,經過Softmax處理後結果作為神經網路最後的輸出。
交叉熵的原理
交叉熵刻畫的是實際輸出(概率)與期望輸出(概率)的距離,也就是交叉熵的值越小,兩個概率分佈就越接近。假設概率分佈p為期望輸出,概率分佈q為實際輸出,H(p,q)為交叉熵,則:
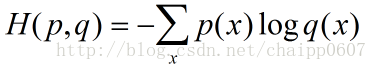
這個公式如何表徵距離呢,舉個例子:
假設N=3,期望輸出為p=(1,0,0),實際輸出q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1),那麼:
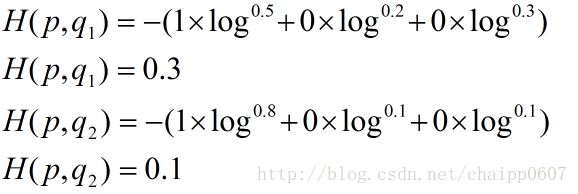
很顯然,q2與p更為接近,它的交叉熵也更小。
除此之外,交叉熵還有另一種表達形式,還是使用上面的假設條件:
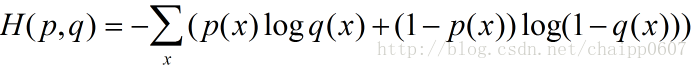
其結果為:
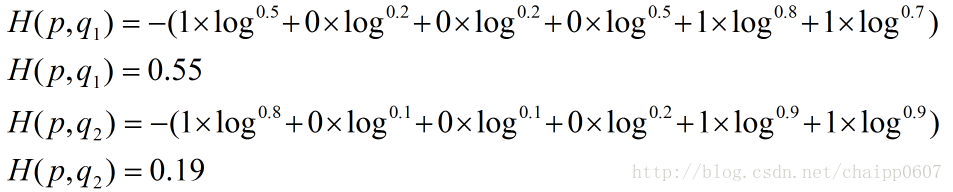
以上的所有說明針對的都是單個樣例的情況,而在實際的使用訓練過程中,資料往往是組合成為一個batch來使用,所以對用的神經網路的輸出應該是一個m*n的二維矩陣,其中m為batch的個數,n為分類數目,而對應的Label也是一個二維矩陣,還是拿上面的資料,組合成一個batch=2的矩陣:
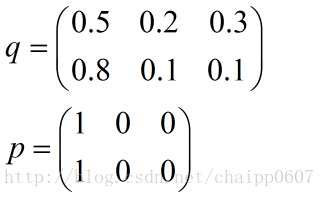
所以交叉熵的結果應該是一個列向量(根據第一種方法):
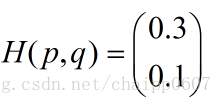
而對於一個batch,最後取平均為0.2。
在TensorFlow中實現交叉熵
在TensorFlow可以採用這種形式:
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))) 其中y_表示期望的輸出,y表示實際的輸出(概率值),*為矩陣元素間相乘,而不是矩陣乘。
上述程式碼實現了第一種形式的交叉熵計算,需要說明的是,計算的過程其實和上面提到的公式有些區別,按照上面的步驟,平均交叉熵應該是先計算batch中每一個樣本的交叉熵後取平均計算得到的,而利用tf.reduce_mean函式其實計算的是整個矩陣的平均值,這樣做的結果會有差異,但是並不改變實際意義。
除了tf.reduce_mean函式,tf.clip_by_value函式是為了限制輸出的大小,為了避免log0為負無窮的情況,將輸出的值限定在(1e-10, 1.0)之間,其實1.0的限制是沒有意義的,因為概率怎麼會超過1呢。
由於在神經網路中,交叉熵常常與Sorfmax函式組合使用,所以TensorFlow對其進行了封裝,即:
cross_entropy = tf.nn.sorfmax_cross_entropy_with_logits(y_ ,y) 與第一個程式碼的區別在於,這裡的y用神經網路最後一層的原始輸出就好了。