
通俗易懂--嶺迴歸(L2)、lasso迴歸(L1)、ElasticNet講解(演算法+案例)
1.L2正則化(嶺迴歸)
1.1問題

想要理解什麼是正則化,首先我們先來了解上圖的方程式。當訓練的特徵和資料很少時,往往會造成欠擬合的情況,對應的是左邊的座標;而我們想要達到的目的往往是中間的座標,適當的特徵和資料用來訓練;但往往現實生活中影響結果的因素是很多的,也就是說會有很多個特徵值,所以訓練模型的時候往往會造成過擬合的情況,如右邊的座標所示。
1.2公式
以圖中的公式為例,往往我們得到的模型是:
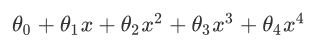
為了能夠得到中間座標的圖形,肯定是希望θ3和θ4越小越好,因為這兩項越小就越接近於0,就可以得到中間的圖形了。
對應的損失函式也加上這個懲罰項(為了懲罰θ):假設λ=1000
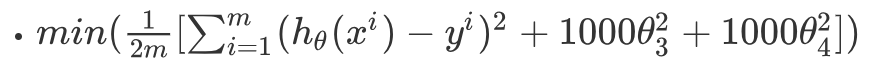
為了求得最小值,使θ值趨近於0
把以上公式通用化得:
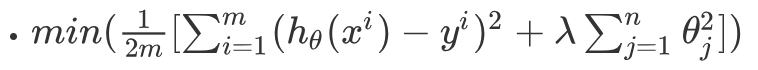
相當於在原始損失函式中加上了一個懲罰項(λ項)
這就是防止過擬合的一個方法,通常叫做L2正則化,也叫作嶺迴歸。
1.3對應圖形
我們可以簡化L2正則化的方程:
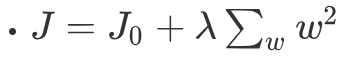
J0表示原始的損失函式,咱們假設正則化項為:
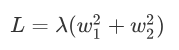
我們不妨回憶一下圓形的方程:
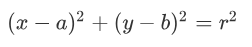
其中(a,b)為圓心座標,r為半徑。那麼經過座標原點的單位元可以寫成:
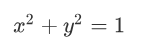
正和L2正則化項一樣,同時,機器學習的任務就是要通過一些方法(比如梯度下降)求出損失函式的最小值。
此時我們的任務變成在L約束下求出J0取最小值的解。
求解J0的過程可以畫出等值線。同時L2正則化的函式L也可以在w1w2的二維平面上畫出來。如下圖:
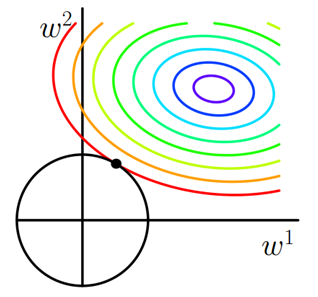
L表示為圖中的黑色圓形,隨著梯度下降法的不斷逼近,與圓第一次產生交點,而這個交點很難出現在座標軸上。
這就說明了L2正則化不容易得到稀疏矩陣,同時為了求出損失函式的最小值,使得w1和w2無限接近於0,達到防止過擬合的問題。
1.4使用場景
只要資料線性相關,用LinearRegression擬合的不是很好,需要正則化,可以考慮使用嶺迴歸(L2), 如何輸入特徵的維度很高,而且是稀疏線性關係的話, 嶺迴歸就不太合適,考慮使用Lasso迴歸。
1.5程式碼實現
2.L1正則化(lasso迴歸)
2.1公式
L1正則化與L2正則化的區別在於懲罰項的不同:
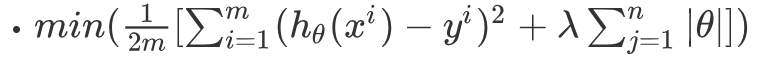
L1正則化表現的是θ的絕對值,變化為上面提到的w1和w2可以表示為:
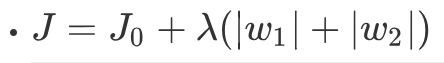
2.2對應圖形
求解J0的過程可以畫出等值線。同時L1正則化的函式也可以在w1w2的二維平面上畫出來。如下圖:
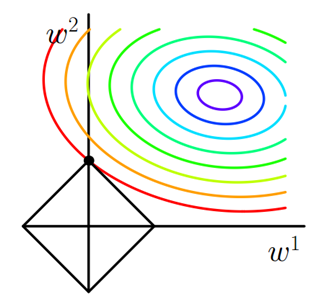
懲罰項表示為圖中的黑色稜形,隨著梯度下降法的不斷逼近,與稜形第一次產生交點,而這個交點很容易出現在座標軸上。這就說明了L1正則化容易得到稀疏矩陣。
2.3使用場景
L1正則化(Lasso迴歸)可以使得一些特徵的係數變小,甚至還使一些絕對值較小的係數直接變為0,從而增強模型的泛化能力 。對於高緯的特徵資料,尤其是線性關係是稀疏的,就採用L1正則化(Lasso迴歸),或者是要在一堆特徵裡面找出主要的特徵,那麼L1正則化(Lasso迴歸)更是首選了。
2.4程式碼實現
3.ElasticNet迴歸
3.1公式
ElasticNet綜合了L1正則化項和L2正則化項,以下是它的公式:
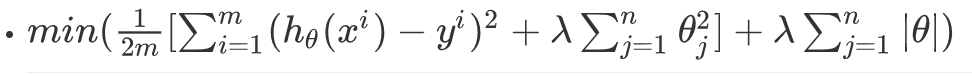
3.2使用場景
ElasticNet在我們發現用Lasso迴歸太過(太多特徵被稀疏為0),而嶺迴歸也正則化的不夠(迴歸係數衰減太慢)的時候,可以考慮使用ElasticNet迴歸來綜合,得到比較好的結果。
3.3程式碼實現
from sklearn import linear_model
#得到擬合模型,其中x_train,y_train為訓練集
ENSTest = linear_model.ElasticNetCV(alphas=[0.0001, 0.0005, 0.001, 0.01, 0.1, 1, 10], l1_ratio=[.01, .1, .5, .9, .99], max_iter=5000).fit(x_train, y_train)
#利用模型預測,x_test為測試集特徵變數
y_prediction = ENSTest.predict(x_test).
.
.

歡迎新增微信交流!請備註“機器學習”。