
深度學習中的sigmod函式、tanh函式、ReLU函式
1. sigmod核函式
sigmod函式的數學公式為: 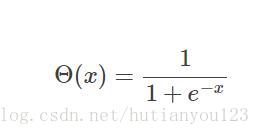
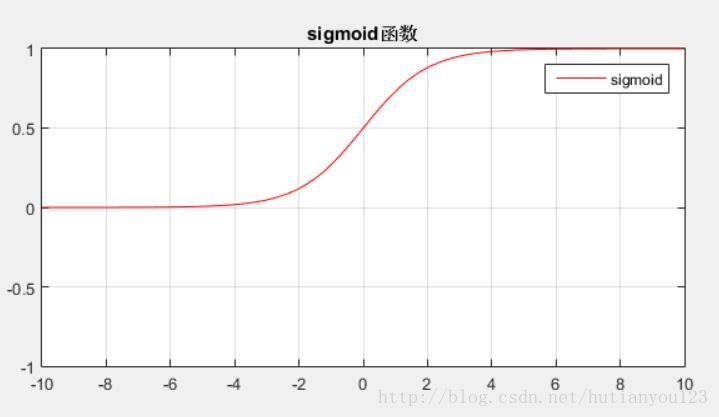
函式取值範圍(0,1),函式影象下圖所示:
二. tanh(x) 函式
tanh(x)函式的數學公式為:
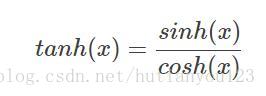
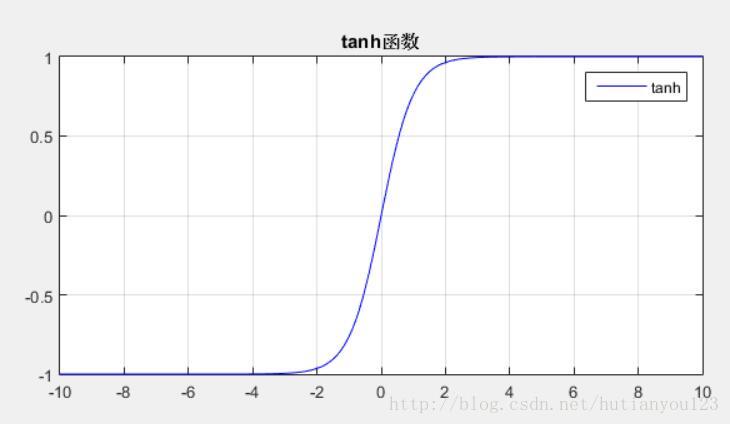
函式取值範圍(-1,1),函式影象下圖所示:
三. ReLU(校正線性單元:Rectified Linear Unit)啟用函式
ReLU函式公式為 : 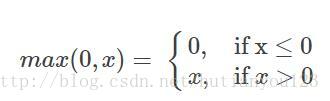
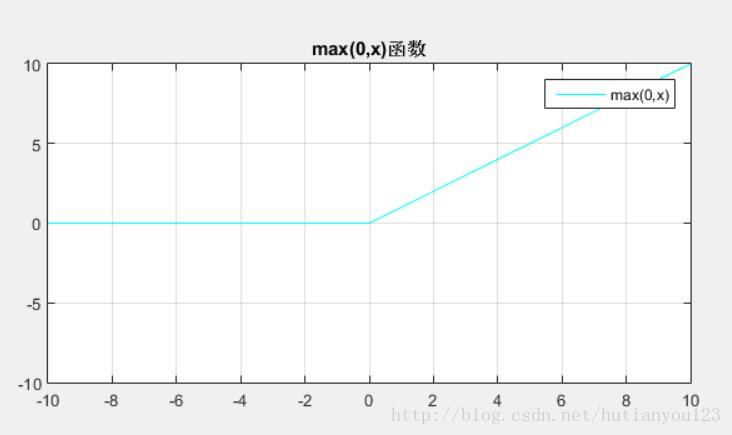
影象為:
四、高斯核函式(RBF)
又稱徑向基函式,公式如下所示: 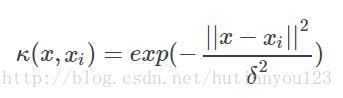
高斯徑向基函式是一種區域性性強的核函式,其可以將一個樣本對映到一個更高維的空間內,該核函式是應用最廣的一個,無論大樣本還是小樣本都有比較好的效能,而且其相對於多項式核函式引數要少,因此大多數情況下在不知道用什麼核函式的時候,優先使用高斯核函式。
參考文獻
相關推薦
深度學習中的sigmod函式、tanh函式、ReLU函式
1. sigmod核函式 sigmod函式的數學公式為: 函式取值範圍(0,1),函式影象下圖所示: 二. tanh(x) 函式 tanh(x)函式的數學公式為: 函式取值範圍(-1,1),函式影象下圖所示: 三. ReLU(校正線性單元:Rectif
聊一聊深度學習中常用的激勵函式
大家都知道,人腦的基本計算單元叫做神經元。現代生物學表明,人的神經系統中大概有860億神經元,而這數量巨大的神經元之間大約是通過1014−1015個突觸連線起來的。上面這一幅示意圖,粗略地描繪了一下人體神經元與我們簡化過後的數學模型。每個神經元都從樹突接受訊號,同時順著某個軸突傳遞
在深度學習中Softmax交叉熵損失函式的公式求導
(以下部分基本介紹轉載於點選開啟連結) 在深度學習NN中的output層通常是一個分類輸出,對於多分類問題我們可以採用k-二元分類器來實現,這裡我們介紹softmax。softmax迴歸中,我們解決的是多分類問題(相對於 logistic 迴歸解決的二分類問題),類標
深度學習中常用的代價函式
1.二次代價函式(quadratic cost): 其中,C表示代價函式,x表示樣本,y表示實際值,a表示輸出值,n表示樣本的總數。為簡單起見,使用一個樣 本為例進行說明,此時二次代價函式為: 假如我們使用梯度下降法(Gradient descent)來調整權值引數的大
深度學習中啟用函式的優缺點
在深度學習中,訊號從一個神經元傳入到下一層神經元之前是通過線性疊加來計算的,而進入下一層神經元需要經過非線性的啟用函式,繼續往下傳遞,如此迴圈下去。由於這些非線性函式的反覆疊加,才使得神經網路有足夠的capacity來抓取複雜的特徵。 為什麼要使用非線性啟用函式? 答:如果
【深度學習基礎-09】神經網路-機器學習深度學習中~Sigmoid函式詳解
目錄 Sigmoid函式常常被用作神經網路中啟用函式 雙曲函式tanh(x) Logistic函式 拓展對比 Sigmoid函式常常被用作神經網路中啟用函式 函式的基本性質: 定義域:(−∞,+∞
深度學習中的啟用函式Sigmoid和ReLu啟用函式和梯度消失問題。
1. Sigmoid啟用函式: Sigmoid啟用函式的缺陷:當 x 取很大的值之後他們對應的 y 值區別不會很大,就會出現梯度消失的問題。因此現在一般都不使用Sigmoid函式,而是使用ReLu啟用函式。2. ReLu啟用函式: ReL
深度學習中啟用函式的選擇
為什麼引入非線性啟用函式 如果不使用非線性的啟用函式,無論疊加多少層,最終的輸出依然只是輸入的線性組合。 引入非線性的啟用函式,使得神經網路可以逼近任意函式。 常用啟用函式 sigmoid函式 σ(z)=11+e−z σ(z)′=σ(z)
深度學習中softmax交叉熵損失函式的理解
1. softmax層的作用 通過神經網路解決多分類問題時,最常用的一種方式就是在最後一層設定n個輸出節點,無論在淺層神經網路還是在CNN中都是如此,比如,在AlexNet中最後的輸出層有1000個節點,即便是ResNet取消了全連線層,但1000個節點的輸出
從極大似然估計的角度理解深度學習中loss函式
從極大似然估計的角度理解深度學習中loss函式 為了理解這一概念,首先回顧下最大似然估計的概念: 最大似然估計常用於利用已知的樣本結果,反推最有可能導致這一結果產生的引數值,往往模型結果已經確定,用於反推模型中的引數.即在引數空間中選擇最有可能導致樣本結果發生的引數.因為結果已知,則某一引數使得結果產生的概率
深度學習中的啟用函式
眾所周知神經網路單元是由線性單元和非線性單元組成的,而非線性單元就是我們今天要介紹的--啟用函式,不同的啟用函式得出的結果也是不同的。他們也各有各的優缺點,雖然啟用函式有自己的發展歷史,不斷的優化,但是如何在眾多啟用函式中做出選擇依然要看我們所實現深度學習實驗的效果。 這篇部落格會分為上下兩篇,
吳恩達深度學習筆記(7)--邏輯迴歸的代價函式(Cost Function)
邏輯迴歸的代價函式(Logistic Regression Cost Function) 在上一篇文章中,我們講了邏輯迴歸模型,這裡,我們講邏輯迴歸的代價函式(也翻譯作成本函式)。 吳恩達讓我轉達大家:這一篇有很多公式,做好準備,睜大眼睛!代價函式很重要! 為什麼需要代價函式: 為
深度學習中的Xavier初始化和He Initialization(MSRA初始化)、Tensorflow中如何選擇合適的初始化方法?
Xavier初始化: 論文:Understanding the difficulty of training deep feedforward neural networks 論文地址:http://proceedings.mlr.press/v9/glorot10a/glorot10a
深度學習中IU、IoU(Intersection over Union)的概念理解以及python程式實現
Intersection over Union是一種測量在特定資料集中檢測相應物體準確度的一個標準。我們可以在很多物體檢測挑戰中,例如PASCAL VOC challenge中看多很多使用該標準的做法。 通常我們在 HOG + Linear SVM objec
深度學習 --- 優化入門三(梯度消失和啟用函式ReLU)
前兩篇的優化主要是針對梯度的存在的問題,如鞍點,區域性最優,梯度懸崖這些問題的優化,本節將詳細探討梯度消失問題,梯度消失問題在BP的網路裡詳細的介紹過(興趣有請的檢視我的這篇文章),然後主要精力介紹RuLU啟用函式,本篇還是根據國外的文章進行翻譯,然後再此基礎上補充,這樣使大家更容易理解,好,那
深度學習中目標檢測演算法 RCNN、Fast RCNN、Faster RCNN 的基本思想
前言 影象分類,檢測及分割是計算機視覺領域的三大任務。即影象理解的三個層次: 分類(Classification),即是將影象結構化為某一類別的資訊,用事先確定好的類別(string)或例項ID來描述圖片。這一任務是最簡單、最基礎的影象理解任務,也是深度學習模型最先取得突
深度學習筆記——理論與推導之概念,成本函式與梯度下降演算法初識(一)
前情提要 一、神經網路介紹 概念:Learning ≈ Looking for a Function 框架(Framework): What is Deep Learning? 深度學習其實就是一個定義方法、判斷方法優劣、挑選最佳的方法的過程:
【深度學習技術】卷積神經網路常用啟用函式總結
本文記錄了神經網路中啟用函式的學習過程,歡迎學習交流。 神經網路中如果不加入啟用函式,其一定程度可以看成線性表達,最後的表達能力不好,如果加入一些非線性的啟用函式,整個網路中就引入了非線性部分,增加了網路的表達能力。目前比較流行的啟用函式主要分為以下7種:
深度學習入門(一)感知機與啟用函式
文章目錄 感知機 啟用函式 1.sigmoid 2.tanh 3.relu 4.softmax 25天看完了吳恩達的機器學習以及《深度學習入門》和《tensorflow實戰》兩本書,吳恩達的學習課程只學了理論知識,另外兩本
深度學習中Attention Mechanism詳細介紹:原理、分類及應用
Attention是一種用於提升基於RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的機制(Mechanism),一般稱為Attention Mechanism。Attention Mechanism目前非常流行,廣泛應用於機器翻譯、語音識別、影象標