
sklearn分類器、資料集的劃分
https://www.cnblogs.com/hhh5460/p/5132203.html
大致可以將這些分類器分成兩類: 1)單一分類器,2)整合分類器
一、單一分類器
下面這個例子對一些單一分類器效果做了比較
# coding=utf-8 from sklearn.cross_validation import cross_val_score from sklearn.datasets import make_blobs # meta-estimator from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.naive_bayes import GaussianNB from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis classifiers = { 'KN': KNeighborsClassifier(3), 'SVC': SVC(kernel="linear", C=0.025), 'SVC': SVC(gamma=2, C=1), 'DT': DecisionTreeClassifier(max_depth=5), 'RF': RandomForestClassifier(n_estimators=10, max_depth=5, max_features=1), # clf.feature_importances_ 'ET': ExtraTreesClassifier(n_estimators=10, max_depth=None), # clf.feature_importances_ 'AB': AdaBoostClassifier(n_estimators=100), 'GB': GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0), # clf.feature_importances_ 'GNB': GaussianNB(), 'LD': LinearDiscriminantAnalysis(), 'QD': QuadraticDiscriminantAnalysis()} X, y = make_blobs(n_samples=10000, n_features=10, centers=100, random_state=0) for name, clf in classifiers.items(): scores = cross_val_score(clf, X, y) print(name, '\t--> ', scores.mean())
下圖是效果圖:

二、整合分類器
整合分類器有四種:Bagging, Voting, GridSearch, PipeLine。最後一個PipeLine其實是管道技術
1.Bagging
from sklearn.ensemble import BaggingClassifier from sklearn.neighbors import KNeighborsClassifier meta_clf = KNeighborsClassifier() bg_clf = BaggingClassifier(meta_clf, max_samples=0.5, max_features=0.5)
2.Voting
from sklearn import datasets from sklearn import cross_validation from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VotingClassifier iris = datasets.load_iris() X, y = iris.data[:, 1:3], iris.target clf1 = LogisticRegression(random_state=1) clf2 = RandomForestClassifier(random_state=1) clf3 = GaussianNB() eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard', weights=[2,1,2]) for clf, label in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble']): scores = cross_validation.cross_val_score(clf, X, y, cv=5, scoring='accuracy') print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
3.GridSearch
import numpy as np
from sklearn.datasets import load_digits
from sklearn.ensemble import RandomForestClassifier
from sklearn.grid_search import GridSearchCV
from sklearn.grid_search import RandomizedSearchCV
# 生成資料
digits = load_digits()
X, y = digits.data, digits.target
# 元分類器
meta_clf = RandomForestClassifier(n_estimators=20)
# =================================================================
# 設定引數
param_dist = {"max_depth": [3, None],
"max_features": sp_randint(1, 11),
"min_samples_split": sp_randint(1, 11),
"min_samples_leaf": sp_randint(1, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
# 執行隨機搜尋 RandomizedSearch
n_iter_search = 20
rs_clf = RandomizedSearchCV(meta_clf, param_distributions=param_dist,
n_iter=n_iter_search)
start = time()
rs_clf.fit(X, y)
print("RandomizedSearchCV took %.2f seconds for %d candidates"
" parameter settings." % ((time() - start), n_iter_search))
print(rs_clf.grid_scores_)
# =================================================================
# 設定引數
param_grid = {"max_depth": [3, None],
"max_features": [1, 3, 10],
"min_samples_split": [1, 3, 10],
"min_samples_leaf": [1, 3, 10],
"bootstrap": [True, False],
"criterion": ["gini", "entropy"]}
# 執行網格搜尋 GridSearch
gs_clf = GridSearchCV(meta_clf, param_grid=param_grid)
start = time()
gs_clf.fit(X, y)
print("GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(gs_clf.grid_scores_)))
print(gs_clf.grid_scores_)4.PipeLine
第一個例子
from sklearn import svm
from sklearn.datasets import samples_generator
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.pipeline import Pipeline
# 生成資料
X, y = samples_generator.make_classification(n_informative=5, n_redundant=0, random_state=42)
# 定義Pipeline,先方差分析,再SVM
anova_filter = SelectKBest(f_regression, k=5)
clf = svm.SVC(kernel='linear')
pipe = Pipeline([('anova', anova_filter), ('svc', clf)])
# 設定anova的引數k=10,svc的引數C=0.1(用雙下劃線"__"連線!)
pipe.set_params(anova__k=10, svc__C=.1)
pipe.fit(X, y)
prediction = pipe.predict(X)
pipe.score(X, y)
# 得到 anova_filter 選出來的特徵
s = pipe.named_steps['anova'].get_support()
print(s)第二個例子
import numpy as np
from sklearn import linear_model, decomposition, datasets
from sklearn.pipeline import Pipeline
from sklearn.grid_search import GridSearchCV
digits = datasets.load_digits()
X_digits = digits.data
y_digits = digits.target
# 定義管道,先降維(pca),再邏輯迴歸
pca = decomposition.PCA()
logistic = linear_model.LogisticRegression()
pipe = Pipeline(steps=[('pca', pca), ('logistic', logistic)])
# 把管道再作為grid_search的estimator
n_components = [20, 40, 64]
Cs = np.logspace(-4, 4, 3)
estimator = GridSearchCV(pipe, dict(pca__n_components=n_components, logistic__C=Cs))
estimator.fit(X_digits, y_digits)進行預測可以有幾種形式:
1)、predict_proba(x):給出帶有概率值的結果。每個點在所有label的概率和為1.
2)、predict(x):直接給出預測結果。內部還是呼叫的predict_proba(),根據概率的結果看哪個型別的預測值最高就是哪個型別。
3)、predict_log_proba(x):和predict_proba基本上一樣,只是把結果給做了log()處理。
sklearn資料集劃分方法有如下方法:
KFold,GroupKFold,StratifiedKFold,LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut,ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit,PredefinedSplit,TimeSeriesSplit,
① K折交叉驗證:KFold,GroupKFold,StratifiedKFold,
- 將全部訓練集S分成k個不相交的子集,假設S中的訓練樣例個數為m,那麼每一個自己有m/k個訓練樣例,相應的子集為{s1,s2,...,sk}
- 每次從分好的子集裡面,拿出一個作為測試集,其他k-1個作為訓練集
- 在k-1個訓練集上訓練出學習器模型
- 把這個模型放到測試集上,得到分類率的平均值,作為該模型或者假設函式的真實分類率
這個方法充分利用了所以樣本,但計算比較繁瑣,需要訓練k次,測試k次
② 留一法:LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,LeavePOut,
- 留一法驗證(Leave-one-out,LOO):假設有N個樣本,將每一個樣本作為測試樣本,其他N-1個樣本作為訓練樣本,這樣得到N個分類器,N個測試結果,用這N個結果的平均值來衡量模型的效能
- 如果LOO與K-fold CV比較,LOO在N個樣本上建立N個模型而不是k個,更進一步,N個模型的每一個都是在N-1個樣本上訓練的,而不是(k-1)*n/k。兩種方法中,假定k不是很大而且k<<N,LOO比k-fold CV更耗時
- 留P法驗證(Leave-p-out):有N個樣本,將每P個樣本作為測試樣本,其它N-P個樣本作為訓練樣本,這樣得到
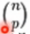 個train-test
pairs,不像LeaveOneOut和KFold,當P>1時,測試集將會發生重疊,當P=1的時候,就變成了留一法
個train-test
pairs,不像LeaveOneOut和KFold,當P>1時,測試集將會發生重疊,當P=1的時候,就變成了留一法
③ 隨機劃分法:ShuffleSplit,GroupShuffleSplit,StratifiedShuffleSplit
- ShuffleSplit迭代器產生指定數量的獨立的train/test資料集劃分,首先對樣本全體隨機打亂,然後再劃分出train/test對,可以使用隨機數種子random_state來控制數字序列發生器使得訊算結果可重現
- ShuffleSplit是KFlod交叉驗證的比較好的替代,他允許更好的控制迭代次數和train/test的樣本比例
- StratifiedShuffleSplit和ShuffleSplit的一個變體,返回分層劃分,也就是在建立劃分的時候要保證每一個劃分中類的樣本比例與整體資料集中的原始比例保持一致
#ShuffleSplit 把資料集打亂順序,然後劃分測試集和訓練集,訓練集額和測試集的比例隨機選定,訓練集和測試集的比例的和可以小於1