
apriori和關聯規則演算法
1993年,R.Agrawal等人首次提出了挖掘顧客交易資料中專案集間的關聯規則問題,其核心是基於兩階段頻繁集思想的遞推演算法。該關聯規則在分類上屬於單維、單層及布林關聯規則,典型的演算法是Aprior演算法。
Aprior演算法將發現關聯規則的過程分為兩個步驟:第一步通過迭代,檢索出事務資料庫中的所有頻繁項集,即支援度不低於使用者設定的閾值的項集;第二步利用頻繁項集構造出滿足使用者最小信任度的規則。其中,挖掘或識別出所有頻繁項集是該演算法的核心,佔整個計算量的大部分。
問題定義: 關聯規則分析是為了在大規模資料集中尋找有趣關係的任務。這些關係分為兩種,頻繁項集和關聯規則。 頻繁項集(frequent item sets)是經常出現在一塊的物品的集合,關聯規則(association rules)暗示兩種物品之間可能存在很強的關係。
apriori演算法就是為了發現頻繁項集。頻繁項集發現後再進行關聯規則分析,需要用到條件概型。
需要思考的問題:
1、頻繁項集,頻繁如何定義,也就是說怎樣才算頻繁?
2、應該如何去定義商品間的購買關係,也就是憑什麼說他們存在某個關係?
3、如何去過濾掉一些不需要的商品關係,篩選出想要的商品關係?
第一個問題會在講apriori演算法原理的時候解決。
第二個問題需要用到條件概型

如下圖對於{0,1,2,3}的組合如下共有15種,即2的N次方減1種,其中N為商品種數。因此計算所有組合的次數時間複雜度是很大的。
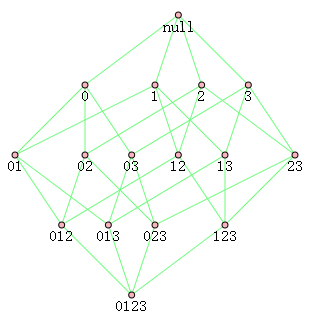
如何降低複雜度呢? 研究人員發現了一種所謂的Apriori原理,如果某個項集是頻繁的,那麼它的所有子集也是頻繁的。逆否命題是,如果某個項集不是頻繁的,那麼包含這個項集的項集也不是頻繁的。這個原理可作為減枝的依據,例如{0}不是頻繁的,那麼包含0的所有項集都不是頻繁的,包含0的項集出現次數就不用統計了。 第一個問題的解決方法:
頻繁項集的頻繁是自定義的,根據實驗場景定義一個次數,低於這個次數的項集就可以減枝減掉。
為了便於計算,下面的支援度用項集出現次數來代替。演算法圖例說明
假設有一個數據庫D,其中有4個事務記錄,分別表示為:
TID Items T1 I1,I3,I4 T2 I2,I3,I5 T3 I1,I2,I3,I5 T4 I2,I5
這裡預定最小支援度minSupport=2,下面用圖例說明演算法執行的過程:
TID Items T1 I1,I3,I4 T2 I2,I3,I5 T3 I1,I2,I3,I5 T4 I2,I5
掃描D,對每個候選項進行支援度計數得到表C1:
項集 支援度計數 {I1} 2 {I2} 3 {I3} 3 {I4} 1 {I5} 3
比較候選項支援度計數與最小支援度minSupport,產生1維最大專案集L1:
項集 支援度計數 {I1} 2 {I2} 3 {I3} 3 {I5} 3
由L1產生候選項集C2:
項集 {I1,I2} {I1,I3} {I1,I5} {I2,I3} {I2,I5} {I3,I5}
掃描D,對每個候選項集進行支援度計數:
項集 支援度計數 {I1,I2} 1 {I1,I3} 2 {I1,I5} 1 {I2,I3} 2 {I2,I5} 3 {I3,I5} 2
比較候選項支援度計數與最小支援度minSupport,產生2維最大專案集L2:
項集 支援度計數 {I1,I3} 2 {I2,I3} 2 {I2,I5} 3 {I3,I5} 2
由L2產生候選項集C3:
項集 {I2,I3,I5}
掃描D,對每個候選項集進行支援度計數:
項集 支援度計數 {I2,I3,I5} 2
比較候選項支援度計數與最小支援度minSupport,產生3維最大專案集L3:
項集 支援度計數 {I2,I3,I5} 2
演算法終止。
從頻繁項中挖掘關聯規則:
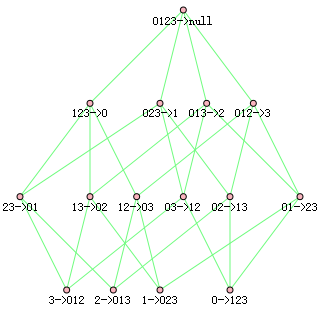
關聯規則挖掘也可以進行減枝,例如012->3,可信度可用如下公式計算為,
對於以012->3為根節點的所有節點,例如03->12,可信度可用如下公式計算為
觀察發現分子是一樣的,分母由於子節點是父節點的子集,所以對應的概率更大,上面的例子P(12) >= P(012)。
所以可以得出如果某條規則不滿足最小可信度,那麼該規則的所有子集也不會滿足最小可信度要求。
在ipython和python3.4環境下進行的實驗,程式碼如下:
例子資料
def loadDataSet(): return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]] def loadDataSet2(): return [[1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6]]""" 建立集合大小為1的項集 """ def createC1(dataSet): C1 = [] for transaction in dataSet: for item in transaction: if not [item] in C1: C1.append([item]) C1.sort() return map(frozenset, C1)#use frozen set so we #can use it as a key in a dict """ 計算指定項集的支援度 D是資料集合,Ck是要求支援度的項集,minSupport是最小支援度 """ def scanD(D, Ck, minSupport): ssCnt = {} for tid in D: for can in Ck: if can.issubset(tid): if not ssCnt.get(can): ssCnt[can]=1 else: ssCnt[can] += 1 numItems = float(len(D)) retList = [] supportData = {} for key in ssCnt: support = ssCnt[key]/numItems if support >= minSupport: retList.insert(0,key) supportData[key] = support return retList, supportData """ 生成集合大小比原來的大一的項集 """ def aprioriGen(Lk, k): #creates Ck retList = [] lenLk = len(Lk) # 如果Lk只有一項,則retList為[] for i in range(lenLk): for j in range(i+1, lenLk): # 為了每次新增的都是單個項構成的集合,所以Lk中項的大小是k-1,那麼前k-2項相同,才能使合併後只比原來多一項。 L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2] L1.sort(); L2.sort() if L1==L2: #if first k-2 elements are equal retList.append(Lk[i] | Lk[j]) #set union return retList """ 求出資料集合中,支援度大於最小支援度的所有項集 """ def apriori(dataSet, minSupport = 0.5): C1 = createC1(dataSet) # 轉化為list型別重要 C1 = list(C1) D = map(set, dataSet) # 轉化為list型別重要 D = list(D) # print(D) # print(C1) L1, supportData = scanD(D, C1, minSupport) # print(L1) L = [L1] k = 2 while (len(L[k-2]) > 0): Ck = aprioriGen(L[k-2], k) Lk, supK = scanD(D, Ck, minSupport)#scan DB to get Lk supportData.update(supK) L.append(Lk) k += 1 return L, supportData """ 計算 freqSet-conseq -> conseq 的可信度, conseq是H中的元素 """ def calcConf(freqSet, H, supportData, brl, minConf=0.7): prunedH = [] #create new list to return for conseq in H: conf = supportData[freqSet]/supportData[freqSet-conseq] #calc confidence if conf >= minConf: print(freqSet-conseq,'-->',conseq,'conf:',conf) brl.append((freqSet-conseq, conseq, conf)) prunedH.append(conseq) return prunedH """ # 1個元素的集合 -> (len(freqSet) - 1) 元素的集合 # 2個元素的集合 -> (len(freqSet) - 2) 元素的集合 # ... """ def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7): print("H:", H) m = len(H[0]) if (len(freqSet) > (m + 1)): #try further merging Hmp1 = aprioriGen(H, m+1)#create Hm+1 new candidates # print("Hmp1:",Hmp1) Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf) # print("Hmp1:",Hmp1) if (len(Hmp1) > 1): #need at least two sets to merge rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf) """ 兩個元素的集合求關聯規則 三個元素的集合求關聯規則 ... """ def generateRules(L, supportData, minConf=0.7): #supportData is a dict coming from scanD bigRuleList = [] for i in range(1, len(L)):#only get the sets with two or more items print(L[i]) for freqSet in L[i]: H1 = [frozenset([item]) for item in freqSet] print(H1) if (i > 1): rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) else: calcConf(freqSet, H1, supportData, bigRuleList, minConf) return bigRuleList
進行apriori演算法項集為1的測試,如果可行再應用到遞推中# 載入資料 dataSet=loadDataSet() dataSet# 獲取集合大小為1的所有項集 C1=createC1(dataSet) # print(len(C1)) # TypeError: object of type 'map' has no len() C1 = list(C1) C1# 將資料型別轉換為集合 D=map(set, dataSet) # print(len(D)) D = list(D) D# 求集合大小為1的項集的支援度,返回留下支援度大於最小支援度的項集和它們的支援度 L1, suppData0 = scanD(D, C1, 0.5) print(L1) print(suppData0)
測試priori演算法L1, suppData0 = apriori(dataSet) print(L1) print() print(suppData0)L1, suppData0 = apriori(dataSet, minSupport=0.7) print(L1) print() print(suppData0)
測試關聯規則
L, suppData = apriori(dataSet, minSupport=0.5) print(L) print() print(suppData)rules = generateRules(L, suppData, minConf=0.7)rules = generateRules(L, suppData, minConf=0.5) rules
缺點: 每次增加頻繁項集的大小,Apriori演算法都會重新掃描整個資料集合。
當資料集很大時,這會顯著降低頻繁項集的發現速度。 參考自: 《機器學習實戰》
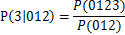
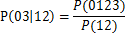

相關推薦
apriori和關聯規則演算法
問題的背景: 超市的會員卡記錄了大量的使用者購買資料,通過分析這些資料可以幫助商店分析使用者的購買行為。從大規模資料集中尋找物品間的隱含關係被稱為關聯規則分析(association analysis)或關聯規則學習(association rule learnin
R語言實戰k-means聚類和關聯規則演算法
1、R語言關於k-means聚類 資料集格式如下所示: ,河東路與嶴東路&河東路與聚賢橋路,河東路與嶴東路&新悅路與嶴東路,河東路與嶴東路&火炬路與聚賢橋路,河東路與嶴東路&
關聯規則演算法Apriori以及FP-growth學習
關聯規則演算法Apriori以及FP-growth學習 最近選擇了關聯規則演算法進行學習,目標是先學習Apriori演算法,再轉FP-growth演算法,因為Spark-mllib庫支援的關聯演算法是FP,隨筆用於邊學邊記錄,完成後再進行整理 一、概述 關聯規則是一種常見的推薦演算法,用於從發現
sparkmllib關聯規則演算法(FPGrowth,Apriori)
關聯規則演算法的思想就是找頻繁項集,通過頻繁項集找強關聯。 介紹下基本概念: 對於A->B 1、置信度:P(B|A),在A發生的事件中同時發生B的概率 p(AB)/P(A)
Apriori演算法-關聯規則演算法
Apriori 演算法的示意圖:交易ID商品ID列表T100I1,I2,I5T200I2,I4T300I2,I3T400I1,I2,I4T500I1,I3T600I2,I3T700I1,I3T800I1,I2,I3,I5T900I1,I2,I3Apriori演算法較為簡單:只
獲取頻繁項集和關聯規則的Python實現【先驗演算法】
# -*- coding: utf-8 -*- #引數設定 data_file = 'F:\\user_match_stat\\itemset.txt' #檔案格式csv,形如:item1,item2,item3 #每個事務佔一行 frequent_itemsets_sav
Apriori、FP-Tree 關聯規則演算法學習
Apriori演算法性質頻繁項集的所有非空子集必須是頻繁項集。支援度項集A、B同時發生的概率稱為關聯規則的支援度,也稱相對支援度。置信度項集A發生,則項集B發生的概率稱為關聯規則的置信度。演算法過程該演算法根據最小支援度找出最大k項頻繁集,再根據最小置信度,在頻繁集中產生關聯
關聯規則演算法(Apriori)在Python上的實現
定義 關聯分析又稱關聯挖掘,就是在交易資料、關係資料或其他資訊載體中,查詢存在於專案集合或物件集合之間的頻繁模式、關聯、相關性或因果結構。可從資料庫中關聯分析出形如“由於某些事件的發生而引起另外一些事件的發生”之類的規則。如“67%的顧客在購買啤酒的同時也會購
頻繁模式和關聯規則原理與簡述
頻繁模式和關聯規則: “啤酒與尿布”故事: 這是一個幾乎被舉爛的例子,“啤酒與尿布”的故事產生於20世紀90年代的美國沃爾瑪超市中,沃爾瑪的超市管理人員分析銷售資料時發現了一個令人難於理解的現象:在某些特定的情況下,“啤酒”與“尿布”兩件看上去毫無關係的商品會經常出現在同一
python資料分析與挖掘學習筆記(6)-電商網站資料分析及商品自動推薦實戰與關聯規則演算法
這一節主要涉及到的資料探勘演算法是關聯規則及Apriori演算法。 由此展開電商網站資料分析模型的構建和電商網站商品自動推薦的實現,並擴充套件到協同過濾演算法。 關聯規則最有名的故事就是啤酒與尿布的故事,非常有效地說明了關聯規則在知識發現和資料探勘中起的作用和意義。 其中有
頻繁模式和關聯規則:
前面的話:本人目前北郵研一在讀,覺得前面的博主寫的很好,自己經常也要看,所以前面一部分轉載於博主的。懇請博主不要誤會,若是給你造成麻煩立即刪除,後面開始學習心得和筆記的記載。希望大家能一起成功! “啤酒與尿布”故事: 這是一個幾乎被舉爛的例子,“啤酒與尿布”的故
基於Spark的FPGrowth(關聯規則演算法)
在推薦中,關聯規則推薦使用的比較頻繁,畢竟是通過概率來預測的,易於理解且準確度比較高,不過有一個缺點為,想要覆蓋推薦物品的數量,就要降低支援度與置信度。過高的支援度與置信度會導致物品覆蓋不過,這裡需要其他的推薦方法合作,建議使用基於Spark的模型推薦演算法(矩
通過word embedding和關聯規則改進Aspect提取效果
思路來源於論文《Improving Opinion Aspect Extraction Using Semantic Similarity and Aspect Association》(Liu, Zh
Fp關聯規則演算法計算置信度及MapReduce實現思路
說明:參考Mahout FP演算法相關相關原始碼。演算法工程可以在FP關聯規則計算置信度下載:(只是單機版的實現,並沒有MapReduce的程式碼)使用FP關聯規則演算法計算置信度基於下面的思路:1. 首先使用原始的FP樹關聯規則挖掘出所有的頻繁項集及其支援度;這裡需要注意,
HotSpot關聯規則演算法(1)-- 挖掘離散型資料
提到關聯規則演算法,一般會想到Apriori或者FP,一般很少有想到HotSpot的,這個演算法不知道是應用少還是我查資料的手段太low了,在網上只找到很少的內容,這篇http://wiki.pentaho.com/display/DATAMINING/HotSpo
從啤酒和尿布講關聯規則,大資料集處理演算法Apriori以及改進的PCY演算法
本文將講解關聯規則的相關概念、處理相關規則的一般演算法、改進的大資料處理關聯規則的Apriori演算法以及進一步優化的PCY演算法。 啤酒和尿布的故事已經廣為人曉。很多年輕的父親買尿布的時候會順便為自己買一瓶啤酒。亞馬遜通過使用者購買資料,使用關聯規則,使用大資料的處理手段得出了尿布和啤
GIS資訊關聯規則挖掘——Apriori演算法的實現(下)
上篇說明了原理,這篇就直接上核心程式碼了~ 程式碼比較長,所以理解可能有點麻煩,核心思路就是計算選擇的維度後遍歷資料,逐步進行迴圈計算置信度,並淘汰每次迴圈後的最低值。 這裡有一點要注意的,我一開始想用arraylist構造一個堆疊結構進行資料遍歷的儲存跟計算,因為這樣效率比較高。
GIS資訊關聯規則挖掘——Apriori演算法的實現(上)
最近閒著無聊沒啥課,幫讀master的朋友做了一個桌面端的GIS系統,主要功能是景區管理。 其中有個核心功能挺有意思的,就是統計所有景區受損設施的所有致損型別和每個型別具體包含的致損因子後,計算致損因子之間的關聯規則,然後可以根據使用者選定的致損型別組合計算出其景區設施造成損害的概率。(有點
資料探勘之關聯規則Apriori演算法
一、Aoriori原始演算法: 頻繁挖掘模式與關聯規則 關聯規則兩個基本的指標(假設有事務A和事務B) 1、支援度(suport):計算公式如下 2、置信度(confidence): 關聯規則的挖掘過程: 1、設定最小支援度閾值,找出所有的頻繁項集且每個出現的次數要
第11章:使用Apriori演算法進行關聯分析(從頻繁項集中挖掘關聯規則)
原理: 根據頻繁項集找關聯規則,如有一個頻繁項集{豆奶,萵苣},那麼可能有一條關聯規則是豆奶->萵苣,即一個人購買了豆奶,則大可能他會購買萵苣,但反過來一個人購買了萵苣,不一定他會購買豆奶,頻繁項集使用支援度量化,關聯規則使用可信度或置信度量化。一條規則P->H的可信度定義為支援