
自適應濾波:梯度下降演算法
作者:桂。
時間:2017-04-01 06:39:15
宣告:歡迎被轉載,不過記得註明出處哦~

【學習筆記07】
前言
西蒙.赫金的《自適應濾波器原理》第四版第四章:最速下降演算法。優化求解按照有/無約束分類:如投影梯度下降演算法((Gradient projection)便是有約束的優化求解;按照一階二階分類:梯度下降(Gradient descent)、Newton法等;按照偏導存在與否分類:如梯度下降、次梯度下降(Subgradient descent)等.本文主要整理:梯度下降法在維納濾波中的應用.
一、原理思想
對於準則函式:
![]()
需要尋找最優解$w_o$,使它對所有$w$滿足$J(w_o) \le J(w)$。可以利用迭代下降的思路求解:
從初始值$w(0)$出發, 產生一系列權向量$w(1)$,$w(2)$...,使得準則函式每一次迭代都是下降的:$J(w(n+1)) < J(w(n))$,其中$w(n)$是權向量的過去值,$w(n+1)$是更新值。
定義梯度:
$g = \nabla J\left( w \right) = \frac{{\partial J\left( w \right)}}{{\partial w}}$
負梯度方向為減小方向:
$w(n + 1) = w(n) - \mu \cdot g(n)$
為了說明準則函式隨著迭代下降,從一階泰勒展開可以觀察:
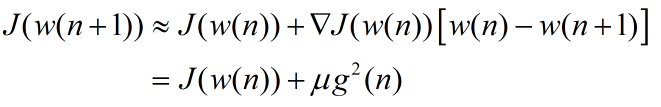
二、應用例項
已知
:含有噪聲的正弦波:$y(n) = x(n) + w(n) = \sin (2\pi fn + \theta ) + w(n)$.
其中$f = 0.2$為歸一化頻率[-1/2, 1/2],$\theta$為正弦波相位,服從[0,2$\pi$]的均勻分佈,$w(n)$為具有零均值和方差$\sigma^2 = 2$的高斯白噪聲。
求:
時域維納濾波器。假設濾波器為時域濾波器時$M=2$.
首先求解相關矩陣:
$x(n)$為廣義平穩隨機過程,可以計算其自相關函式:
${r_{xx}}\left( m \right) = \cos (2\pi fn)$
得到關於均方誤差的準則函式:
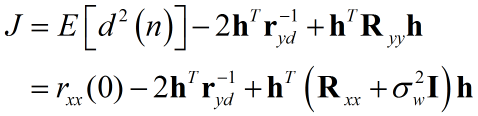
代入數值:
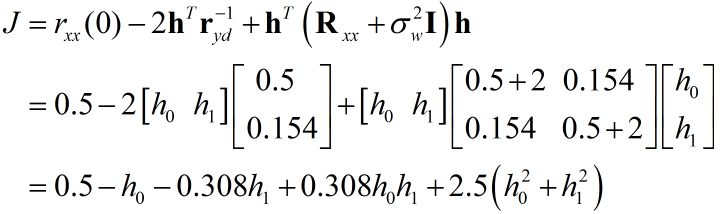
迭代的時候,可以保留矩陣的形式,也可以利用代數的形式,形式不同但本質相同,以矩陣為例:

得到梯度$\nabla J = - 2{\bf{r}}_{yd}^{ - 1} + 2\;{{\bf{R}}_{yy}}{\bf{h}}$.
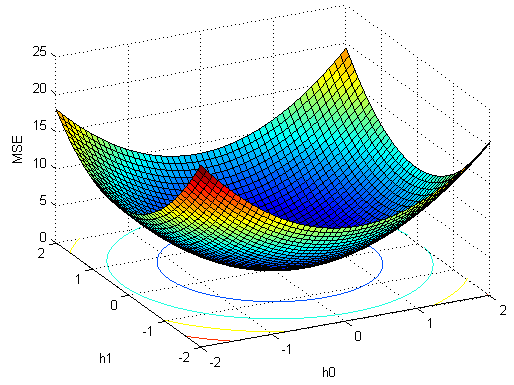
對應搜尋程式碼:
r_yd = [0.5 0.154]';
R_yy = [2.5 0.154;0.154 2.5];
h_est = [0 0]';
deltaJold = Inf;
mu = 0.001;
for i = 1:2000
deltaJ = -2*r_yd+2*R_yy*h_est;
if abs(deltaJ-deltaJold)<1e-5
break;
end
h_est = h_est - mu*deltaJ
deltaJold = deltaJ;
end
即可得出最優解$h = [0.197 , 0.0495]'$。
三、穩定性
上文中$\mu$取0.001,$\mu$如何取值才能保證梯度正常下降呢?事實上,如果$\mu$過大結果會往外發散而不是收斂於最優點。
${w_o} = \;{\bf{R}}_{_{yy}}^{ - 1}{\bf{r}}_{yd}^ - $
從而有:
![]() 記$c(n) = w_o - w(n)$:
記$c(n) = w_o - w(n)$:
$c(n + 1) = c(n)\left( {{\bf{I}} - 2\mu {{\bf{R}}_{yy}}} \right)$
對於正定矩陣,存在正交矩陣:
${{\bf{R}}_{yy}} = {\bf{Q\Lambda }}{{\bf{Q}}^{ - 1}}$
即${\bf{I}} - 2\mu {{\bf{R}}_{yy}}{\rm{ = }}{\bf{Q}}\left( {{\bf{I}} - 2\mu {\bf{\Lambda }}} \right){{\bf{Q}}^{ - 1}}$,為此保證最大特徵值小於1即可保證收斂:
![]()
如對應上面$h$的求解,$\frac{1}{{{\lambda _{\max }}}}= 0.3768$,用上面的程式容易驗證$\mu = 0.37$時滿足條件,可以收斂;$\mu = 0.38$則發散,無法得到最優值。
四、理論擴充套件
如果沿著曲線直接尋優,我們稱為:精確直線搜尋。如計算: :
:
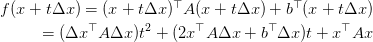
這是就是$\Delta x$與$x$固定後,該問題就是$t$的函式,易求解。但實際情況中,準則函式並不總是這麼理想,因此藉助近似的思路去尋優,成了一種更普適的方式,梯度下降法、牛頓法都是基於該思路。
這裡給出一個更簡單的例子$y = kx$的擬合問題,其中$k$未知。
首先給出結果圖:
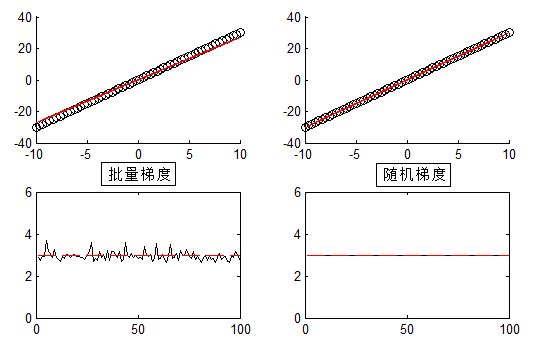
100組隨機試驗,未新增噪聲。
給出code:
N = 100;
a = zeros(1,N);
mu =0.002;
flag = 2;
for k = 1:N
xold = linspace(-10,10,60);
nums = randperm(length(xold));
x = xold(nums);
y = 3*x +2*randn(1,length(x));
switch flag
case 1
a_est = 0;
batch = 10;
for i=1:batch:length(x)
a_est = a_est+mu*(x(i:i+batch-1)*(y(i:i+batch-1)-a_est*x(i:i+batch-1)).');
end
case 2
a_est = 0;
batch = 1;
for i=1:batch:length(x)
a_est = a_est+mu*(x(i:i+batch-1)*(y(i:i+batch-1)-a_est*x(i:i+batch-1)).');
end
end
a(k) = a_est;
end
對於相關矩陣:來自統計均方誤差,但實際應用中通常無法得知概率分佈以及相關矩陣,通常是基於遍歷性假設,以便利用時間換取空間。即:
${{\bf{R}}_{yy}} \approx \frac{{{{\bf{y}}^T}{\bf{y}}}}{N}$
與之對應的統計誤差也不再是均方意義上,假設時間換空間的序列長$N$:

簡單來說:當$N$較大時,對應的梯度下降稱之為——批量(Batch)梯度下降,當$N=1$即每次來一個樣本,對應稱之為——隨機梯度下降。
通過上面的小程式可以得出兩點結論:
- 初始值
- 迭代步長
- 特徵尺寸(一維無此問題)
二者都對尋優產生影響。事實上對於高維資料,不同特徵尺寸不同,對尋優也有影響,通常需要分別對特徵進行歸一化。
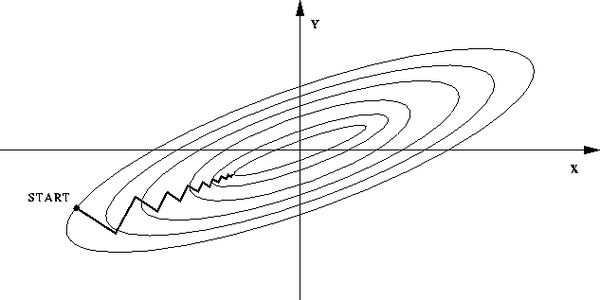
A-批量梯度下降
仍然以線性迴歸為例:
![]()
這裡$x_0 = 1$,給出準則函式,便於求導通常新增$1/2$:
![]()
求偏導:
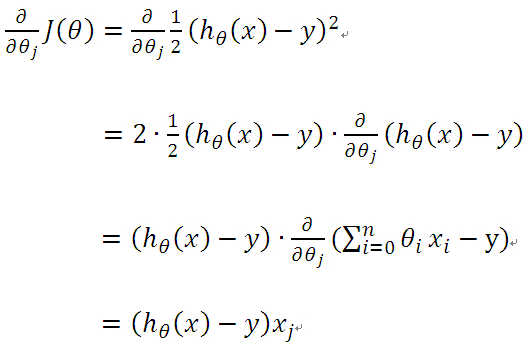
從而:
![]()
可以寫為:
![]()
迭代至滿足收斂條件即可求解。
B-隨機梯度下降
對應批量梯度下降,當$m = 1$即一次只接受/處理一個樣本,對應為隨機梯度下降。
事實上,當引入噪聲時,時間換空間只能是一種近似,即批量/隨機梯度下降的最優解,通常不是維納濾波的最優解。基於隨機梯度的最小均方誤差(Least mean square,LMS)通常稱為LMS演算法,以示與梯度下降的區別。
C-Newton-Raphson法
梯度下降法基於一階近似,如果二階逼近收斂是否會更快一些?即尋找梯度的梯度——走一步想兩步。
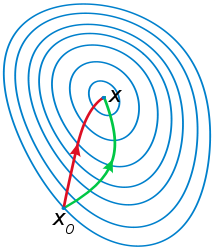
再次給出梯度下降的一階Taylor近似:
$f\left( {{\bf{x}} + \Delta {\bf{x}}} \right) \approx f\left( {\bf{x}} \right) + {\left( {\nabla f\left( {\bf{x}} \right)} \right)^T} \cdot \Delta {\bf{x}}$
給出二階Taylor近似:
![]()
${\nabla ^2}f\left( {\bf{x}} \right)$對應的矩陣稱為Hessian矩陣,該方法成為牛頓法(Newton),也稱Newton-Raphson法。
對於點$x_k$,選擇下降方向:

參考:
- Simon Haykin 《Adaptive Filter Theory Fourth Edition》.
- Philipos C.Loizou《speech enhancement theory and practice》.
- 張賢達《矩陣分析與應用》.
相關推薦
自適應濾波:梯度下降演算法
作者:桂。 時間:2017-04-01 06:39:15 宣告:歡迎被轉載,不過記得註明出處哦~ 【學習筆記07】 前言 西蒙.赫金的《自適應濾波器原理》第四版第四章:最速下降演算法。優化求解按照有/無約束分類:如投影梯度下降演算法((Gradient projection)便是有
機器學習筆記(一):梯度下降演算法,隨機梯度下降,正規方程
一、符號解釋 M 訓練樣本的數量 x 輸入變數,又稱特徵 y 輸出變數,又稱目標 (x, y) 訓練樣本,對應監督學習的輸入和輸出 表示第i組的x 表示第i組的y h(x)表示對應演算法的函式 是
自適應濾波:最小均方誤差濾波器(LMS、NLMS)
作者:桂。 時間:2017-04-02 08:08:31 宣告:歡迎被轉載,不過記得註明出處哦~ 【讀書筆記08】 前言 西蒙.赫金的《自適應濾波器原理》第四版第五、六章:最小均方自適應濾波器(LMS,Least Mean Square)以及歸一化最小均方自適應濾波器(NLMS,
自適應濾波:LMS/NLMS
前言 西蒙.赫金的《自適應濾波器原理》第四版第五、六章:最小均方自適應濾波器(LMS,Least Mean Square)以及歸一化最小均方自適應濾波器(NLMS,Normalized Least Mean Square)。全文包括: 1)LMS與維納濾波器(Wiener Filter
自適應濾波:維納濾波器——FIR及IIR設計
作者:桂。 時間:2017-03-23 06:28:45 【讀書筆記02】 前言 仍然是西蒙.赫金的《自適應濾波器原理》第四版,距離上次看這本書已經過去半個月,要抓點緊了。本文主要包括: 1)何為維納濾波器(Wiener Filter); 2)Wiener濾波器的推導;
斯坦福CS229機器學習課程筆記一:線性迴歸與梯度下降演算法
機器學習三要素 機器學習的三要素為:模型、策略、演算法。 模型:就是所要學習的條件概率分佈或決策函式。線性迴歸模型 策略:按照什麼樣的準則學習或選擇最優的模型。最小化均方誤差,即所謂的 least-squares(在spss裡線性迴歸對應的模組就叫OLS即Ordinary Least Squares):
啟發式優化演算法:梯度下降法和梯度上升法
梯度下降演算法理論知識我們給出一組房子面積,臥室數目以及對應房價資料,如何從資料中找到房價y與面積x1和臥室數目x2的關係?本文旨在,通過數學推導的角度介紹梯度下降法 f
自適應濾波-----LMS(Least Mean Square)演算法
自適應濾波的意義所在 自適應濾波器解決非平穩的過程,因為實際訊號的統計特性可能是非平穩的或者是未知的。 自適應濾波器的特點: 1.沒有關於待提取資訊的先驗統計知識
大資料:Spark mlib(三) GradientDescent梯度下降演算法之Spark實現
1. 什麼是梯度下降?梯度下降法(英語:Gradient descent)是一個一階最優化演算法,通常也稱為最速下降法。 要使用梯度下降法找到一個函式的區域性極小值,必須向函式上當前點對應梯度(或者是近似梯度)的反方向的規定步長距離點進行迭代搜尋。先來看兩個函式:1. 擬合
機器學習演算法篇:從為什麼梯度方向是函式變化率最快方向詳談梯度下降演算法
梯度下降法是機器學習中常用的引數優化演算法,使用起來也是十分方便!很多人都知道梯度方向便是函式值變化最快的方向,但是有認真的思考過梯度方向是什麼方向,梯度方向為什麼是函式值變化最快的方向這些問題嘛,本文便以解釋為什麼梯度方向是函式值變化最快方向為引子引出對梯度
吳恩達機器學習 學習筆記 之 二 :代價函式和梯度下降演算法
二、 2-1 Model Representation 我們學習的第一個演算法是線性迴歸,接下來會講什麼樣的模型更重要,監督學習的過程是什麼樣子。 首先舉一個需要做預測的例子:住房價格上漲,預測房價,我們擁有某一城市的住房價格資料。基於這些資料,繪製圖形。 在已有房價資
機器學習-監督學習應用:梯度下降
矩陣 data width 最速下降法 數據 訓練 訓練數據 這樣的 最小 回歸與梯度下降: 回歸在數學上來說是給定一個點集,能夠用一條曲線去擬合之,如果這個曲線是一條直線,那就被稱為線性回歸,如果曲線是一條二次曲線,就被稱為二次回歸,回歸還有很多的變種,如locally
深度解讀最流行的優化算法:梯度下降
example 分別是 課程 拓展 高斯分布 正則 當前時間 lam 選擇 深度解讀最流行的優化算法:梯度下降 By 機器之心2016年11月21日 15:08 梯度下降法,是當今最流行的優化(optimization)算法,亦是至今最常用的優化神經網絡的方法。本文旨在
Spark MLib:梯度下降算法實現
測試結果 println tolerance eat print bre AC sim var 聲明:本文參考《 大數據:Spark mlib(三) GradientDescent梯度下降算法之Spark實現》 1. 什麽是梯度下降? 梯度下降法(英語:Gradient
梯度下降演算法過程詳細解讀
看了很多博文,一談到梯度下降,大多都在畫圖,類比“下山”。對於一開始想要了解“梯度下降”是個什麼玩意兒時,這種類比法是非常有助於理解的。但是,當我大概知道了梯度下降是什麼東西之後,我就好奇了,梯度下降究竟是怎樣尋找到模型的最優引數的?不能一想到梯度下降,腦海中就只有“下山”的畫面,“下山”不是目的,目的在
機器學習:梯度下降gradient descent
視屏地址:https://www.bilibili.com/video/av10590361/?p=6 引數優化方法:梯度下降法 learning rate learning rate : 選擇rate大小 1、自動調learning ra
吳恩達機器學習課程筆記02——處理房價預測問題(梯度下降演算法詳解)
建議記住的實用符號 符號 含義 m 樣本數目 x 輸入變數 y 輸出變數/目標變數
機器學習之--梯度下降演算法
貌似機器學習最繞不過去的演算法,是梯度下降演算法。這裡專門捋一下。 1. 什麼是梯度 有知乎大神已經解釋的很不錯,這裡轉載並稍作修改,加上自己的看法。先給出連結,畢竟轉載要說明出處嘛。為什麼梯度反方向是函式值區域性下降最快的方向? 因為高等數學都忘光了,先從導數/偏倒數/方向
深入瞭解機器學習之降低損失 (Reducing Loss):梯度下降法
迭代方法圖(圖 1)包含一個標題為“計算引數更新”的華而不實的綠框。現在,我們將用更實質的方法代替這種華而不實的演算法。 假設我們有時間和計算資源來計算 的所有可能值的損失。對於我們一直在研究的迴歸問題,所產生的損失與 的圖形始終是凸形。換言之,圖形始終是碗狀圖,如下所示: 圖 2
二叔看ML第一:梯度下降
原理 梯度下降是一個很常見的通過迭代求解函式極值的方法,當函式非常複雜,通過求導尋找極值很困難時可以通過梯度下降法求解。梯度下降法流程如下: 上圖中,用大寫字母表示向量,用小寫字母表示標量。 假設某人想入坑,他站在某點,他每移動一小步,都朝著他所在點的梯度的負方向移動,這樣能保證他儘快入坑,因為某個