
大白話講解BP演算法
最近在看深度學習的東西,一開始看的吳恩達的UFLDL教程,有中文版就直接看了,後來發現有些地方總是不是很明確,又去看英文版,然後又找了些資料看,才發現,中文版的譯者在翻譯的時候會對省略的公式推導過程進行補充,但是補充的又是錯的,難怪覺得有問題。反向傳播法其實是神經網路的基礎了,但是很多人在學的時候總是會遇到一些問題,或者看到大篇的公式覺得好像很難就退縮了,其實不難,就是一個鏈式求導法則反覆用。如果不想看公式,可以直接把數值帶進去,實際的計算一下,體會一下這個過程之後再來推導公式,這樣就會覺得很容易了。
說到神經網路,大家看到這個圖應該不陌生:
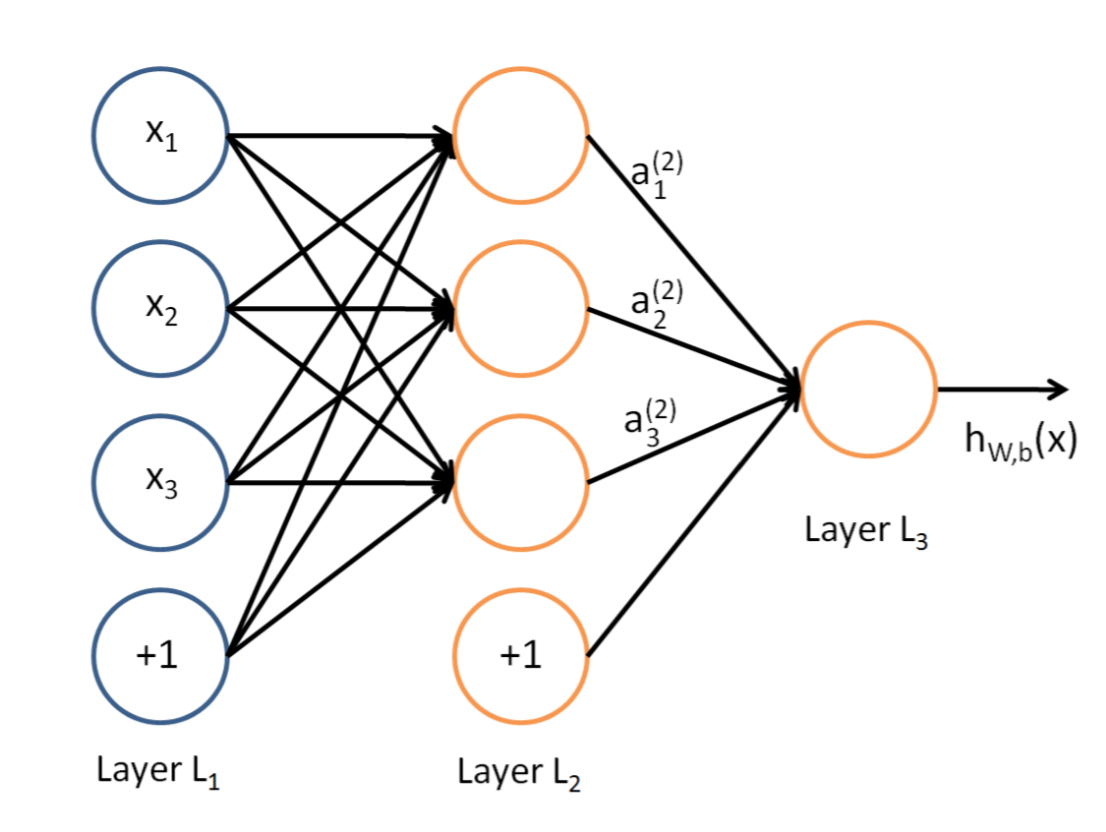
這是典型的三層神經網路的基本構成,Layer L1是輸入層,Layer L2是隱含層,Layer L3是隱含層,我們現在手裡有一堆資料{x1,x2,x3,…,xn},輸出也是一堆資料{y1,y2,y3,…,yn},現在要他們在隱含層做某種變換,讓你把資料灌進去後得到你期望的輸出。如果你希望你的輸出和原始輸入一樣,那麼就是最常見的自編碼模型(Auto-Encoder)。可能有人會問,為什麼要輸入輸出都一樣呢?有什麼用啊?其實應用挺廣的,在影象識別,文字分類等等都會用到,我會專門再寫一篇Auto-Encoder的文章來說明,包括一些變種之類的。如果你的輸出和原始輸入不一樣,那麼就是很常見的人工神經網路了,相當於讓原始資料通過一個對映來得到我們想要的輸出資料,也就是我們今天要講的話題。
本文直接舉一個例子,帶入數值演示反向傳播法的過程,公式的推導等到下次寫Auto-Encoder的時候再寫,其實也很簡單,感興趣的同學可以自己推導下試試:)(注:本文假設你已經懂得基本的神經網路構成,如果完全不懂,可以參考Poll寫的筆記:)
假設,你有這樣一個網路層:

第一層是輸入層,包含兩個神經元i1,i2,和截距項b1;第二層是隱含層,包含兩個神經元h1,h2和截距項b2,第三層是輸出o1,o2,每條線上標的wi是層與層之間連線的權重,啟用函式我們預設為sigmoid函式。
現在對他們賦上初值,如下圖:
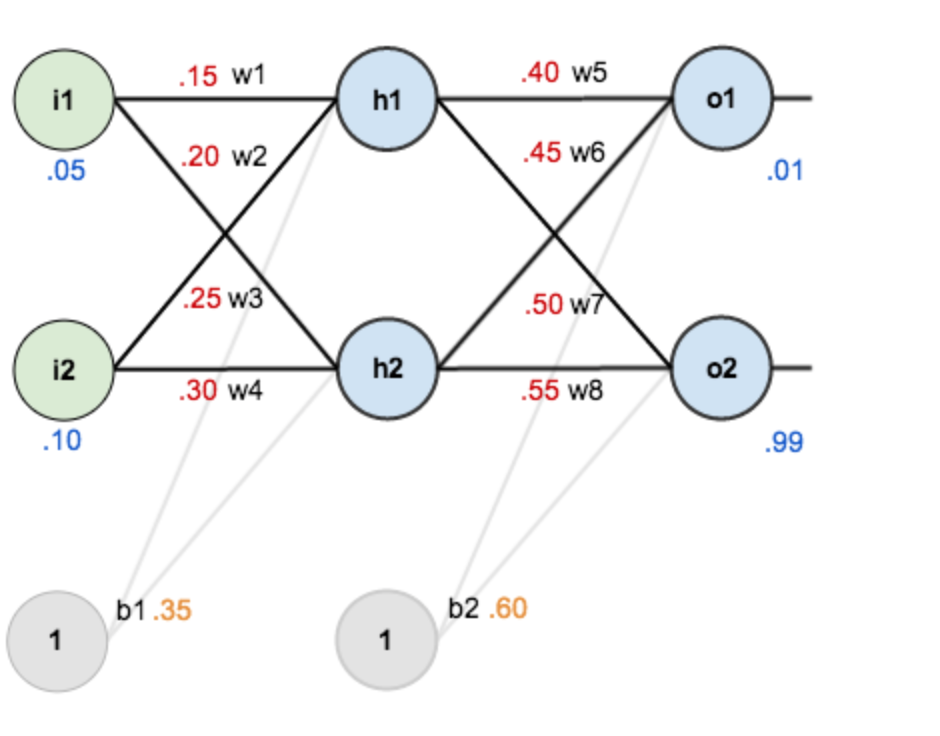
其中,輸入資料 i1=0.05,i2=0.10;
輸出資料 o1=0.01,o2=0.99;
初始權重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
w5=0.40,w6=0.45,w7=0.50,w8=0.55
目標:給出輸入資料i1,i2(0.05和0.10),使輸出儘可能與原始輸出o1,o2(0.01和0.99)接近。
Step 1 前向傳播
1.輸入層—->隱含層:
計算神經元h1的輸入加權和:

神經元h1的輸出o1:(此處用到啟用函式為sigmoid函式):
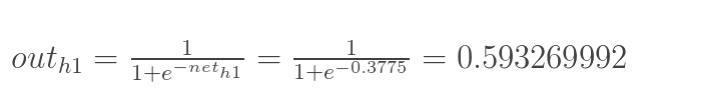
同理,可計算出神經元h2的輸出o2:
![]()
2.隱含層—->輸出層:
計算輸出層神經元o1和o2的值:

![]()
這樣前向傳播的過程就結束了,我們得到輸出值為[0.75136079 , 0.772928465],與實際值[0.01 , 0.99]相差還很遠,現在我們對誤差進行反向傳播,更新權值,重新計算輸出。
Step 2 反向傳播
1.計算總誤差
總誤差:(square error)
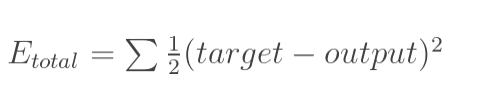
但是有兩個輸出,所以分別計算o1和o2的誤差,總誤差為兩者之和:


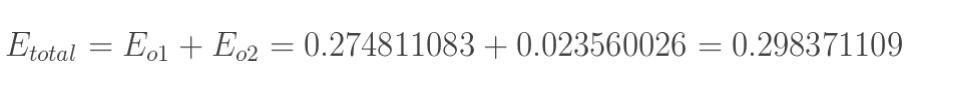
2.隱含層—->輸出層的權值更新:
以權重引數w5為例,如果我們想知道w5對整體誤差產生了多少影響,可以用整體誤差對w5求偏導求出:(鏈式法則)

下面的圖可以更直觀的看清楚誤差是怎樣反向傳播的:

現在我們來分別計算每個式子的值:
計算![]() :
:

計算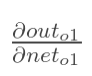 :
:

(這一步實際上就是對sigmoid函式求導,比較簡單,可以自己推導一下)
計算 :
:
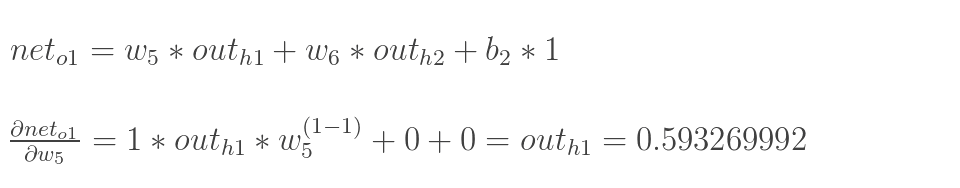
最後三者相乘:

這樣我們就計算出整體誤差E(total)對w5的偏導值。
回過頭來再看看上面的公式,我們發現:

為了表達方便,用![]() 來表示輸出層的誤差:
來表示輸出層的誤差:

因此,整體誤差E(total)對w5的偏導公式可以寫成:

如果輸出層誤差計為負的話,也可以寫成:

最後我們來更新w5的值:
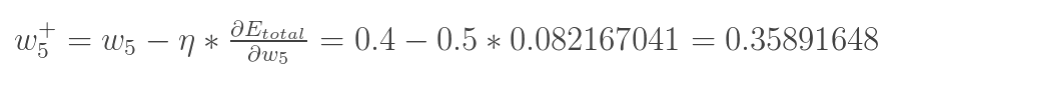
(其中,![]() 是學習速率,這裡我們取0.5)
是學習速率,這裡我們取0.5)
同理,可更新w6,w7,w8:

3.隱含層—->隱含層的權值更新:
方法其實與上面說的差不多,但是有個地方需要變一下,在上文計算總誤差對w5的偏導時,是從out(o1)—->net(o1)—->w5,但是在隱含層之間的權值更新時,是out(h1)—->net(h1)—->w1,而out(h1)會接受E(o1)和E(o2)兩個地方傳來的誤差,所以這個地方兩個都要計算。
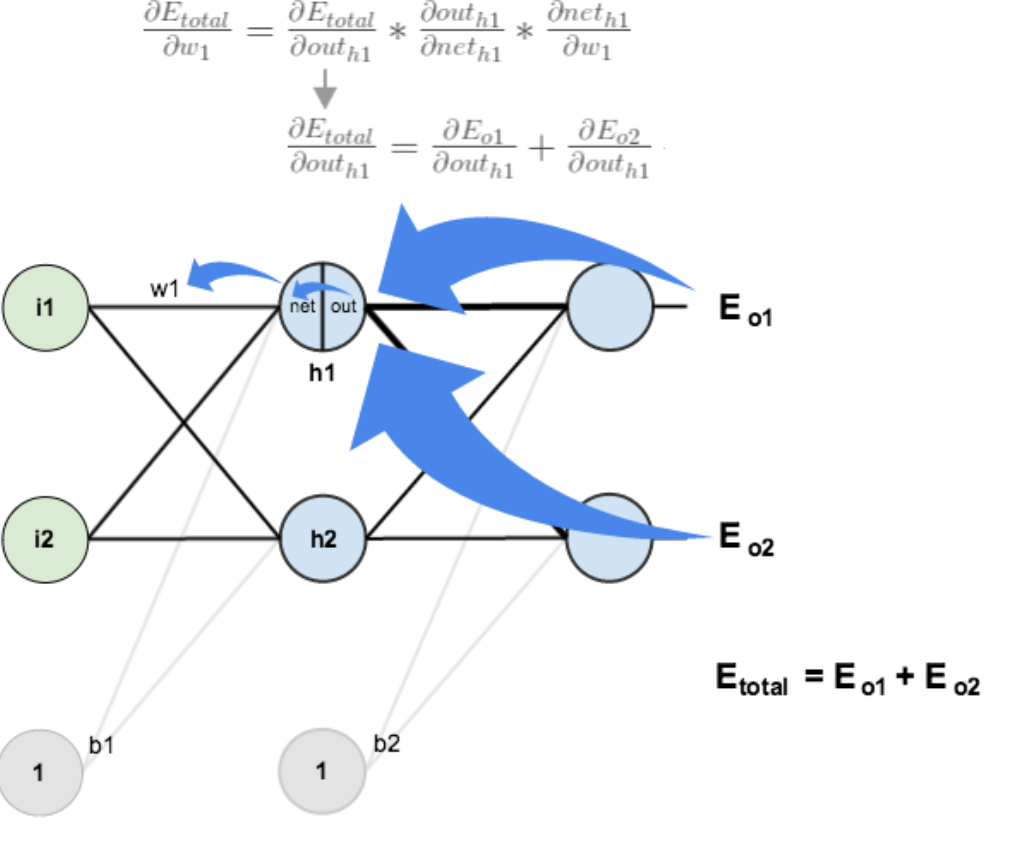
計算![]() :
:

先計算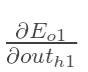 :
:
![]()
![]()
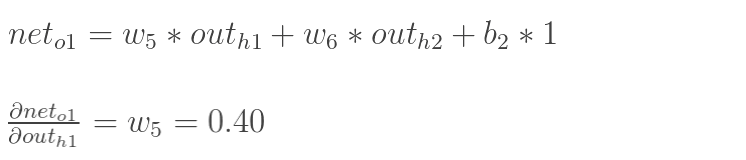
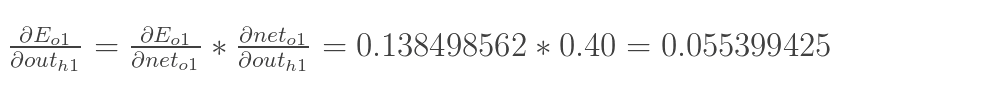
同理,計算出:
![]()
兩者相加得到總值:
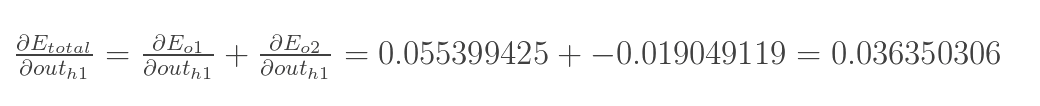
再計算![]() :
:

再計算![]() :
:

最後,三者相乘:

為了簡化公式,用sigma(h1)表示隱含層單元h1的誤差:

最後,更新w1的權值:
![]()
同理,額可更新w2,w3,w4的權值:

這樣誤差反向傳播法就完成了,最後我們再把更新的權值重新計算,不停地迭代,在這個例子中第一次迭代之後,總誤差E(total)由0.298371109下降至0.291027924。迭代10000次後,總誤差為0.000035085,輸出為[0.015912196,0.984065734](原輸入為[0.01,0.99]),證明效果還是不錯的。
程式碼(Python):

1 #coding:utf-8 2 import random 3 import math 4 5 # 6 # 引數解釋: 7 # "pd_" :偏導的字首 8 # "d_" :導數的字首 9 # "w_ho" :隱含層到輸出層的權重係數索引 10 # "w_ih" :輸入層到隱含層的權重係數的索引 11 12 class NeuralNetwork: 13 LEARNING_RATE = 0.5 14 15 def __init__(self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None, hidden_layer_bias = None, output_layer_weights = None, output_layer_bias = None): 16 self.num_inputs = num_inputs 17 18 self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias) 19 self.output_layer = NeuronLayer(num_outputs, output_layer_bias) 20 21 self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights) 22 self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights) 23 24 def init_weights_from_inputs_to_hidden_layer_neurons(self, hidden_layer_weights): 25 weight_num = 0 26 for h in range(len(self.hidden_layer.neurons)): 27 for i in range(self.num_inputs): 28 if not hidden_layer_weights: 29 self.hidden_layer.neurons[h].weights.append(random.random()) 30 else: 31 self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num]) 32 weight_num += 1 33 34 def init_weights_from_hidden_layer_neurons_to_output_layer_neurons(self, output_layer_weights): 35 weight_num = 0 36 for o in range(len(self.output_layer.neurons)): 37 for h in range(len(self.hidden_layer.neurons)): 38 if not output_layer_weights: 39 self.output_layer.neurons[o].weights.append(random.random()) 40 else: 41 self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num]) 42 weight_num += 1 43 44 def inspect(self): 45 print('------') 46 print('* Inputs: {}'.format(self.num_inputs)) 47 print('------') 48 print('Hidden Layer') 49 self.hidden_layer.inspect() 50 print('------') 51 print('* Output Layer') 52 self.output_layer.inspect() 53 print('------') 54 55 def feed_forward(self, inputs): 56 hidden_layer_outputs = self.hidden_layer.feed_forward(inputs) 57 return self.output_layer.feed_forward(hidden_layer_outputs) 58 59 def train(self, training_inputs, training_outputs): 60 self.feed_forward(training_inputs) 61 62 # 1. 輸出神經元的值 63 pd_errors_wrt_output_neuron_total_net_input = [0] * len(self.output_layer.neurons) 64 for o in range(len(self.output_layer.neurons)): 65 66 # ∂E/∂zⱼ 67 pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o]) 68 69 # 2. 隱含層神經元的值 70 pd_errors_wrt_hidden_neuron_total_net_input = [0] * len(self.hidden_layer.neurons) 71 for h in range(len(self.hidden_layer.neurons)): 72 73 # dE/dyⱼ = Σ ∂E/∂zⱼ * ∂z/∂yⱼ = Σ ∂E/∂zⱼ * wᵢⱼ 74 d_error_wrt_hidden_neuron_output = 0 75 for o in range(len(self.output_layer.neurons)): 76 d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h] 77 78 # ∂E/∂zⱼ = dE/dyⱼ * ∂zⱼ/∂ 79 pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input() 80 81 # 3. 更新輸出層權重係數 82 for o in range(len(self.output_layer.neurons)): 83 for w_ho in range(len(self.output_layer.neurons[o].weights)): 84 85 # ∂Eⱼ/∂wᵢⱼ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢⱼ 86 pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho) 87 88 # Δw = α * ∂Eⱼ/∂wᵢ 89 self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight 90 91 # 4. 更新隱含層的權重係數 92 for h in range(len(self.hidden_layer.neurons)): 93 for w_ih in range(len(self.hidden_layer.neurons[h].weights)): 94 95 # ∂Eⱼ/∂wᵢ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢ 96 pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih) 97 98 # Δw = α * ∂Eⱼ/∂wᵢ 99 self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight 100 101 def calculate_total_error(self, training_sets): 102 total_error = 0 103 for t in range(len(training_sets)): 104 training_inputs, training_outputs = training_sets[t] 105 self.feed_forward(training_inputs) 106 for o in range(len(training_outputs)): 107 total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o]) 108 return total_error 109 110 class NeuronLayer: 111 def __init__(self, num_neurons, bias): 112 113 # 同一層的神經元共享一個截距項b 114 self.bias = bias if bias else random.random() 115 116 self.neurons = [] 117 for i in range(num_neurons): 118 self.neurons.append(Neuron(self.bias)) 119 120 def inspect(self): 121 print('Neurons:', len(self.neurons)) 122 for n in range(len(self.neurons)): 123 print(' Neuron', n) 124 for w in range(len(self.neurons[n].weights)): 125 print(' Weight:', self.neurons[n].weights[w]) 126 print(' Bias:', self.bias) 127 128 def feed_forward(self, inputs): 129 outputs = [] 130 for neuron in self.neurons: 131 outputs.append(neuron.calculate_output(inputs)) 132 return outputs 133 134 def get_outputs(self): 135 outputs = [] 136 for neuron in self.neurons: 137 outputs.append(neuron.output) 138 return outputs 139 140 class Neuron: 141 def __init__(self, bias): 142 self.bias = bias 143 self.weights = [] 144 145 def calculate_output(self, inputs): 146 self.inputs = inputs 147 self.output = self.squash(self.calculate_total_net_input()) 148 return self.output 149 150 def calculate_total_net_input(self): 151 total = 0 152 for i in range(len(self.inputs)): 153 total += self.inputs[i] * self.weights[i] 154 return total + self.bias 155 156 # 啟用函式sigmoid 157 def squash(self, total_net_input): 158 return 1 / (1 + math.exp(-total_net_input)) 159 160 161 def calculate_pd_error_wrt_total_net_input(self, target_output): 162 return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input(); 163 164 # 每一個神經元的誤差是由平方差公式計算的 165 def calculate_error(self, target_output): 166 return 0.5 * (target_output - self.output) ** 2 167 168 169 def calculate_pd_error_wrt_output(self, target_output): 170 return -(target_output - self.output) 171 172 173 def calculate_pd_total_net_input_wrt_input(self): 174 return self.output * (1 - self.output) 175 176 177 def calculate_pd_total_net_input_wrt_weight(self, index): 178 return self.inputs[index] 179 180 181 # 文中的例子: 182 183 nn = NeuralNetwork(2, 2, 2, hidden_layer_weights=[0.15, 0.2, 0.25, 0.3], hidden_layer_bias=0.35, output_layer_weights=[0.4, 0.45, 0.5, 0.55], output_layer_bias=0.6) 184 for i in range(10000): 185 nn.train([0.05, 0.1], [0.01, 0.09]) 186 print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.09]]]), 9)) 187 188 189 #另外一個例子,可以把上面的例子註釋掉再執行一下: 190 191 # training_sets = [ 192 # [[0, 0], [0]], 193 # [[0, 1], [1]], 194 # [[1, 0], [1]], 195 # [[1, 1], [0]] 196 # ] 197 198 # nn = NeuralNetwork(len(training_sets[0][0]), 5, len(training_sets[0][1])) 199 # for i in range(10000): 200 # training_inputs, training_outputs = random.choice(training_sets) 201 # nn.train(training_inputs, training_outputs) 202 # print(i, nn.calculate_total_error(training_sets))
最後寫到這裡就結束了,現在還不會用latex編輯數學公式,本來都直接想寫在草稿紙上然後掃描了傳上來,但是覺得太影響閱讀體驗了。以後會用公式編輯器後再重把公式重新編輯一遍。穩重使用的是sigmoid啟用函式,實際還有幾種不同的啟用函式可以選擇,具體的可以參考文獻[3],最後推薦一個線上演示神經網路變化的網址:http://www.emergentmind.com/neural-network,可以自己填輸入輸出,然後觀看每一次迭代權值的變化,很好玩~如果有錯誤的或者不懂的歡迎留言:)
參考文獻:
1.Poll的筆記:http://www.cnblogs.com/maybe2030/p/5597716.html#3457159 )
2.Rachel_Zhang:http://blog.csdn.net/abcjennifer/article/details/7758797
3.http://www.cedar.buffalo.edu/%7Esrihari/CSE574/Chap5/Chap5.3-BackProp.pdf
4.https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
相關推薦
大白話講解BP演算法
最近在看深度學習的東西,一開始看的吳恩達的UFLDL教程,有中文版就直接看了,後來發現有些地方總是不是很明確,又去看英文版,然後又找了些資料看,才發現,中文版的譯者在翻譯的時候會對省略的公式推導過程進行補充,但是補充的又是錯的,難怪覺得有問題。反向傳播法其實是
大白話講解Promise
open hid 原來 一個數 get 狀態 正常 time 處理 去年6月份, ES2015正式發布(也就是ES6,ES6是它的乳名),其中Promise被列為正式規範。作為ES6中最重要的特性之一,我們有必要掌握並理解透徹。本文將由淺到深,講解Promise的基本概念與
大白話講解Promise(一)
適合 copy 並不會 我不 發布 應該 優勢 9.png fail 契約與雙重定義: 調用約定; 處理方案。 去年6月份, ES2015正式發布(也就是ES6,ES6是它的乳名),其中Promise被列為正式規範。作為ES6中最重要的特性之一,我們有必要掌握並理解透徹
【NLP】大白話講解word2vec到底在做些什麽
fill href 關系 單元 form 理解 只有一個 selector convert 轉載自:http://blog.csdn.net/mylove0414/article/details/61616617 詞向量 word2vec也叫word embedding
BP 演算法手動實現
github部落格傳送門 csdn部落格傳送門 本章所需知識: numpy matplotlib 資料下載連結: 深度學習基礎網路模型(mnist手寫體識別資料集) 梯度下降 BP 演算法手動實現 import numpy as np import matplotlib.pyplot
AIOPS最全講解TextRank演算法博文彙總
CSDN部落格 自然語言處理入門(8)——TextRank jieba結巴分詞–關鍵詞抽取(核心詞抽取) textrank演算法原理與提取關鍵詞、自動提取摘要PYTHON TextRank演算法的基本原理及textrank4zh使用例項 基於TextRank的關鍵詞提取演算法 TextR
深度學習BP演算法 BackPropagation以及詳細例子解析
反向傳播演算法是多層神經網路的訓練中舉足輕重的演算法,本文著重講解方向傳播演算法的原理和推導過程。因此對於一些基本的神經網路的知識,本文不做介紹。在理解反向傳播演算法前,先要理解神經網路中的前饋神經網路演算法。 前饋神經網路 如下圖,是一個多層神
神經網路和BP演算法推導
我的原文:www.hijerry.cn/p/53364.htm… 感知機 感知機(perceptron)於1957年由Rosenblatt提出,是一種二分類線性模型。感知機以樣本特徵向量作為輸入,輸出為預測類別,取正、負兩類。感知機最終學習到的是將輸入空間(特徵空間)劃分為正、負兩類的分離超平面,屬於判別
大白話講解ThreadLocal的原理
ThreadLocal顧名思義,本地執行緒,可以理解為本地執行緒變數,說白了就是操作本地執行緒的區域性變數。 下面我們通過原始碼進行說明: 首先,我們看一下ThreadLocal的set方法原始碼實現: public void set(T value) { Thr
反向傳導(BP)演算法
假設我們有一個固定樣本集 ,它包含 個樣例。我們可以用批量梯度下降法來求解神經網路。具體來講,對於單個樣例 ,其代價函式為: 這是一個(二分之一的)方差代價函式。給定一個包含 個樣例的資料集,我們可以定義整體代價函式為: 以上關於定
深度學習 --- BP演算法詳解(誤差反向傳播演算法)
本節開始深度學習的第一個演算法BP演算法,本打算第一個演算法為單層感知器,但是感覺太簡單了,不懂得找本書看看就會了,這裡簡要的介紹一下單層感知器: 圖中可以看到,單層感知器很簡單,其實本質上他就是線性分類器,和機器學習中的多元線性迴歸的表示式差不多,因此它具有多元線性迴歸的優點和缺點。
深度學習 --- BP演算法詳解(BP演算法的優化)
上一節我們詳細分析了BP網路的權值調整空間的特點,深入分析了權值空間存在的兩個問題即平坦區和區域性最優值,也詳細探討了出現的原因,本節將根據上一節分析的原因進行改進BP演算法,本節先對BP存在的缺點進行全面的總結,然後給出解決方法和思路,好,下面正式開始本節的內容: BP演算法可以完成非線性
深度學習 --- BP演算法詳解(流程圖、BP主要功能、BP演算法的侷限性)
上一節我們詳細推倒了BP演算法的來龍去脈,請把原理一定要搞懂,不懂的請好好理解BP演算法詳解,我們下面就直接把上一節推匯出的權值調整公式拿過來,然後給出程式流程圖,該流程圖是嚴格按照上一節的權值更新過程寫出的,因此稱為標準的BP演算法,標準的BP演算法中,每輸入一個樣本,都要回傳誤差並調整權值,
大白話講解word2vec到底在做些什麼
轉自https://blog.csdn.net/mylove0414/article/details/61616617 詞向量 word2vec也叫word embeddings,中文名“詞向量”,作用就是將自然語言中的字詞轉為計算機可以理解的稠密向量(Dense Vect
反向傳播演算法(BP演算法)
BP演算法(即反向傳播演算法),適合於多層神經元網路的一種學習演算法,它建立在梯度下降法的基礎上。BP網路的輸入輸出關係實質上是一種對映關係:一個n輸入m輸出的BP神經網路所完成的功能是從n維歐氏空間向m維歐氏空間中一有限域的連續對映,這一對映具有高度非線性。它的資訊處理能力來源於簡單非線性函式的多
西瓜書 課後習題5.5 標準bp演算法,累計bp演算法
import numpy as np def dataSet(): ''' 西瓜3.0資料集離散化 ''' X = np.mat('2,3,3,2,1,2,3,3,3,2,1,1,2,1,3,1,2;\ 1,1,1,1,1,2,2,2,2,
反向傳播(BP演算法)python實現
反向傳播(BP演算法)python實現 1、BP演算法描述 BP演算法就是反向傳播,要輸入的資料經過一個前向傳播會得到一個輸出,但是由於權重的原因,所以其輸出會和你想要的輸出有差距,這個時候就需要進行反向傳播,利用梯度下降,對所有的權重進行更新,這樣的話在進行前向傳播就會發現其輸
BP演算法和RBF演算法的網路逼近
BP演算法 RBF 高斯徑向基函式 RBF模擬例項 參考資料 最近開始做自己的畢業設計,開始記錄相關的智慧控
大白話講解Promise(三)搞懂jquery中的Promise
前兩篇我們講了ES6中的Promise以及Promise/A+規範,在Promise的知識體系中,jquery當然是必不可少的一環,所以本篇就來講講jquery中的Promise,也就是我們所知道的Deferred物件。 事實上,在此之前網上有很多文章在講jq
用通俗易懂的大白話講解Map/Reduce原理
Hadoop簡介 Hadoop就是一個實現了Google雲端計算系統的開源系統,包括平行計算模型Map/Reduce,分散式檔案系統HDFS,以及分散式資料庫Hbase,同時Hadoop的相關專案也很豐富,包括ZooKeeper,Pig,Chukwa,Hive,Hbase,