
白話貝葉斯理論及在足球比賽結果預測中的應用和C#實現
貝葉斯分類的基礎是概率推理,就是在各種條件的存在不確定,僅知其出現概率的情況下,如何完成推理和決策任務。概率推理是與確定性推理相對應的。而樸素貝葉斯分類器是基於獨立假設的,即假設樣本每個特徵與其他特徵都不相關。舉個例子,如果一種水果其具有紅,圓,直徑大概4英寸等特徵,該水果可以被判定為是蘋果。儘管這些特徵相互依賴或者有些特徵由其他特徵決定,然而樸素貝葉斯分類器認為這些屬性在判定該水果是否為蘋果的概率分佈上獨立的。樸素貝葉斯分類器依靠精確的自然概率模型,在有監督學習的樣本集中能獲取得非常好的分類效果。在許多實際應用中,樸素貝葉斯模型引數估計使用最大似然估計方法,換而言之樸素貝葉斯模型能工作並沒有用到貝葉斯概率
2.1 樸素貝葉斯分類的定義


注意:上述的推導有2個地方比較難懂,1個是把分母p(x)去掉了,應該好理解,分母都一樣,比較的時候,直接比較分子就可以了。另外一個是為什麼這個公式是成立的:
P(x|yi) = P(a1|yi)*P(a2|yi)*...*P(aj|yi)
這個公式的成立是因為各個屬性a1,a2,..,aj都是獨立的,才能成立。
根據上述原理,樸素貝葉斯分類主要分為三個階段:
1.準備階段,這個階段的任務是為樸素貝葉斯分類做必要的準備,主要工作是根據具體情況確定特徵屬性,並對每個特徵屬性進行適當劃分,然後由人工對一部分待分類項進行分類,形成訓練樣本集合。這一階段的輸入是所有待分類資料,輸出是特徵屬性和訓練樣本。這一階段是整個樸素貝葉斯分類中唯一需要人工完成的階段,其質量對整個過程將有重要影響,分類器的質量很大程度上由特徵屬性、特徵屬性劃分及訓練樣本質量決定。
2.分類器訓練階段
3.應用階段。這個階段的任務是使用分類器對待分類項進行分類,其輸入是分類器和待分類項,輸出是待分類項與類別的對映關係。這一階段也是機械性階段,由程式完成。
至於貝葉斯的其他問題如 估計類別下特殊屬性劃分的條件概率,以及分類器的評價問題,我認為對於初學者可以暫時跳過,等把基本流程理順了,懂了,越到更多的問題後再回過頭來反思後,按需學習。
2.2 樸素貝葉斯分類例項:檢測不真實賬號
這個例子完全取自於部落格園網友:leoo2sk,的文章“演算法雜貨鋪——分類演算法之樸素貝葉斯分類”,因為這個例子很短,而且有現成資料,手動計算量很小,所以我認為非常適合在這裡使用。所以冒昧借用一下,同時3.3節中,我會介紹一個更加複雜的樸素貝葉斯分類器的程式碼。這個例子適合入門,而且最好是動手拿筆在紙上畫一畫,這樣更容易理解,光看公式和資料雖然簡單,但未必能瞭解整個過程,要想自己寫出類似的程式碼,這個過程還是要清楚的,至少我是這麼過來的。看看SNS社群不真實帳號問題
對於SNS社群來說,不真實賬號(使用虛假身份或使用者的小號)是一個普遍存在的問題,作為SNS社群的運營商,希望可以檢測出這些不真實賬號,從而在一些運營分析報告中避免這些賬號的干擾,亦可以加強對SNS社群的瞭解與監管。如果通過純人工檢測,需要耗費大量的人力,效率也十分低下,如能引入自動檢測機制,必將大大提升工作效率。這個問題說白了,就是要將社群中所有賬號在真實賬號和不真實賬號兩個類別上進行分類。
下面我們一步一步的使用樸素貝葉斯實現這個過程。
2.2.1 準備階段:特徵屬性及劃分
1.首先設C=0表示真實賬號,C=1表示不真實賬號。其他例子中不一定只有2類,也可以是N個類別,只不過計算更復雜,要藉助計算機和程式了。
2.找出可以區分真實與不真實賬號的特徵屬性,實際應用中,特徵屬性的數量可能很多,劃分也會更細緻。作為例子,這裡只用少量的特徵屬性以及較粗的劃分,並對資料做了修改。同時我們也假設這3個屬性是獨立的,這是使用樸素貝葉斯的基本要求。
選擇三個特徵屬性,在SNS社群中這三項是可以直接從資料庫裡得到的。粗略劃分如下幾個區間:
a1:日誌數量/註冊天數,劃分:{a1<=0.05, 0.05<a1<0.2, a1>=0.2}
a2:好友數量/註冊天數,劃分:{a2<=0.1, 0.1<a2<0.8, a2>=0.8}
a3:是否使用真實頭像。 劃分:{a3=0(不是),a3=1(是)}
2.2.2 訓練階段:訓練樣本資料
這裡並沒有提供實際的資料,而是直接提供了相關整理後的資料,實際例子中,也應該是這樣,這些基礎資料是可以獲取得到的。
使用1萬個人工檢測過的賬號作為訓練樣本。我們根據上面特徵屬性的劃分計算每個類別的頻率以及各個類別在各個條件下的條件概率,以供後面的預測需要。
計算類別頻率
P(C=0) = 0.89; 也就說這1萬個人工檢測過的帳號中,有89%是真實的
P(C=1) = 0.11;人工檢測的帳號中,有11%是不真實的
計算條件概率
1)計算已知C=0的條件下,a1屬性屬於不同劃分類別的條件概率
P( a1<=0.05| C=0) = 0.3 ; 在帳號真實的情況下,日誌數量/註冊天數的值<=0.05的比例有30%
p(0.05<a1<0.2 | C=0) = 0.5 ;
P( a1 >=0.2 | C=0) = 0.2 ;
2)計算已知C=1的條件下,a1屬性屬於不同劃分類別的條件概率
P( a1<=0.05| C=1) = 0.8 ; 在帳號不真實的情況下,日誌數量/註冊天數的值<=0.05的比例有80%
p(0.05<a1<0.2 | C=1) = 0.1 ;
P( a1 >=0.2 | C=1) = 0.1 ;
3)計算已知C=0的條件下,a2屬性屬於不同劃分類別的條件概率
P( a2 <= 0.1 | C=0) = 0.1 ;
P( 0.1<a2<0.8| C=0) = 0.7 ;在帳號真實條件下,好友數量/註冊天數在0.1-0.8範圍的比例是70%
P( a2 >= 0.8 | C=0) = 0.2 ;
4)計算已知C=1的條件下,a2屬性屬於不同劃分類別的條件概率
P( a2 <= 0.1 | C=1) = 0.7 ;不真實條件下的帳號,好友數量在這個範圍是非常多的
P( 0.1<a2<0.8| C=1) = 0.2 ;
P( a2 >= 0.8 | C=1) = 0.1 ;
5)計算已知C=0的條件下,a3屬性屬於不同劃分類別的條件概率
P(a3 = 0 | C=0) = 0.2 ;
P(a3 = 1 | C=0) = 0.8 ;真實帳號中,使用真實影象的比例是80%
6)計算已知C=1的條件下,a3屬性屬於不同劃分類別的條件概率
P(a3 = 0 | C=1) = 0.9 ;不真實帳號中,使用不真實影象的比例是90%
P(a3 = 1 | C=1) = 0.1 ;
上面這些資料從樣本中可以直接統計得到。我也手動對幾個條件概率進行了解釋,我們假設還是比較符合真實情況的,雖然這個資料是原作者修正過的。
2.2.3 應用階段:獲取分類概率
根據上面貝葉斯公式得到的相關條件概率資料,那麼如何來進行一個實際的預測分類。假設我們有一個如下的預測需求:
某帳號使用非真實頭像,日誌數量與註冊天數的比率為0.1,好友數與註冊天數的比率為0.2。這些資料是從該資料庫直接獲取的。
那麼這個人的賬戶是真實賬戶 還是 不真實賬戶呢?相應的概率又有多少呢?
直接使用3.1節中的公式,我們計算在當前資料x發生的情況下,屬於不同類別的概率,這裡有2類,所以要計算一下2個東西:
要計算 P(C=0|x) 和 P(C=1|x)的概率,然後比較大小,取最大值所在的類別就是我們分類的類別。當然我們不一定非要分類,而是可以將求出的概率提供給客戶,作為一個參考值等等。而根據3.1節的推導,上述2個值的計算完整公式應該是下面這樣的:
P(C=0|x) = P(x|C=0)*P(C=0)
= P(a1|C=0)*P(a2|C=0)*P(a3|C=0)*P(C=0) 根據x的屬性範圍選擇對應的概率
= P(0.05<a1<0.2|C=0) * P(0.1<a2<0.8|C=0)*P(a3=0|C=0) *P(C=0)
= 0.5 * 0.7 * 0.2 * 0.89 = 0.0623
同理:
P(C=1|x) = P(0.05<a1<0.2|C=1) * P(0.1<a2<0.8|C=1)*P(a3=0|C=1) *P(C=1)
= 0.1 * 0.2 * 0.9 * 0.11 = 0.00198
所以根據屬性結果和計算,當事件X發生時,屬於C=0的概率要高得多,是C=1的30倍。因此我們有理由將這個帳號劃分為真實帳號的範疇。
當然實際中的情況可能更加複雜,計算量也更加大,樸素貝葉斯不一定能很好的完成複雜的任務。但有些時候,我們將檔案簡化為樸素貝葉斯也能收穫一些意外的東西。下面我們就來看將貝葉斯分類應用到足球彩票勝平負結果的預測中的情況。純C#程式碼。歡迎支援。
3.足球彩票的貝葉斯預測與C#實現
關於足球彩票預測的幾點說明:
1.本文分析的足球勝平負比賽的結果預測,採集的資料有近10年的全世界主要聯賽;
2.足球彩票的預測方法各種各樣,八仙過海各顯神通,我這裡也只是初步的測試,還有很多工作待完成,有沒有完善的地方大家也不要急。
3.足球比賽的結果不僅與球隊實力,狀態,傷病,彩票,天氣,還與場上的重大隨機因素有關,因此想完成預測100%準確是一個不可能的任務,我們只是想在歐賠的概率基礎上有少部分(5-10%)的提高,這樣才可以做很多有意義的事情。
4.準確的說,足球比賽的很多因素都是有關聯的,我也只是處於好奇,先使用了樸素貝葉斯來進行了一些工作,同時也在著手開始研究貝葉斯網路的預測方法,比較複雜,還在學習與堆碼中。
5.1場足球比賽的基本要點有:主隊,客隊,比分,結果,至於輔助的因素有很多,如賽前的主客隊積分,進球率,失球率,淨勝球等等。
6.本文使用的是資料庫ORM元件XCode,相關資料查詢及操作如果看不懂,可以參考本文部落格的文章,點選選單導航欄的:“X元件”進入目錄即可。
我們還是按照前面的步驟來逐步構造一個貝葉斯分類器,在這個過程中,也會講解相關細節,對於懂足球彩票的朋友,應該好懂,對於不懂,只是想了解的朋友,可以看看思路,瞭解初步過程,沒必要了解細節。
3.1 選擇屬性與獲取訓練資料
為了簡單起見,我暫時只選取2個屬性:主客隊總積分的差;主隊主場積分與客隊客場積分的差;結果有勝平負3種類別,分別記為(3,1,0)。屬性集的劃分我們在程式中動態獲取,這樣可以計算各種不同劃分的準確率,更加方便,這和上面的例子是不一樣的。當然上面的例子也可以這樣做,只是一個小的技巧而已。
在這個測試過程中,我們是選取前N輪的比賽場次資料,然後對後M輪的結果進行預測。所有首先要從資料庫獲取貝葉斯的訓練資料,看程式碼:
/// <summary>獲取指定賽季,指定輪之間的比賽資料作為貝葉斯分類的訓練集合</summary> /// <param name="seasonId">賽季編號</param> /// <param name="roundIdL">起始輪號</param> /// <param name="roundIdH">截至輪號</param> /// <returns>返回貝葉斯需要的資料格式型別(自定義的)</returns> static List<BayesDS> GetDataBySeason(Int32 seasonId,Int32 roundIdL,Int32 roundIdH) { var season = SeasonInfoDc.FindBySeasonId(seasonId); GameScreenDc.SetDbConnName(season.EventName); EventRanking.SetDbConnName(season.EventName); //獲取所有場次 var games = GameScreenDc.FindAll(GameScreenDc._.SeasonId == seasonId & GameScreenDc._.RoundId >= roundIdL & GameScreenDc._.RoundId <= roundIdH, GameScreenDc._.RoundId.Asc(), null, 0, 0); //迴圈每場進行查詢,組合 List<BayesDS> res = new List<BayesDS>(); foreach (var item in games) { //查詢當前主客球隊,上一輪後的積分物件 var home = EventRanking.Find(EventRanking._.SeasonId == seasonId & EventRanking._.TeamId == item.HomeId & EventRanking._.RoundId == item.RoundId -1); var visit = EventRanking.Find(EventRanking._.SeasonId == seasonId & EventRanking._.TeamId == item.VisiteId & EventRanking._.RoundId == item.RoundId -1); double[] temp = new double[]{(double)(home.TotalScore - visit.TotalScore)/*總積分差*/, (double)(home.HomeScore - visit.VisitScore)/*主隊主場積分-客隊客場積分*/,
item.Result};
res.Add(BayesDS.Create(item,temp));
}
return res;
}
雖然只有2個引數,也需要進行劃分,由於積分都是正整數,而且一般球隊的積分差距不是特別大,為了測試不同劃分的情況,我們選擇手動輸入劃分點,進行屬性的劃分,下面是函式,根據輸入的點,自動確定劃分區間的:
1 /// <summary>獲取屬性分割的區間,根據斷點確定 ,data應該是從小到大的點排列</summary> 2 /// <returns></returns> 3 static double[][] GetRulesByPoint(List<double> data) 4 { 5 double[][] res = new double[data.Count +1][]; 6 res[0] = new double[] {-1000,data[0] };//下限-1000,不可能達到 7 for (int i = 0; i < data.Count-1; i++) 8 { 9 res[i + 1] = new double[] { data[i], data[i +1] }; 10 } 11 res[data.Count ] = new double[] {data[data.Count-1],1000 };//上限足夠大,不可能達到 12 return res; 13 }
3.2 建立貝葉斯分類預測模型
有了資料和思路後,下一步就是要在C#中建立一個貝葉斯分類器,傳遞資料,和劃分集然後才能進行預測。模型的定義如要有以下幾點:
1.幾個基本的屬性。注意字典儲存條件概率,直接全部計算,對資料量大的情況,可能會吃不消,應該按需計算比較好。不過這裡是測試,無所謂了。先看看效果才行。
1 #region 屬性 2 /// <summary>測試資料:分別為屬性值,最後1個為結果類別</summary> 3 public List<double[]> data { get; set; } 4 /// <summary>對應的屬性劃分集合</summary> 5 public List<double[][]> rules { get; set; } 6 /// <summary>所有的類別</summary> 7 public List<Int32> C { get; set; } 8 /// <summary>類別的比例字典</summary> 9 public Dictionary<Int32,double> C_Ratio { get; set; } 10 /// <summary>條件概率字典</summary> 11 public Dictionary<String, double> ConRatio { get; set; } 12 #endregion
2.模型建構函式,主要是模型的初始化。這裡我直接寫好了,在初始化的時候就把資料和劃分方式給模型,進行相關條件概率的計算,相關的註釋已經在程式碼裡面了,有幾個注意的地方:條件概率在字典中的key是有格式的,後續也是根據這個來訪問。
1 #region 建構函式,初始化 2 public BayesianClassifier(List<double[]> data, List<double[][]> rules, List<Int32> C) 3 { 4 this.data = data; 5 this.rules = rules; 6 this.C = C; 7 Int32 N = data[0].Length - 1;//屬性個數 8 if (N != rules.Count) throw new Exception("屬性劃分集與屬性個數對應錯誤"); 9 10 //先計算樣本中各類別的比例,儲存在dic中 11 C_Ratio = C.ToDictionary(n => n, n => (double)data.Where(k => n == k[N ]).Count() / (double)data.Count); 12 13 //計算特徵屬性劃分概率,儲存在字典中 14 ConRatio = new Dictionary<String, double>(); 15 for (int i = 0; i < C.Count; i++)//迴圈類別屬性 16 { 17 var temp1 = data.Where(n => n[N ] == C[i]);//當前類別的情況 18 //迴圈屬性 19 for (int j = 0; j < N; j++) 20 { 21 // 迴圈該屬性的所有劃分集 22 for (int k = 0; k < rules[j].Length; k++) 23 { 24 String key = String.Format("{0}{1}{2}", j,k,C[i] );//屬性位置-劃分位置-類別 25 //計算當前的條件概率,判斷data第j個屬性,在等於C[k]的結果中,滿足當前屬性劃分上下限的比例 26 var temp2 = temp1.Where(n => n[j].IsInRange(rules[j][k][0], rules[j][k][1])); 27 double value = (double)temp2.Count() / (double)temp1.Count(); 28 ConRatio.Add(key, value); 29 } 30 } 31 } 32 } 33 #endregion
3.足球比賽場次勝平負結果的分類預測
預測的過程也和第2節的例子一樣,只不過是程式化了。預測的方法是每次一條記錄的資料,並計算屬於每一類的概率,所以返回的是一個字典,key為類別,value為概率。具體方法如下所示:
1 /// <summary>分類:key為類別,value為概率</summary> 2 public Dictionary<Int32, double> ClassificationForDic(double[] data) 3 { 4 //先要計算每個當前屬性的劃分集合的順序,找出每個屬性所屬於的區間 5 List<Int32> attIdList = new List<int>(); 6 for (int i = 0; i < data.Length -1; i++) 7 { 8 for (int j = 0; j < rules[i].Length ; j++) 9 { 10 if (data[i].IsInRange(rules[i][j][0], rules[i][j][1])) attIdList.Add(j); 11 } 12 } 13 14 Dictionary<Int32, double> res = C_Ratio.ToDictionary(n=>n.Key,n => 15 { 16 double multip = n.Value; 17 for (int i = 0; i < data.Length -1; i++) 18 { 19 for (int j = 0; j < attIdList.Count; j++) 20 { //屬性位置-劃分位置-類別 21 String key = String.Format("{0}{1}{2}",i,attIdList[j],n.Key); 22 if (!ConRatio.ContainsKey(key)) multip = 0 ; 23 else multip *= ConRatio[key]; 24 } 25 } 26 return multip; 27 }); 28 return res; 29 }
返回這個字典後,要計算概率最大的結果也非常容易,直接對字典進行排序就可以了。具體程式碼看總的cs檔案。
3.3 貝葉斯預測演算法的測試
基本過程和程式碼完成了,我們採集5大聯賽(西甲,德甲,英超,意甲,法甲)的資料進行測試,看看貝葉斯預測演算法的準確性如何。測試的核心程式碼如下:
1 public static void TestBySeason() 2 { 3 //五大聯賽的賽季編號 4 List<Int32> seasonList = new List<int>() {6000,4866 };//4865,16136,4863,4861,5994 5 //先初始化聯賽排名 6 seasonList.ForEach(n => EventRanking.UpdateHisSeason(n)); 7 int trainRoundL = 8;int trainRoundH = 25;//訓練集的起至輪數 8 int testRoundL = 26; int testRoundH = 35;//測試集的起至輪數 9 List<double[]> trainData = new List<double[]>();//訓練集 10 foreach (var item in seasonList) 11 { 12 var temp = GetDataBySeason(item,trainRoundL,trainRoundH).Select(n=>n.Data).ToList(); 13 trainData.AddRange(temp); 14 } 15 //然後採集測試集的資料,標籤用於對比,測試時是不用的,只是最後對比使用 16 List<BayesDS> testData = new List<BayesDS>();//訓練集 17 foreach (var item in seasonList) 18 { 19 var temp = GetDataBySeason(item, testRoundL, testRoundH); 20 testData.AddRange(temp); 21 } 22 while (true)//迴圈根據不同屬性劃分進行測試 23 { 24 Console.Write("總積分差 屬性分割集(參考:-8, -2, +5, 10):"); 25 var t1 = Console.ReadLine().StringToDoubleArray().ToList(); 26 Console.Write("主客積分差 屬性分割集(參考:-5, -1, +5):"); 27 var t2 = Console.ReadLine().StringToDoubleArray().ToList(); 28 List<double[][]> rules = new List<double[][]>(); 29 rules.Add(GetRulesByPoint(t1));//總積分差 參考:{ -8, -2, +5, 10 }) 30 rules.Add(GetRulesByPoint(t2));//主客積分差 參考:{ -5, -1, +5 }) 31 //初始化模型 32 BayesianClassifier bayesMode = new BayesianClassifier(trainData, rules, new List<int>() { 3, 1, 0 }); 33 var testResuult = testData.Select(n => 34 { 35 var res = bayesMode.Classification(n.Data);//預測結果 36 }).ToList(); 37 } 38 }
1.資料集採用2013-2014賽季,歐洲5大聯賽的比賽,我們選取前8-25輪的場次作為訓練集,26-35輪的比賽作為測試集合(考慮到聯賽初期和末期的不穩定性)。

我們可以看到,針對不同的劃分集,指數1的準確率都超過了57%,比正常的歐賠指數45-50%,高出了5-10%。結果還是比較可觀的。但是我們也看到指數3的比例都有22%,說明對於一些特別冷門的場次,演算法還是做不到,這些特殊情況不是簡單2個因素就可以左右的,因此還有待對模型更深一步的研究,找出這些特別冷門場次的一些共同因素,從而進行一定程度的防範,減少指數3的比例,從而提高指數1,2的比例。
2.同時,我們對上一步的測試方法進行了一定的更改,將預測結果和歐賠bet 365指數1結果一致的比賽拿出來進行統計;將預測結果和歐賠bet 365指數1,2結果一致的比賽進行統計:
同樣是上述481場比賽進行篩選和屬性劃分,我們對實際的準確率進行比較:
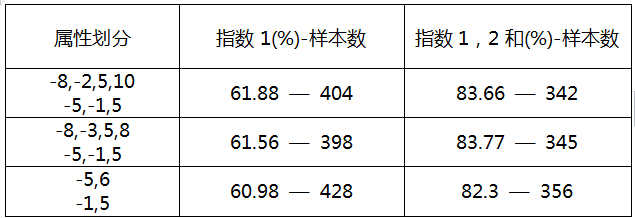
通過結合歐賠指數,進行一定的過濾後,預測的整理準確率有了一定的提高。這個結果還是很理想的,懂的人應該知道里面的含義。所以貝葉斯理論的確是非常強大,當然這裡只採用了2個因素,而且本身是關聯的,但實際中沒有考慮關聯性,看成了樸素貝葉斯,必定會對問題結果產生一定的影響。這和我解決問題的思路有關係,先簡單,後複雜,逐步過渡,延伸。。
4.參考文獻與資料
部落格園很多網友多對偽原創網站抓取文章做出過防範對策,我也發現這個問題,所以也想出了2個辦法。
1.在部落格正文加上本文的連結,當然部分網站會無良的把所有連結給去掉,但可以防範部分,另外水印這些也有點用,只是比較麻煩,懶得搞
2.也是我的必殺技,資料不直接開放下載,而是在文章發表後的12-24小時後再把連結發出來,或者通過郵箱傳送。因為網站抓取一般都是對首頁文章進行抓取,在發表12-24小時後,在進行抓取的頻率就少多了。鑑於此,本文的資源將在發表後的24小時公開百度網盤的下載連結,所以大家可以關注部落格,或者留下郵箱,在24小時後,統一郵箱傳送。打包的資料文章有:
貝葉斯分類方法及其在冠心病診療中的應用研究. 貝葉斯網路研究 基於WEKA平臺的貝葉斯分類器的擴充套件 基於貝葉斯方法的分類問題研究 基於粗糙集的加權樸素貝葉斯分類演算法研究 基於粗糙集的樸素貝葉斯分類演算法研究 基於改進的K-均值演算法的樸素貝葉斯分類及應用 基於聚類的樸素貝葉斯分類模型的研究與應用 加權貝葉斯增量學習中文文字分類研究 面向不確定性資料的貝葉斯分類方法研究上述論文由於涉及到版權,已經取消下載取消下載,如需要請留言或者郵件索取。
參考的相關網頁:3.貝葉斯定理
如果本文對大家有幫助或者非常感興趣,希望得到“推薦”,這樣我也會將抽空寫一篇關於更加複雜和實用的貝葉斯網路推斷的例子和C#實現的文章,希望大家關注本部落格。
預告,下一篇文章將是本站第100篇正式文章,將與近期釋出一個.NET平臺機器學習資源彙總的隨筆,資訊量很大,敬請關注,機不可失失不再來。。。。
相關推薦
白話貝葉斯理論及在足球比賽結果預測中的應用和C#實現
貝葉斯分類的基礎是概率推理,就是在各種條件的存在不確定,僅知其出現概率的情況下,如何完成推理和決策任務。概率推理是與確定性推理相對應的。而樸素貝葉斯分類器是基於獨立假設的,即假設樣本每個特徵與其他特徵都不相關。舉個例子,如果一種水果其具有紅,圓,直徑大概4英寸等特徵,該水果可以被判定為是蘋果。
Python代碼和貝葉斯理論告訴你,誰是最好的棒球選手
AMM nes labs 最終 via 現實生活 alt www .net 編譯:李雷、張馨月、王夢澤、小魚 除了文中所附的代碼塊,你也可以在文末找到整個程序在Jupyter Notebook上的鏈接。 在數據科學或統計學領域的眾多話題當中,我覺得既有趣但又難理解的一個就是
樸素貝葉斯原理及sklearn呼叫
一、原理 與其他大多數的分類演算法不同,如:決策樹、KNN、邏輯迴歸等,它們都是判別方法,直接學習出類別y和特徵x之間的關係。樸素貝葉斯屬於生成方法,它的理論基礎是貝葉斯公式: P
不用數學也能講清貝葉斯理論的馬爾可夫鏈蒙特卡洛方法?這篇文章做到了
大多數時候,貝葉斯統計在結果在最好的情況下是魔法,在最糟糕時是一種完全主觀的廢話。在用到貝葉斯方法的理論體系中,馬爾可夫鏈蒙特卡洛方法尤其神祕。 這篇文章將介紹馬爾可夫鏈蒙特卡洛方法,極其背後的基本數學推理。 首先,什麼是馬爾可夫鏈蒙特卡洛(MCMC)
【學習筆記】Pattern Recognition&Machine Learning [1.2] Probability Theory(2) 基於高斯分佈和貝葉斯理論的曲線擬合
高斯分佈不必贅述,這裡記錄個有意思的東西,即從高斯分佈和貝葉斯理論出發看曲線擬合(即選擇引數w)。 首先假設我們使用多項式擬合曲線,根據泰勒展開的方法,我們可以用有限項多項式在一定精度內擬合任何曲線。 &nb
【學習筆記】Pattern Recognition&Machine Learning [1.2] Probability Theory(1)貝葉斯理論
這節講了概率論中的一些基本概念,這裡記錄一下對貝葉斯理論的理解。 首先簡單描述一下貝葉斯理論。 對於一個隨機事件,我們首先給出先驗分佈,不妨設為p(w)
貝葉斯理論
例子-正向概率 還是拿質檢員的例子來做分析,假如我是一個質檢員,現在接到了三箱零件需要檢驗,其中第一箱有10個零件,第二箱有20個零件,第三箱有15個。半小時過去了,檢驗的結果出爐,第一箱有1個不合格,第二箱有3個不合格,第三箱2個不合格。 箱子 總零件個數 不合格
樸素貝葉斯理論--自我理解
例子-正向概率 還是拿質檢員的例子來做分析,假如我是一個質檢員,現在接到了三箱零件需要檢驗,其中第一箱有10個零件,第二箱有20個零件,第三箱有15個。半小時過去了,檢驗的結果出爐,第一箱有1個不合格,第二箱有3個不合格,第三箱2個不合格。 箱子
貝葉斯演算法及例項python實現
目錄 計算過程: 貝葉斯簡介: 貝葉斯(約1701-1761) Thomas Bayes,英國數學家 貝葉斯方法源於他生前為解決一個“逆概”問題寫的一篇文章。 貝葉斯要解決的問題: 正向概率:假設袋子裡面有N個白球,M個黑球,你
樸素貝葉斯原理及python實現
一、貝葉斯演算法引入 樸素貝葉斯演算法是基於貝葉斯定理和特徵條件獨立假設的分類法,是一種基於概率分佈的分類演算法。 貝葉斯分類演算法,通俗的來講,在給定資料集的前提下,對於一個
很好的關於貝葉斯理論的文章
貝葉斯推斷及其網際網路應用 作者:阮一峰 一、什麼是貝葉斯推斷 貝葉斯推斷(Bayesian inference)是一種統計學方法,用來估計統計量的某種性質。 它是貝葉斯定理(Bayes' theorem)的應用。英國數學家托馬斯·貝葉斯(Thomas B
樸素貝葉斯演算法及Python的簡單實現
貝葉斯演算法起源於古典數學理論,是一種分類演算法的總稱。它以貝葉斯定理為基礎,假設某待分類的樣本滿足某種概率分佈,並且可以根據已觀察到的樣本資料對該樣本進行概率計算,以得出最優的分類決策。通過計算已觀察到的樣本資料估計某待分類樣本的先驗概率,利用貝葉斯公式計算出其後
樸素貝葉斯-分類及Sklearn庫實現(1)機器學習實戰
KNN,決策樹兩種演算法都明確給出了“該資料例項到底屬於哪一類”這類明確的回答,而這一篇講到的樸素貝葉斯分類器,基於概率論的分類方法,將給出資料例項屬於不同種類的概率(基於資料的後驗概率),從而供我們選擇一個最優的類別猜測結果。例如給定一組資料(x,y),可能的
機器學習實戰 樸素貝葉斯原理及程式碼
#---------------------------從文字中構建詞條向量------------------------- #1 要從文字中獲取特徵,需要先拆分文字,這裡特徵是指來自文字的詞條,每個詞 #條是字元的任意組合。詞條可以理解為單詞,當然也可以是非單詞詞條,比如URL #IP地址或者其他任意字
NB樸素貝葉斯理論推導與三種常見模型
轉自:http://www.tuicool.com/articles/zEJzIbR 樸素貝葉斯(Naive Bayes)是一種簡單的分類演算法,它的經典應用案例為人所熟知:文字分類(如垃圾郵件過濾)。很多教材都從這些案例出發,本文就不重複這些內容了,而把重點放在理論推導(其實很淺顯,別被“理論”嚇到),三
PRML(一)如何根據貝葉斯理論推導多項式曲線擬合問題的cost function
馬上要成為一個ML/DL方向的工程師,PRML作為經典教材,對於理解一些常用演算法的intuition和motivation是非常有益的。雖然是2006年出版的一本書,但是有很多內容仍然值得學習和反思。加之本書有一些習題可以鞏固思考,今天開始踏入PRML的
機器學習演算法(三)——樸素貝葉斯演算法及R語言實現方法
樸素貝葉斯演算法也是一種常用的分類演算法,尤其在對文字文件分類的學習任務中,樸素貝葉斯分類是最有效的演算法之一。所謂的樸素,即假設在給定目標值時屬性值之間相互條件獨立,雖然這一假設看似不合理,但其最終的分類效果卻普遍較好。 一、概述 1、貝葉斯公式 2、最大後驗假設(MA
樸素貝葉斯——理論篇
在學習樸素貝葉斯時,需要注意以下幾個關鍵點: 1.它是構建分類器的簡單方法,不是一個訓練分類器的單一方法,而是一系列基於相同原理的演算法,例如(基於高斯分佈的樸素貝葉斯和基於多項式的樸素貝葉斯等)。 2.它是一個基於貝葉斯定理與特徵獨立性假設的分類方法。這裡我想解釋一下特徵
樸素貝葉斯原理及實現
一、理論基礎 (一)樸素貝葉斯定理 簡單的說:一個樣本屬於某個類別的概率是:這個類別出現的概率 * 已知這個類別出現的情況下各個屬性出現的概率的乘積 根據貝葉斯定理,事件X發生時,類別Ci發生的後驗概
一句話說明樸素貝葉斯理論
樸素貝葉斯理論:天真的假設,每個特徵之間是相互獨立的。這就是樸素貝葉斯樸素的"樸素"的地方。以下來自阮一峰的部落格貝葉斯理論:與其他統計學推斷方法截然不同。它建立在主觀判斷的基礎上,也就是說,你可以不