
nodejs 爬取動態網頁
前言
昨天實現了草榴的爬取 nodejs 做一個簡單的爬蟲爬草榴,今天對程式碼做了一部分修改,增加了可以指定開始頁和結束頁,並且給所有檔案都單獨建立了資料夾。那麼問題來了,說好的爬 街拍圖片 呢?畢竟爬完草榴的東西並不適合展示,所以,今天又嘗試了一下爬今日頭條的街拍圖片。Talk is cheap,show me the code,廢話不多說,直接進入正題。
準備工作
看過昨天的文章的話可以跳過準備工作和建立工程,直接進入今日頭條街拍圖片程式碼。
依舊是下載nodejs,真的覺得自己什麼都說了,就差配置環境變量了。不過現在應該下載完直接新增環境變量了吧,或者自己到網上搜一下,一大堆。
建立工程
- 首先,在你想要放資源的地方建立資料夾,比如我在 E 盤裡面建立了一個 myStudyNodejs 的資料夾。
- 在 DOS 裡面進入你建立的資料夾 如圖
- 進入 e 盤:E:
- 進入資料夾:cd myStudyNodejs(你建立的資料夾的名字)
注意全是英文符號
- 初始化專案,在你建立的資料夾下面執行 npm init 初始化專案。一路回車,最後輸個 yes 就行。
- 執行完以後,會在資料夾裡面生成一個 package.json 的檔案,裡面包含了專案的一些基本資訊。
- 安裝所需要的包
npm install request -save 注意因為頭條是動態網頁,所以無法用 cheerio 來分析網頁,所以只需要這一個包就足夠了 - 建立檔案
- 建立一個 image 資料夾用於儲存圖片資料。
- 建立一個 js 檔案用來寫程式。比如 study.js。(建立一個記事本檔案將 .txt 改為 .js)
說明 –save 的目的是將專案對該包的依賴寫入到 package.json 檔案中。
今日頭條爬蟲程式碼
爬取今日頭條過程中遇到的最大問題就是今日頭條介面是動態生成的,圖片連結儲存在 script 標籤中,所以不能用 cheerio 模組來解析,只能通過正則表示式進行匹配。
首先在今日頭條介面搜尋街拍,因為文章和圖集裡面的連結區別比較大,所以我們點選圖集,只爬圖片。
按 F12 開啟開發者工具,在 network 裡面找到 XHR(需要重新重新整理才會出現資源)。
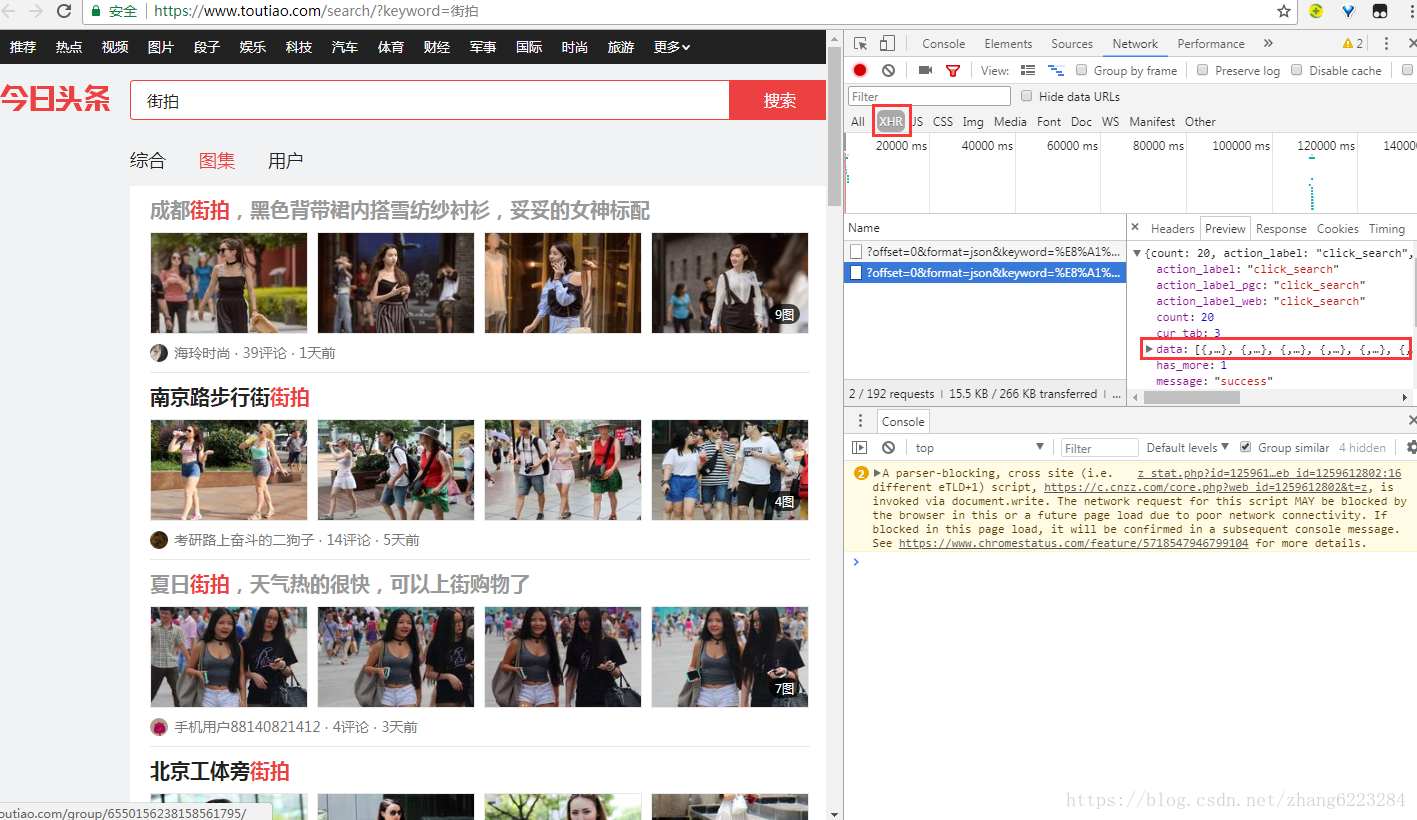
因為介面是動態生成的,所以我們要找的 URL 全都存在這裡面。
點開 data,找到我們需要的 URL。
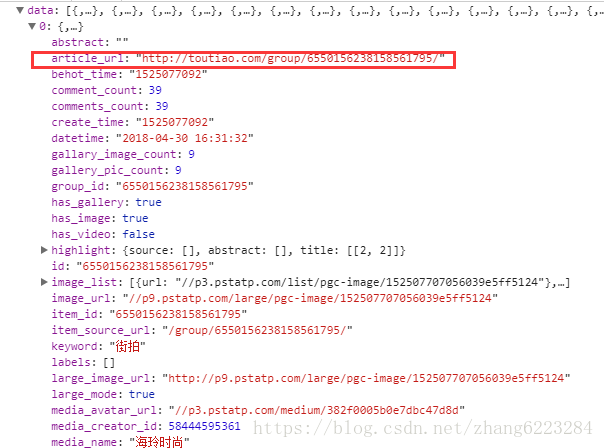
這裡注意一點,這個 url 裡面用的是 http 的請求,並且路徑上面多了一個 group,所以我們要重新拼接一下。
x.url='https://www.'+x.url.substring(7,19)+'a'+x.url.substring(25);接下來就是發起請求,獲取介面資料。我們所需要的圖片路徑如下。
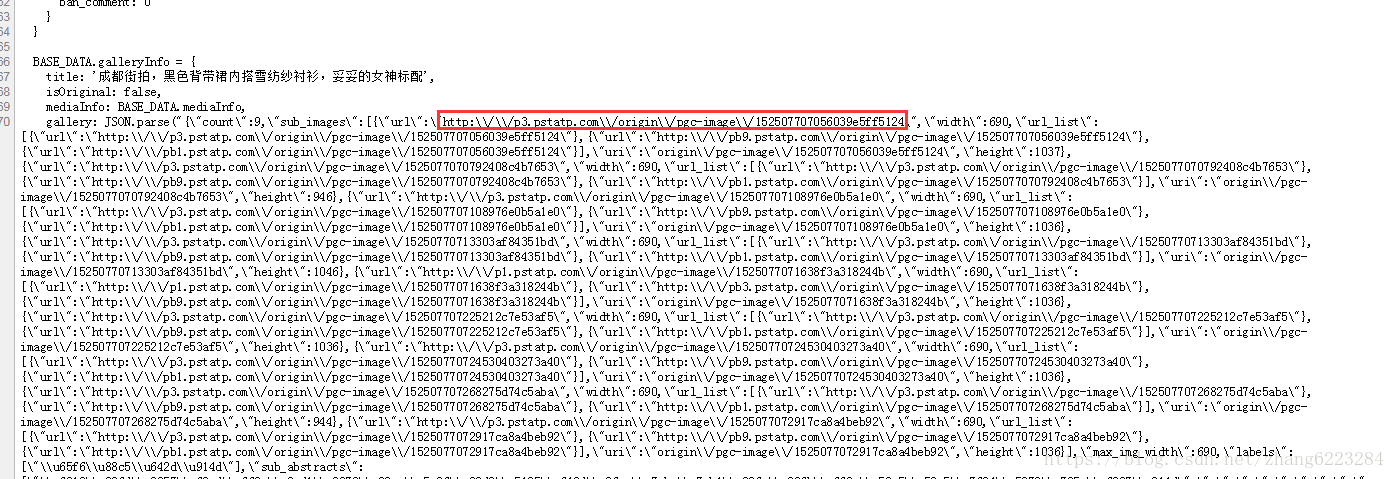
分析幾個頁面圖片的路徑得出我們需要使用的正則表示式
let reg=/http\:\\\/\\\/p\d\.pstatp\.com\\\/origin(\\\/pgc\-image)?\\\/[A-Za-z0-9]+/g;這個正則表示式不難,但是應該是我寫過的最長的了,其中 \\/pgc-image 這一段有的圖片路徑沒有,所以用 ? 來匹配 0 次或 1 次。注意不要匹配最後的 \,不然無法正確獲取路徑。 接下來就是把獲取的檔案儲存下來。匹配下來的 URL 是 http:/\/\ 這種模式,需要自己重新設定。
var img_src = 'http://'+item.substring(9);接下來,就是把圖片下載到本地。
下面是完整原始碼
/*
* @Author: user
* @Date: 2018-04-30 12:25:50
* @Last Modified by: user
* @Last Modified time: 2018-04-30 22:02:59
*/
var https =require('https');
var http = require('http');
var fs = require('fs');
var request = require('request');
let startPage=0;//從哪一頁開始爬
let page=startPage;
let endPage=1;//爬到哪一頁
//初始請求地址
var url='https://www.toutiao.com/search_content/?offset='+startPage*20+'&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery'
var i = 0;
//用來判斷儲存還是訪問
var temp=0;
//儲存首頁url
urlList=[];
//封裝了一層函式
function fetchPage(x) {
setTimeout(function(){
startRequest(x); },2000)
}
//首先儲存要訪問介面的url
function getUrl(x){
temp++;
https.get(x,function(res){
var html = '';
res.setEncoding('binary');
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
html = JSON.parse(html);//由於獲取到的資料是JSON格式的,所以需要JSON.parse方法淺解析
for(let i of html.data){
var obj1={title:i.title,url:i.article_url};
urlList.push(obj1)
}
page++;
if(page<=endPage){
let tempUrl='https://www.toutiao.com/search_content/?offset='+page*20+'&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery';
getUrl(tempUrl);
}
else{
fetchPage(urlList.shift());
}
})
}).on('error', function (err) {
console.log(err);
});
}
function startRequest(x) {
if(temp===0){
getUrl(x);
}
else{
//採用http模組向伺服器發起一次get請求,擷取的字串為文章連結地址
x.url='https://www.'+x.url.substring(7,19)+'a'+x.url.substring(25);
setTimeout(function(){
https.get(x.url, function (res) {
var html = ''; //用來儲存請求網頁的整個html內容
res.setEncoding('binary');
//監聽data事件,每次取一塊資料
res.on('data', function (chunk) {
html += chunk;
});
//監聽end事件,如果整個網頁內容的html都獲取完畢,就執行回撥函式
res.on('end', function () {
var news_item = {
//獲取文章的標題
title: x.title,
//i是用來判斷獲取了多少篇文章
i: i = i + 1,
};
console.log(news_item); //列印資訊
//用來匹配script中的圖片連結
let reg=/http\:\\\/\\\/p\d\.pstatp\.com\\\/origin(\\\/pgc\-image)?\\\/[A-Za-z0-9]+/g;
let imageList=[];
imageList=html.match(reg);
savedImg(imageList,x.title);
//如果沒訪問完繼續訪問
if (urlList.length!=0 ) {
fetchPage(urlList.shift());
}
});
}).on('error', function (err) {
console.log(err);
});},2000)
}
}
function savedImg(imageList,title){
fs.mkdir('./image/'+title, function (err) {
if(err){console.log(err)}
});
imageList.forEach(function(item,index){
var img_title = index;//給每張圖片附加一個編號
var img_filename = img_title + '.jpg';
//圖片的url需要轉換一下
var img_src = 'http://'+item.substring(9); //獲取圖片的url
//採用request模組,向伺服器發起一次請求,獲取圖片資源
request({uri: img_src,encoding: 'binary'}, function (error, response, body) {
if (!error && response.statusCode == 200) {
fs.writeFile('./image/'+title+'/' + img_filename, body, 'binary', function (err) {
if(err){console.log(err)}
});
}
})
})
}
fetchPage(url); //主程式開始執行接下來在建立的資料夾下面執行
node study.js
OK,大功告成
下面是成果展示,這次不用打碼了
後記
今天在網上找了一天該怎麼爬動態介面也沒找到類似的,最後只能用正則表示式來匹配,哪位大佬知道更好的方法望不吝賜教。這兩天對基本的爬蟲已經瞭解了,現在爬動態和靜態網頁大概知道從哪下手,對開發者工具的理解也稍微深了一點,下面準備嘗試一下非同步和併發爬取,改善一下程式碼,因為自己也沒做過非同步併發的東西,順便也加深一下自己對這方面的概念。
相關推薦
nodejs 爬取動態網頁
前言 準備工作 建立工程 後記 前言 昨天實現了草榴的爬取 nodejs 做一個簡單的爬蟲爬草榴,今天對程式碼做了一部分修改,增加了可以指定開始頁和結束頁,並且給所有檔案都單獨建立了資料夾。那麼問題來了,說好的爬 街拍圖
爬取動態網頁:Selenium
如何 瀏覽器 要去 nbsp ges selenium 安全性 接口 比較 參考:http://blog.csdn.net/wgyscsf/article/details/53454910 概述 在爬蟲過程中,一般情況下都是直接解析html源碼進行分析解析即可。但是
爬取動態網頁中關於構造瀏覽器頭的註意事項
rand 服務器 mage 地址 span gzip 原來 動態網頁 ati 在原來爬取動態網頁圖片中,獲取到了圖片的實際地址,但是下載下來的圖片是損壞的,究其原因,是服務器端阻止了訪問,但是觀察發現 headers = {‘User-Agent‘: random.cho
網路爬蟲:爬取動態網頁
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = '
python 爬取動態網頁(百度圖片)
# python 3.6.3 import re import os from urllib import parse from urllib import request ################################################### # 搜尋關鍵字
Python3+Selenium爬取動態網頁資料
背景: 有時候想獲取網頁的資訊,然後下載裡面的圖片資料等等 遇到的問題: 有時一些網頁是動態的,一些內容是通過js非同步拉取,甚至拉取時間是懶載入的,例如滾動到元素位置的時候才載入 解決方案: 這個時候就需要Selenium神器了 Selenium 是什麼?一句話
Python使用selenium爬取動態網頁時遇到的問題
我們在做京東手機資訊的爬取時,遇到的一些問題,現在就來跟大家分享一下。 1.首先,京東的網頁是動態的,當我們搜尋一個商品時,需要把頁面往下翻,下面的內容才會出來,這也是我們選selenium方法的原因 解決方法:讓瀏覽器模擬下拉幾次頁面即可 from selen
R語言爬取動態網頁之環境準備
在R實現pm2.5地圖資料展示文章中,使用rvest包實現了靜態頁面的資料抓取,然而rvest只能抓取靜態網頁,而諸如ajax非同步載入的動態網頁結構無能為力。在R語言中,爬取這類網頁可以使用RSelenium包和Rwebdriver包。 RSelenium包和Rwebdriver包都是
Python3網路爬蟲:Scrapy入門實戰之爬取動態網頁圖片
Python版本: python3.+ 執行環境: Mac OS IDE: pycharm 一 前言 二 Scrapy相關方法介紹 1 搭建Scrapy專案 2 shell分析 三 網頁分析
Python3網路爬蟲:requests爬取動態網頁內容
本文為學習筆記 學習博主:http://blog.csdn.net/c406495762 Python版本:python3.+ 執行環境:OSX IDE:pycharm 一、工具準備 抓包工具:在OSX下,我使用的是Charles4.0 下載連結以及安裝教
[Python爬蟲]Scrapy配合Selenium和PhantomJS爬取動態網頁
Python世界中Scrapy一直是爬蟲的一個較為成熟的解決方案,目前javascript在網頁中應用越來越廣泛,越來越多的網站選擇使用javascript動態的生成網頁的內容,使得很多純html的爬蟲解決方案失效。針對這種動態網站的爬取,目前也有很多解決方案。
Python如何爬取動態網頁資料
1.引言 說到爬網頁,我們一般的操作是先檢視原始碼或者審查元素,找到資訊所在節點,然後用 beautifulsoup/xpth/re 來獲取資料,這是我們對付靜態網頁的常用手段。 但大家也知
selenium和PhantomJS爬取動態網頁
一、selenium和PhantomJS用法簡介 selenium是web的自動化測試工具,類似按鍵精靈,可以直接執行在瀏覽器上。 pip install selenium PhantomJS是基於
使用Selenium爬取動態網頁
使用selenium優點:所見既所得 通過page_source屬性可以獲得網頁原始碼 selenium可以驅動瀏覽器完成各種操作,如填充表單、模擬點選等。 獲取單個節點的方法: find_element_by_id find_element_by_na
python爬取動態網頁
還記得在之前一篇python開發電影查詢系統(一)—python實現後臺資料中,對電影的下載地址無法進行爬取,原因是下載地址在網頁原始碼中無法檢視,而是存放在js中,動態載入了。所以在爬取時,我在文章中寫道 現在,我們找到了攻破他反爬的方法。下面我來詳細介
爬蟲爬取動態網頁下載美女圖片
scrapy爬取動態網頁下載圖片 靜態頁面練習了後,我們開始來爬取動態頁面,為了滿足廣大程式猿的需求,在這裡就選擇360圖片吧,網址是image.so.com。希望大家學會後身體一天不如一天。 首先我們來分析這個網頁,開啟開發者工具,滑動頁面等加載出新的圖片
Scrapy抓取動態網頁
都是 搜索 華盛頓 etime 觀察 review llb 得到 我們 動態網頁指幾種可能: 1)需要用戶交互,如常見的登錄操作; 2)網頁通過JS/ AJAX動態生成,如一個html裏有<div id="test"></div>,通過JS生成&l
爬取動態圖片—以百度圖片為例
python爬蟲;人工智能一:何謂動態加載圖片 所謂動態加載圖片即指html剛加載時,圖片時沒有的,然後通過json發生有關圖片的數據,在插入到html裏面去,以到底快速打開網頁的目的,那麽問題來了?我們如何找到加載文件的json文件呢?而這個問題正是我們實現爬取百度圖片的第一步,讓小可愛告訴你怎麽做吧
python 爬蟲(一) requests+BeautifulSoup 爬取簡單網頁代碼示例
utf-8 bs4 rom 文章 都是 Coding man header 文本 以前搞偷偷摸摸的事,不對,是搞爬蟲都是用urllib,不過真的是很麻煩,下面就使用requests + BeautifulSoup 爬爬簡單的網頁。 詳細介紹都在代碼中註釋了,大家可以參閱。
python3 學習 3:python爬蟲之爬取動態載入的圖片,以百度圖片為例
轉: https://blog.csdn.net/qq_32166627/article/details/60882964 前言: 前面我們爬取圖片的網站都是靜態的,在頁面中右鍵檢視原始碼就能看到網頁中圖片的位置。這樣我們用requests庫得到頁面原始碼後,再用bs4庫解析標籤即可儲存圖片