
目標檢測:SSD的資料增強演算法
SSD的資料增強演算法
程式碼地址
論文地址
資料增強:
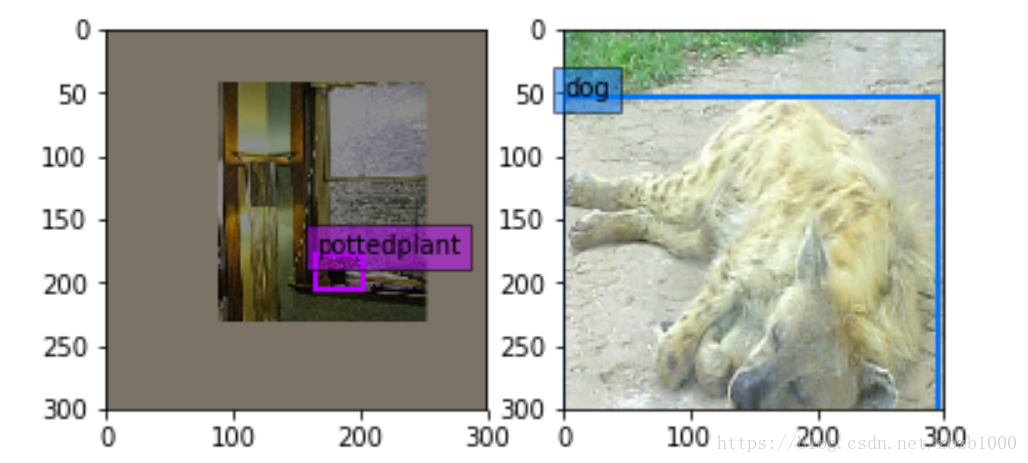
SSD資料增強有兩種新方法:(1)expand ,左圖(2)batch_sampler,右圖
expand_param {
prob: 0.5 //expand發生的概率
max_expand_ratio: 4 //expand的擴大倍數
}expand是指對影象進行縮小,影象的其餘區域補0,下圖是expand的方法。個人認為這樣做的目的是在資料處理階段增加多尺度的資訊。大object通過expand方法的處理可以變成小尺度的物體訓練。提高ssd對尺度的泛化性。
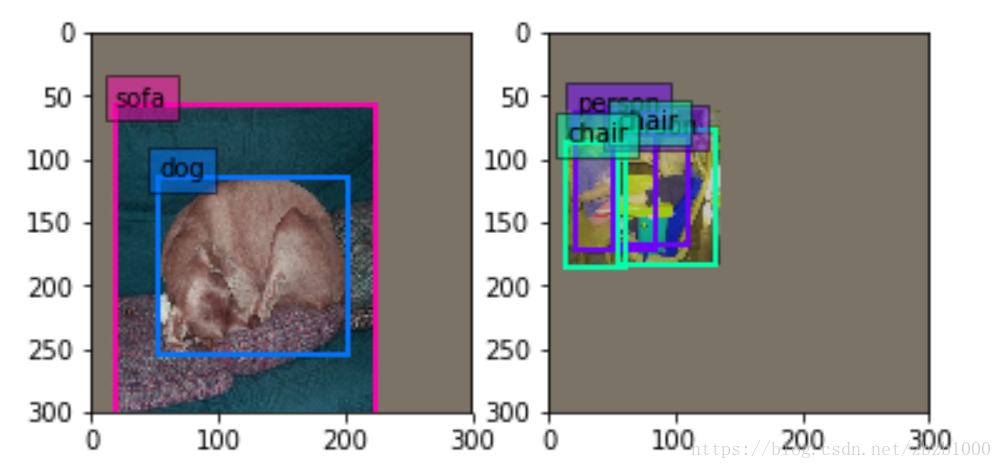
annotated_data_param {//以下有7 batch_sampler是對影象選取一個滿足限制條件的區域(注意這個區域是隨機抓取的)。限制條件就是抓取的patch和GT(Ground Truth)的IOU的值。
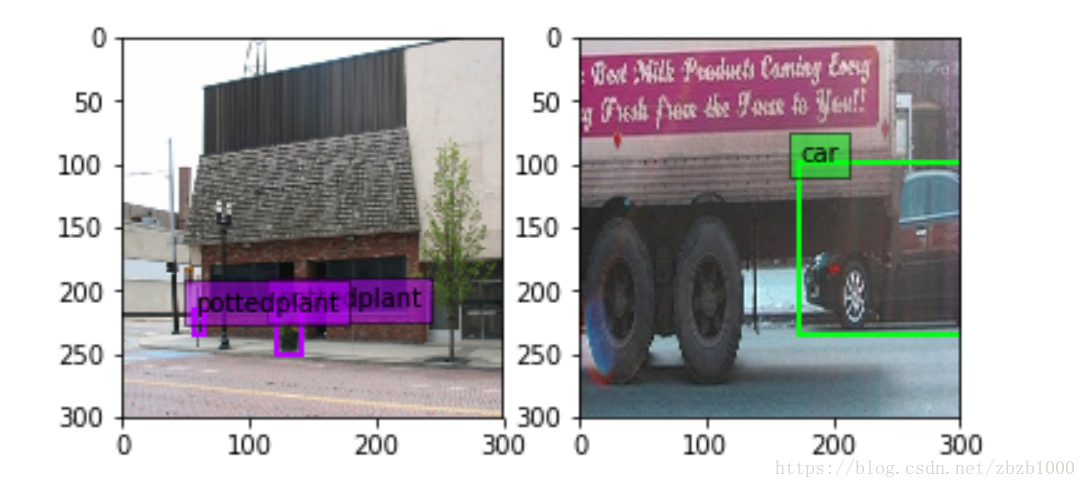
步驟是:先在區間[min_scale,max_sacle]內隨機生成一個值,這個值作為patch的高Height,然後在[min_aspect_ratio,max_aspect_ratio]範圍內生成ratio,從而得到patch的Width。到此為止patch的寬和高隨機得到,然後在影象中進行一次patch,要求滿足與GT的最小IOU是0.9,也就是IOU>=0.9。如果隨機patch滿足這個條件,那麼張圖會被resize到300*300(在SSD300*300中)送進網路訓練。如下圖。
batch_sampler {
sampler {
min_scale: 0.3
max_scale: 1
min_aspect_ratio: 0.5
max_aspect_ratio: 2
}
sample_constraint {
min_jaccard_overlap: 0.9
}
max_sample: 1
max_trials: 50
}
附
上面的內容是通過jupyter notebook視覺化得到的。並沒有詳細看SSD的transform_data的程式碼。如果有錯誤的地方,希望大家在評論處批評指正。
相關推薦
目標檢測:SSD的資料增強演算法
SSD的資料增強演算法 程式碼地址 論文地址 資料增強: SSD資料增強有兩種新方法:(1)expand ,左圖(2)batch_sampler,右圖 expand_param { prob: 0.5 //exp
目標檢測SSD+Tensorflow 訓練自己的資料集
對原文的幾點解釋這說明: 1.程式碼地址:https://github.com/balancap/SSD-Tensorflow,下載該程式碼到本地 注:該程式碼是github上tensorflow版的SSD star 最多的程式碼. 2.解壓ssd_300_vg
目標檢測SSD+Tensorflow 轉資料為tfrecord
用tensorflow做深度學習的目標檢測真是艱難困苦啊! 1.程式碼地址:https://github.com/balancap/SSD-Tensorflow,下載該程式碼到本地 2.解壓ssd_300_vgg.ckpt.zip 到checkpoint資料夾
實踐目標檢測--讀取資料集
描述 對於普通的影象分類,label只用表示圖片的類別就行,而目標檢測,不僅僅包括了類別的判斷,還包含了類別的位置資訊。所以在神經網路的構造上和資料的讀取上都大不相同。 深度學習框架選用 MxNet Gluon,經過個人的對比,對於單GPU或CPU,MxNet的速度和記憶體佔用要遠優於T
影象分類和目標檢測常用資料集介紹
The Caltech-UCSD birds-200-2011 dataset(加利福尼亞理工學院鳥類資料集): 分類數量:200 圖片數量:11,788 每個影象的註釋:15個部分位置,312個二進位制屬性,1邊界框 Labeled faces in the wild: L
重溫目標檢測--SSD
針對目標檢測問題,本文側重的是 速度+精度 對於 300×300 影象,SSD achieves 74.3% mAP 1 on VOC2007 test at 59 FPS on a Nvidia Titan X SSD 首先用一個 base netwo
目標檢測的第一個演算法Object Detection API使用
這個目標檢測我做了三天才調試出來,我的心都累了,不過最後我還是執行出來了,我還開心,所以努力去做。 下面的這個是參考文獻。 tensorflow:Object Detection API使用準備 - 騡兒的部落格 - CSDN部落格 https://blog.c
【目標檢測】Faster RCNN演算法詳解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information P
目標檢測SSD論文解讀
回到頂部一. 演算法概述 本文提出的SSD演算法是一種直接預測目標類別和bounding box的多目標檢測演算法。與faster rcnn相比,該演算法沒有生成 proposal 的過程,這就極大提高了檢測速度。針對不同大小的目標檢測,傳統的做法是先將影象轉換成不同大小(影象金字塔),然後分別檢測,最後將
【FPN車輛目標檢測】資料集獲取以及Windows7+TensorFlow+Faster-RCNN+FPN程式碼環境配置和執行過程實測
PS 最近在學目標檢測想用最新的FPN網路,剛好看到這篇部落格https://blog.csdn.net/Angela_qin/article/details/80944604嘗試把它復現,說的小白一點。 1.資料集獲取 博主只說是車輛目標檢測沒將資料集在哪裡獲取。我在程式碼中發現E:/st
目標檢測訓練資料增廣--旋轉+尺度+顏色+裁剪
原文連結:https://blog.csdn.net/wei_guo_xd/article/details/74199729常用的影象擴充方式有:水平翻轉,裁剪,視角變換,jpeg壓縮,尺度變換,顏色變換,旋轉當用於分類資料集時,這些變換方法可以全部被使用,然而考慮到目標檢測
目標檢測SSD Ubuntu16.04 CPU搭建與測試
前段時間在NVIDIA jeston TX1上測試SSD目標檢測方法挺順利,今天準備用新的資料重新測試,發現儲存不足。。汗因急於想驗證一下,臨時在Ubuntu的CPU主機上重新搭建測試一下,竟然遇到前前後後花了幾個小時(抓狂啊,遇到同樣的問題就是想不起來當初怎麼做的,可見記錄
【目標檢測】Fast RCNN演算法詳解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015. 繼2014年的RCNN之後,Ross Girshick在15年
[目標檢測|SSD實踐一]caffe-ssd基線
本次實驗利用caffe-ssd跑出了基線,主要從以下幾個方向總結。 - caffe-ssd的編譯 - caffe-ssd demo演示 - 自建資料集的資料準備 - fineTuning - 測試分析 一、caffe基線實驗 1.1
目標檢測之一(傳統演算法和深度學習的原始碼學習)
#include<opencv2\opencv.hpp> #include<opencv2\core\core.hpp> #include<opencv2\highgui\\highgui.hpp> #include <iostream> using names
高光譜影象處理之目標檢測技術(CEM演算法)(影象處理)
高光譜影象處理之目標檢測技術一、高光譜影象處理之目標檢測1、高光譜影象目標檢測的發展趨勢和研究現狀: 20世紀80年代末,美國的一些研究機構開始利用高光譜影象資料進行目標檢測方面的研究。自上世紀九十
【目標檢測】Mask RCNN演算法詳解
1 總體架構及與faster RCNN的比較 其中黑色部分為原來的 Faster-RCNN,紅色部分為在 Faster網路上的修改,總體流程如下: 1)輸入影象; 2)將整張圖片輸入CNN,進行特徵提取; 3)用FPN生成建議視窗(propo
[目標檢測]SSD:Single Shot MultiBox Detector
基於”Proposal + Classification”的Object Detection的方法,RCNN系列(R-CNN、SPPnet、Fast R-CNN以及Faster R-CNN)取得了非常好的效果,因為這一類方法先預先回歸一次邊框,然後再進行骨幹網路
目標檢測數據增強,旋轉方法
nbsp ret ceil class bsp end mage transform rect # 旋轉 def _rotate_img_bbox(self, img, bboxes, angle=5, scale=1.): ‘‘‘ 參考
目標檢測數據增強方法
一個 max left [1] 補充 hang tran chan std Data Augmentation For Bounding Boxes: Building Input Pipelines for your detector pytorch中檢測分割模型中