
基於Trie樹的多模匹配演算法實現和及優化
1.多模匹配演算法簡介
多模式匹配在這裡指的是在"一個字串"中尋找"多個模式字元字串"的問題。一般來說,給出一個長字串和很多短模式字串,如何最快最省的求出哪些模式字串出現在長字串中是我們需要思考的(因為基本上大多數情況下是在給定的長字串中出現我們給的模式字串的其中幾個)該演算法的應用領域有很多,例如:(1)關鍵字過濾
(2)入侵檢測
(3)病毒檢測
(4)分詞等
多模匹配演算法是一個概念性的稱呼,它的具體實現有很多,例如:
(1)Trie樹
(2)AC演算法
(3)WM演算法
2.Trie樹實現多模匹配的過程
2.1構造字首樹
比如我們現在有5個待搜尋模式串:"uuidi"、"ui"、"idi"、"idk"、"di",建立如下圖所示的字首樹:
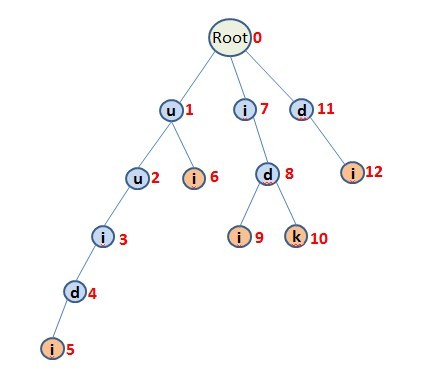 (圖1)
其中,根節點Root為空,不表示任何字元,其ID為0。依次讀取每一個模式串,將模式串的每一個字元新增到樹上,並依次順序編號,編號用紅色數字顯示在節點的右邊,每一個葉子節點用黃色背景表示(5,6,9,10,12號節點),表示這裡到達一個模式串的結尾(下文稱之為尾節點)。如果2個模式串有相同的字首,則相同的字首共用相同的節點。例如"uuidi"、"ui"有共同字首"u","idi"、"idk"有共同字首"id"。
(圖1)
其中,根節點Root為空,不表示任何字元,其ID為0。依次讀取每一個模式串,將模式串的每一個字元新增到樹上,並依次順序編號,編號用紅色數字顯示在節點的右邊,每一個葉子節點用黃色背景表示(5,6,9,10,12號節點),表示這裡到達一個模式串的結尾(下文稱之為尾節點)。如果2個模式串有相同的字首,則相同的字首共用相同的節點。例如"uuidi"、"ui"有共同字首"u","idi"、"idk"有共同字首"id"。從根節點Root開始,每一個節點的孩子節點表示在此節點可以匹配哪些字元,例如根節點有三個孩子節點1、7、11,則根節點處可以匹配u、i、d三個字元,如果目標字串相應位置上是這3個字元中的一個,則匹配上某一個孩子節點,接下來的匹配將從該孩子節點繼續下去。這是可以匹配上的情況,還有不匹配的情況,對於不匹配的情況我們不是跳回到根節點處重新進行匹配(這樣會造成目標字串的回溯),而是模仿KMP演算法中失配時,跳轉到FailureNode(失配跳轉節點)。例如目標字串是"uuidk",我們按照上面構造出的樹,會依次經過1、2、3、4節點(匹配上uuid),4的孩子節點5是i,不能匹配上目標串中的k,這個時候我們應該從4跳轉到節點8,我們稱8是4的FailureNode。
對於每一個樹上的節點都應該有對應的FailureNode,以指示在不匹配的情況應該跳轉到哪個節點繼續進行匹配。
2.2設定每一個節點的FailureNode
其目的和KMP演算法很類似,核心的思想是避免不必要的回溯,讓搜尋始終沿著向前的方向,盡最大可能減小時間複雜度。
上面我們舉了一個例子,在節點4失配時,應該跳轉到節點8去繼續進行匹配,這和KMP演算法中在失配時根據失配跳轉next陣列中記錄的位置來進行跳轉的原理是一樣的,目的是避免對目標串進行回溯匹配。在KMP演算法中求next陣列值可以用迭代的方法計算出來,類似的,在多個模式串的情況下,我們計算FailureNode也可以用迭代的方式計算出來。因此FailureNode的作用和KMP中的next陣列值是一樣的,查詢的原則也是一樣的,就是在模式串中查詢最長字首能夠匹配上當前失配位置處的最長字尾
仍以上面圖中的節點4來舉例,到達節點4的模式串為uuid,對應的字尾為"uid","id","d",我們要找樹的字首中,能匹配上這三個字尾且長度最長的那個位置,首先看"uid",從樹的根節點開始(因為要找字首)沒有能匹配上的,在找"id",找到能匹配上的節點7,8。所以我們設定4的FailureNode為8。如果沒有找到能匹配的字首,則設定FailureNode為根節點Root。
注:可能有看過KMP演算法的同學會注意到,我們在找到最長字尾的同時還要看後面的孩子節點是否一樣,如果找到的位置後面的孩子節點和本節點的孩子節點一樣,那麼跳轉過去,也必然導致失配。實際上確實如此,但我們仍然簡單處理,只看字首和字尾是否匹配,而不管後面的孩子節點是否一樣,其原因我們在後面說明。
針對上圖的12個節點,每個節點對應的FailureNode如下表:
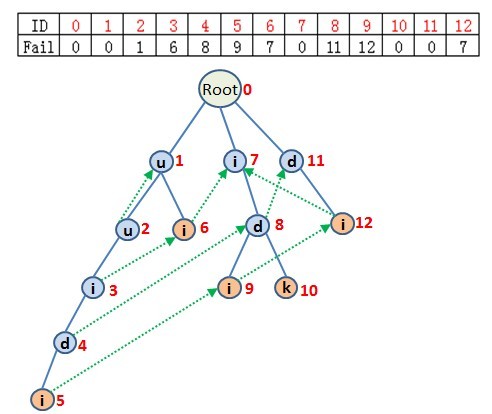
(圖2) 將每個FailureNode不為0的節點,和其對應的FailureNode節點,用綠色虛線連線起來,形成上圖。
每個節點K的FailureNode節點的深度不會超過該節點K的深度,因為從跟節點到FailureNode節點是一個字首。
另外每個節點K的FailureNode節點只有一個,不會有多個。因為FailureNode節點的定義是長度最長的字首匹配失配位置的字尾,長度最長的只可能找到一處,不可能找到兩處,如果有兩處長度一樣,且都是能夠匹配的字首,那麼這兩個分支按照字首樹的構造方法應該是重合在一起的。
構造完字首樹,設定好每一個節點的FailureNode之後,我們還有一件重要的事情沒有做,觀察上面的字首樹,當我們來到節點3時,節點2,3組成的字串"ui"其實已經匹配上一個模式串了,但節點3不是一個模式串的尾字元,所以我們無法報告給查詢者,我們其實已經匹配上一個模式串了;另外看節點5,當到達節點5時,我們除了匹配上了"uuidi"字串之外,其實我們也匹配上了"idi","di"字串。為了解決這個問題,我們需要收集每一個節點的模式串匹配情況。
2.3收集每個節點的所有匹配模式串資訊
其實要收集每個節點的所有匹配模式串也很簡單,觀察圖2,在節點3位置,應該報告匹配上了模式串"ui",我們可以看到節點3的FailureNode指向的是節點6。所以獲取每個節點的所有匹配模式串的資訊可以從該節點的FailureNode入口,如果節點K的FailureNode是一個尾節點,那麼到達節點K相當於匹配上了一個模式串。另外,我們再觀察節點5,節點5本身就是一個尾節點,所以它有自己的匹配模式串,再看5的FailureNode,指向9,節點9也是尾節點,所以5的匹配模式串除了自身的一個模式串(uuidi)之外還包括9所代表的模式串(idi),而9的FailureNode指向12,12也是一個尾節點,所以節點5也也應該包含節點12的匹配模式串(di)……這樣進行下去,一直到FailureNode指向了根節點,遍歷結束,遍歷過程中遇到的所有尾節點都是可匹配的模式串。
在具體的程式碼實現中,我用一個std::verctor容器來儲存一個節點所有的可匹配模式串資訊。
另外現在我們可以回答一下上面注一提到的問題。為什麼我們沒有去檢查節點和其FailureNode節點是否有相同的孩子,比如圖2中的節點8,我們上面計算出來8的FailureNode是11,但其實因為8有2個孩子9,10,如果8接下來的匹配失配,也就說明目標串中現在出現的字元不是i(9),k(10),而11的孩子節點12表示(i),則通過FailureNode到達11也必然是會匹配失敗的。但是我們仍然設定8的FailureNode為11,是因為如果漏掉過了節點11,我們有可能會漏掉匹配的模式串。例如,5的FailureNode是9,9的FailureNode是12,12的FailureNode是7,如果我們因為5,9,12都沒有孩子節點,而直接設定節點5的FailureNode為節點7,那麼我們在收集所有的匹配模式串資訊時,會漏掉尾節點9,12。
可以考慮一個更極端的情況,比如這樣的模式串集:"aaaa","aaa","aa","a",如果我們考慮到節點K的FailureNode的孩子結點不應該全都包含在節點K的孩子節點中(和KMP求NEXT陣列字首和字尾的後一個字元不應該一樣同理),那麼我們在目標串"aaaaaaaaaaa"查詢模式串集時會漏掉一些匹配的模式串資訊報告。
3.主要演算法——穿線演算法
3.1穿線演算法
顧名思義,穿線演算法就是把符合一定規則的節點用指標連線起來,在進行匹配的時候程式就可以沿著這 條穿好的線進行跳轉,不斷前進。把各個節點進行穿起來的方法就是設定每個節點的FailNode。
如何設定各個節點的FailNode?這裡使用遞推的方法來建立。在程式中,一個節點的資料結構中,failjump域用來存放節點的FailNode。可以用如下的方法來建立:
(1)設定Trie樹的第一層的不匹配的轉移節點
(2)廣度遍歷Trie樹,設定其餘層次的不匹配轉移節點。在這裡設定某節點的failjump域的時候要注意,如果fail.failjump孩子不存在的話,要一直向後迭代直到遇見fail存在孩子或者到達根節點才能停止,否則最後匹配的時候結果不全。虛擬碼如下:
child= current.child
fail= current;
while(fail!=根節點)
{
fail=fail.failjump;
entry= fail節點的孩子中value等於child.value的節點;
if(entry存在)break;
}
if(entry存在)
child.failjump= entry;
else
child.failjump=根節點;
(3)對演算法的說明:假設有三個節點G、P、S,他們的關係為:G -> P -> S。上面的虛擬碼中,如果current為P節點,那麼child就是S節點。這個過程設定了節點P的孩子S的failjump域,該節點(P節點)本身的failjump域是由父節點(G節點)中設定的。因為這個過程是由樹的根部開始的,並且第一層的節點的failjump都被初始化為根節點,因此後續的過程中可以保證出現的每個節點的failjump域都是已經設定過的。因此,按照廣度優先遍歷樹的原則,演算法可以不斷進行直至樹中所有的節點都被設定完畢。
(4)在這個過程中,同時要利用一個vector<string>,將該節點能夠匹配上的節點都打印出來。vector的構造採用增量法。它由兩部分組成,一方面觀察當前節點是否是尾節點,若是的話,將該詞加入vector。另一方面,繼承對應符合條件的failjump節點的vector。
3.2 穿線演算法的優化
上面的演算法中已經把字母相同的節點都穿在了一起,如果匹配過程中發現當前節點(假設當前節點所代表的是a)不存在某個子節點(假設為c),就把failjump指向的節點作為新的當前節點,繼續進行查詢(按照failjump的定義,該節點也代表a)。若新的當前節點也沒有為c的子節點,就一直順著failjump找下去,直到找到子節點中包含c的a節點或者到達根節點為止。在這個過程中,failjump指向的肯定是離當前節點距離(指的是高度差)最近的且是最大字尾的點點,因此能夠保證在尋找過程中首先找到的就是正確的跳轉節點。
仔細分析上述過程,還可以做進一步的優化,為什麼每次都要按照上面的流程從最近的開始找,一直找到所需要的節點?為什麼不直接跳轉到目的節點?這個思路固然好,但是當前節點只有一個failjump域,可是當前節點可能有好多個不能匹配的孩子,這些不匹配的孩子未必都會跳向同一個節點。因此需要為每個節點增加一個數據結構,為每個未匹配的孩子都增加一個fail域,發生不匹配的情況時直接讀取fail域的資訊。這樣勢必增加儲存的開銷,但是要獲得性能的提升就必須付出代價嘛,因此這點開銷是值得的。節點的fail域,實際上是一個長度為26的陣列,裡面儲存了對應的字母要跳轉的目標的指標。那麼匹配過程是怎樣的呢?彆著急,聽我慢慢道來。
每個節點中其實存在兩個陣列,一個是son[]陣列,一個是fail[]陣列,陣列長度都是26。其中son[]陣列儲存的是該節點的孩子節點,若26個字母中對應的孩子存在,則對應的位置儲存孩子的指標,否則為空。對於26個字母中不存在的那些孩子,程式肯定要跳轉了,那麼跳到哪裡去呢?3.1中已經給出瞭如何跳轉的描述,這裡講跳轉的位置提前計算好,存入fail[]對應的位置就可以了。簡單點,可以這麼理解,son[]中存放的是當前節點的親兒子,fail[]存放的是當前節點的乾兒子。當親兒子不存在時,就要找乾兒子,這兩個肯定兒子會存在一個(當然也只會存在一個)。程式執行時,優先尋找親兒子,找不到的時候才會尋找乾兒子,這樣就能保證每次跳轉都是有意義的。每跳轉一次,要比較的字串都會向前移動過一個字元。這樣,要比較的字串就不會回溯,提高了效率。
4.演算法的時間複雜度分析
多模匹配演算法中窮舉匹配演算法的時間最壞複雜度為O(m*n),其中n為目標字串的長度,m為模式串的平均長度。類似Kmp的多模匹配演算法的時間複雜度為O(n)。同時通過實驗進行了驗證,試驗結果如下:
Trie樹多模匹配時間
|
詞典詞長 |
建樹時間(ms) |
穿線時間(ms) |
窮舉匹配 |
KMP匹配 |
加速比 |
||
|
每字元跳轉次數 |
匹配用時(ms) |
每字元跳轉次數 |
匹配用時(ms) |
||||
|
5~10 |
241 |
461 |
4.75 |
216 |
1 |
130 |
1.66 |
|
15~20 |
670 |
1612 |
5.01 |
551 |
1 |
206 |
2.67 |
|
25~30 |
1068 |
2824 |
5.08 |
923 |
1 |
288 |
3.20 |
|
45~50 |
1863 |
5292 |
5.13 |
1632 |
1 |
443 |
3.68 |
|
65~70 |
2481 |
7477 |
5.15 |
2293 |
1 |
585 |
3.92 |
|
75~80 |
2963 |
9061 |
5.16 |
2771 |
1 |
673 |
4.11 |
其中,詞典為隨機生成的英語字母序列,規模為10萬條。目標字元傳為這10萬個單詞拼接起來的長字串。從上圖中可以可以看出:
(1)窮舉法匹配平均每比較一個字元需要跳轉5次左右,也就是平均時間複雜度在O(5*n)左右。詞典規模越大時該係數越大,但是推測就在5左右,不會大很多。
(2)類似KMP的匹配演算法確實做到了每一步跳轉都是有效的。但是獲得的加速比隨著單詞長度的增長會逐漸增大。
(3)根據圖中的資訊可以推測,對隨機產生的序列窮舉匹配法平均5次就可以後移目標串中的一個字元,理論上的O(m*n)的時間複雜度一般很難遇到。
(4)根據圖中的資訊可以推測,加速比最高應該在5左右。理論上加速比和窮舉匹配中每字元的跳轉次數應該非常接近。
5.原始碼
如下:
#include <iostream>
#include <fstream>
#include <string>
#include <sys/time.h>
#include <cstring>
#include <queue>
#include <sstream>
#include <cstdlib>
#include <ctime>
#include <algorithm>
using namespace std;
const int MAX = 5000000;
const int Son_Num = 26; //每個孩子的最大分支個數
const int dict_max_len = 30; //詞典中單詞的最大長度
//---------------------Trie樹的定義----------------------------
//節點定義
class Node{
public:
int flag; //節點的是否有單詞出現的標記
int count; //單詞出現的次數
string word; //到達該節點時出現的單詞
vector<string> word_set;//到達該節點時能夠匹配上的單詞
Node* failjump; //匹配失敗時指標的跳轉目標
Node* son[Son_Num]; //指向分支節點的指標,這裡為26個
Node* fail[Son_Num]; //指向各個分支跳轉節點的指標,26個
public:
Node() : flag(0),count(0),word(""){
failjump = NULL;
memset(son, NULL, sizeof(Node*) * Son_Num);
memset(fail, NULL, sizeof(Node*) * Son_Num);
}
};
//trie樹的操作定義
class Trie{
private:
Node* pRoot;
private:
void print(Node* pRoot);
public:
Trie();
~Trie();
void insert(string str); //插入字串
bool search(string str, int &count); //查詢字串
bool remove(string str); //刪除字串
void destory(Node* pRoot); //銷燬Trie樹
void printAll(); //列印Trie樹
void failjump(); //穿線演算法
void multi_match_1(string &str, int begin, int end, vector<string> &result); //多模匹配(回溯)
void multi_match_2(string &str, int begin, int end, vector<string> &result); //多模匹配(KMP)
};
//建構函式
Trie::Trie(){
pRoot = new Node();
}
//解構函式
Trie::~Trie(){
destory(pRoot);
}
//列印以root為根的Trie樹
void Trie::print(Node* pRoot){
if(pRoot != NULL){
if(pRoot -> word != ""){
cout << pRoot -> count << " " << pRoot -> word << endl;
}
if((pRoot -> word_set).size()){
for(int i = 0; i < (pRoot -> word_set).size(); i++){
cout << "--" << (pRoot -> word_set)[i];
}
cout << endl;
}
for(int i = 0; i < Son_Num; i++){
print(pRoot -> son[i]);
}
}
}
//列印整棵樹
void Trie::printAll(){
print(pRoot);
}
//插入新的單詞
void Trie::insert(string str){
int index = 0;
Node* pNode = pRoot;
//不斷向下搜尋單詞的字元是否出現
for(int i = 0; i < str.size(); i++){
index = str[i] - 'a';
//字元在規定的範圍內時,才進行檢查
if(index >= 0 && index < Son_Num){
//父節點是否有指標指向本字元
if(NULL == pNode -> son[index]){
pNode -> son[index] = new Node();
}
//指標向下傳遞
pNode = pNode -> son[index];
}else{
return;
}
}
//判斷單詞是否出現過
if(pNode -> flag == 1){
//單詞已經出現過,計數器加1
pNode -> count++;
return;
}else{
//單詞沒有出現過,標記為出現,計數器加1
pNode -> flag = 1;
pNode -> count++;
pNode -> word = str;
}
}
//搜尋指定單詞,並返回單詞出現次數(如果存在)
bool Trie::search(string str, int &count){
Node* pNode = pRoot;
int index = 0;
int i = 0;
while(pNode != NULL && i < str.size()){
index = str[i] - 'a';
if(index >= 0 && index < Son_Num){
//字元在指定的範圍內時
pNode = pNode -> son[index];
i++;
}else{
//字元不再指定的範圍內
return false;
}
}
//判斷字串是否出現過
if(pNode != NULL && pNode -> flag == 1){
count = pNode -> count;
return true;
}else{
return false;
}
}
//刪除指定的單詞
bool Trie::remove(string str){
Node* pNode = pRoot;
int i = 0;
int index = 0;
while(pNode != NULL && i < str.size()){
index = str[i] - 'a';
if(index >= 0 && index < Son_Num){
pNode = pNode -> son[index];
i++;
}else{
return false;
}
}
if(pNode != NULL && pNode -> flag == 1){
pNode -> flag = 0;
pNode -> count = 0;
return true;
}else{
return false;
}
}
//銷燬Trie樹
void Trie::destory(Node* pRoot){
if(NULL == pRoot){
return;
}
for(int i = 0; i < Son_Num; i++){
destory(pRoot -> son[i]);
}
delete pRoot;
pRoot == NULL;
}
//穿線演算法
void Trie::failjump(){
queue<Node*> q;
//將根節點的孩子的failjump域和fail[]域都設定為根節點
for(int i = 0; i < Son_Num; i++){
if(pRoot -> son[i] != NULL){
pRoot -> son[i] -> failjump = pRoot;
q.push(pRoot -> son[i]);
}else{
pRoot -> fail[i] = pRoot;
}
}
//廣度遍歷樹,為其他節點設定failjump域和fail[]域
while(!q.empty()){
Node *cur = q.front();
q.pop();
if(cur -> failjump != NULL){
for(int j = 0; j < Son_Num; j++){
//迴圈設定跳轉域
Node* fail = cur -> failjump;
Node* cur_child = cur -> son[j];
if(cur_child != NULL){
//當孩子存在時,設定孩子的failjump
while(fail != NULL){
if(fail -> son[j] != NULL){
//設定failjump域
cur_child -> failjump = fail -> son[j];
//設定word_set集合
if((fail -> son[j] -> word_set).size()){
cur_child -> word_set = fail -> son[j] -> word_set;
}
if(cur_child -> flag == 1){
(cur_child -> word_set).push_back(cur_child -> word);
}
break;
}else{
fail = fail -> failjump;
}
}
if(cur_child -> failjump == NULL){
cur_child -> failjump = pRoot;
if(cur_child -> flag == 1){
(cur_child -> word_set).push_back(cur_child -> word);
}
}
q.push(cur_child);
}else{
//當孩子不存在時,設定父節點fail[]域
while(fail != NULL){
if(fail -> son[j] != NULL){
//設定對應的fail[j];
cur -> fail[j] = fail -> son[j];
break;
}else{
if(fail == pRoot){
cur -> fail[j] = pRoot;
break;
}else{
fail = fail -> failjump;
}
}
}
}
}
}
}
}
//多模匹配演算法1(窮舉匹配)
void Trie::multi_match_1(string &str, int begin, int end, vector<string> &result){
int count = 0;
for(int pos = 0; pos < end; pos++){
Node* pNode = pRoot;
int index = 0;
int i = pos;
while(pNode != NULL && i < pos + dict_max_len && i < end){
index = str[i] - 'a';
if(index >= 0 && index < Son_Num){
//字元在指定的範圍內時
pNode = pNode -> son[index];
count++;
i++;
//若字串出現過,輸出
if(pNode != NULL && pNode -> flag == 1){
//cout << pNode -> word << endl;
result.push_back(pNode -> word);
}
}
}
}
cout << " 跳轉次數:count = " << count << endl;
cout << " 每個字元平均跳轉次數:" << double(count)/(end - begin) << endl;
}
//多模匹配演算法2(類KMP匹配)
void Trie::multi_match_2(string &str, int begin, int end, vector<string> &result){
int count_1 = 0, count_2 = 0, count_3 = 0;
Node* pNode = pRoot;
int index = 0;
int i = begin;
int word_set_size = 0;
while(pNode != NULL && i < end){
index = str[i] - 'a';
if(index >= 0 && index < Son_Num){
//字元在指定的範圍內時
if(pNode -> son[index]){
//該孩子存在,繼續向下搜尋
pNode = pNode -> son[index];
count_1++;
}else if(pNode != pRoot){
//該孩子不存在,並且當前不是根節點,進行跳轉
pNode = pNode -> fail[index];
count_2++;
}else{
//該孩子不存在,並且當前已經是跟節點
count_3++;
}
//若該位置有匹配詞語,輸出
if(word_set_size = (pNode -> word_set).size()){
for(int i = 0; i < word_set_size; i++){
//cout << (pNode -> word_set)[i] << endl;
result.push_back((pNode -> word_set)[i]);
}
}
//目標串前移
i++;
}
}
cout << " 跳轉次數:count_1 = " << count_1 << " count_2 = " << count_2 << " count_3 = " << count_3 << endl;
}
//----------------------輔助程式碼----------------------------
//生成隨機字串
string rand_string(int min, int max){
char a[MAX+1];
int len = rand()%(max - min) + min;
for(int i = 0; i < len; i++){
a[i] = rand()%26 + 'a';
}
a[len] = '\0';
string str(a);
return str;
}
//-----------------測試程式碼---------------------------
//獲取當前時間(ms)
long getCurrentTime(){
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec*1000 + tv.tv_usec/1000;
}
//樹的基本操作,增刪查改測試
void Test_1(){
//1.建立物件
Trie trie;
string str;
ifstream fin;
fin.open("dict.txt");
//2.建立Trie樹
long time_1 = getCurrentTime();
while(getline(fin, str, '\n')){
trie.insert(str);
}
long time_2 = getCurrentTime();
fin.close();
//3.查詢單詞
str = "siubetamwm";
int count = -1;
long time_3 = getCurrentTime();
bool isFind = trie.search(str, count);
cout << "要查詢的字串:" << str << endl;
long time_4 = getCurrentTime();
if(isFind){
cout << " 該單詞存在,存在次數:" << count << endl;
}else{
cout << " 該單詞不存在!" << endl;
}
//4.刪除單詞
str = "lutgjrxjavgfkij";
cout << "要刪除的字串:" << str << endl;
bool isRemove = trie.remove(str);
if(isRemove){
cout << " 該單詞存在,刪除成功!" << endl;
}else{
cout << " 該單詞不存在,刪除失敗!" << endl;
}
}
//呼叫詞典,多模匹配測試
void Test_2(){
//1.建立物件
Trie trie;
string str;
ifstream fin;
fin.open("dict.txt");
//2.建立Trie樹
long time_1 = getCurrentTime();
while(getline(fin, str, '\n')){
trie.insert(str);
}
long time_2 = getCurrentTime();
fin.close();
//3.將短字串組合為長字串
string long_str;
ostringstream string_out;
fin.open("dict.txt");
while(getline(fin, str, '\n')){
string_out << str;
}
fin.close();
long_str = string_out.str();
//long_str = rand_string(MAX - 20, MAX);
vector<string> result_1;
vector<string> result_2;
//4.在長字串中搜索字典中的字串(方法一:窮舉)
cout << "窮舉匹配:" << endl;
long time_3 = getCurrentTime();
trie.multi_match_1(long_str, 0, long_str.size(), result_1);
long time_4 = getCurrentTime();
cout << "窮舉匹配完畢!" << endl;
//5.進行穿線處理
cout << "穿線處理" << endl;
long time_5 = getCurrentTime();
trie.failjump();
long time_6 = getCurrentTime();
cout << "穿線完畢" << endl;
//6.在長字串中搜索字典中的字串(方法二)
cout << "KMP匹配:" << endl;
long time_7 = getCurrentTime();
trie.multi_match_2(long_str, 0, long_str.size(), result_2);
long time_8 = getCurrentTime();
cout << "KMP匹配完畢" << endl;
//7.輸出結果
cout << "目標字串長度:" << long_str.size() << endl;
cout << "窮舉匹配結果數量:" << result_1.size() << endl;
cout << "KMP匹配結果數量:" <<result_2.size() << endl;
sort(result_1.begin(), result_1.end());
sort(result_2.begin(), result_2.end());
if(result_1 == result_2){
cout << "兩種多模匹配方式結果相符:True" << endl;
}else{
cout << "兩種多模匹配方式結果不相符:False" << endl;
}
cout << endl;
cout << "建立Trie樹用時(ms):" << time_2 - time_1 << endl;
cout << "穿線演算法用時(ms): " << time_6 - time_5 << endl;
cout << "多模匹配1用時(ms):" << time_4 - time_3 << endl;
cout << "多模匹配2用時(ms):" << time_8 - time_7 << endl;
cout << "加速比:" << double(time_4 - time_3)/(time_8 - time_7) << endl;
}
//小測試
void Test_3(){
//1.建立物件
Trie trie;
//2.建立Trie樹
string str_1 = "uuidi";
string str_2 = "ui";
string str_3 = "idi";
string str_4 = "idk";
string str_5 = "di";
trie.insert(str_1);
trie.insert(str_2);
trie.insert(str_3);
trie.insert(str_4);
trie.insert(str_5);
//3.構造待匹配的字串
string long_str = rand_string(MAX - 20, MAX);
//string long_str = "uuidiuiidiidkdi";
cout << "length: " << long_str.size() << endl;
vector<string> result_1;
vector<string> result_2;
//4.在長字串中搜索字典中的字串(方法一:窮舉)
cout << "窮舉匹配:" << endl;
long time_5 = getCurrentTime();
trie.multi_match_1(long_str, 0, long_str.size(), result_1);
long time_6 = getCurrentTime();
cout << "窮舉匹配完畢!" << endl;
//5.進行穿線處理
cout << "穿線處理" << endl;
trie.failjump();
cout << "穿線完畢" << endl;
//6.在長字串中搜索字典中的字串(方法二)
cout << "KMP匹配:" << endl;
long time_7 = getCurrentTime();
trie.multi_match_2(long_str, 0, long_str.size(), result_2);
long time_8 = getCurrentTime();
cout << "KMP匹配完畢" << endl;
//7.輸出結果
cout << result_1.size() << endl;
cout << result_2.size() << endl;
sort(result_1.begin(), result_1.end());
sort(result_2.begin(), result_2.end());
cout << "目標字元傳長度:" << long_str.size() << endl;
if(result_1 == result_2){
cout << "兩種多模匹配方式結果相符:True" << endl;
}else{
cout << "兩種多模匹配方式結果不相符:False" << endl;
}
cout << "多模匹配1用時(ms):" << time_6 - time_5 << endl;
cout << "多模匹配2用時(ms):" << time_8 - time_7 << endl;
}
int main(){
//Test_1();
Test_2();
//Test_3();
}相關推薦
基於Trie樹的多模匹配演算法實現和及優化
1.多模匹配演算法簡介 多模式匹配在這裡指的是在"一個字串"中尋找"多個模式字元字串"的問題。一般來說,給出一個長字串和很多短模式字串,如何最快最省的求出哪些模式字串出現在長字串中是我們需要思考的(因為基本上大多數情況下是在給定的長字串中出
基於C#的多目標進化演算法平臺MOEAPlat實現
多目標進化算法系列 基於C#實現,展示的結果包括近似Pareto前沿,具體的Pareto前沿資料,IGD值的變化曲線等,當然這些都是高度可定製化的。 目前只提供了基於遺傳演算法的多目標進化演算法,交叉方式已提供SBX和DE兩種,變異方式為多項式突變。同時,
Trie Tree匹配演算法實現
問題描述:給定一個字串集合S={“abc”,“gghh”,“yefbgj”},設計並實現一個演算法,在給定文字中找出這些字串的不連續出現(不連續出現,例如“abdcdshfkajhg”這個文字中就包含了“abc”)。 一些多模式匹配演算法如:AC演算法,WM演算法等,都是去
多模式匹配演算法:AC自動機的C++實現
AC自動機(Aho-Corasick automaton)是用來處理多模式匹配問題的。 基本可認為是TrieTree+KMP。其中KMP是一種單模式匹配演算法。 AC自動機的構造要點是失敗指標的設定,用於匹配失敗時跳轉到另一節點繼續匹配。同時在匹配的過程中也用來檢索其他“同
使用IDEA基於Maven搭建多模塊聚合工程(springmvc+spring+mybatis整合)
utf-8 組件 json處理 con mon 博客 quick 作者 處理工具 文章有不當之處,歡迎指正,如果喜歡微信閱讀,你也可以關註我的微信公眾號:好好學java,獲取優質學習資源。 終於有時間搞java了,今天使用IDEA基於maven搭建了多模塊聚合工程,經過了
基於分解的多目標進化演算法(MOEA/D)
目錄 1、MOEA/D的特點 2、 MOEA/D的分解策略 3、MOEA/D的流程 基於分解的多目標進化演算法(Multi-objectiveEvolutionary Algorithm Based on Decomposition, MOEA/D)將多目標優化問題被轉
模式匹配演算法思想和實現KMP
首先模式匹配演算法解決的問題是在一個主串和一個模式匹配串中查詢相同的模式匹配串,如果相等,則返回當前模式匹配串的起始位置,否則返回-1 實現思路: /** 首先第一個大前提就是長度 第二個是判斷二者是否相等,然後同時後移 否則直接回退到i = i - j + 1
影象處理之積分圖應用三(基於NCC快速相似度匹配演算法)
影象處理之積分圖應用三(基於NCC快速相似度匹配演算法) 基於Normalized cross correlation(NCC)用來比較兩幅影象的相似程度已經是一個常見的影象處理手段。在工業生產環節檢測、監控領域對物件檢測與識別均有應用。NCC演算法可以有效降低光照對影象比較結果的影響。而
正向最大匹配演算法實現之python實現
1.python 版本:python 3.6.4 2.思路: s1.匯入分詞詞典,儲存為字典形式dic,匯入停用詞詞典stop_words,儲存為字典形式,需要分詞的文字檔案cutTest.txt,儲存為字串chars s2.遍歷分詞詞典,找出最長的詞,長度為max_chars s3
字串匹配演算法實現
KMP演算法 1 void Next(char *src,int n,int *next) 2 { 3 int j,k; 4 j=0; 5 k=-1; 6 next[0] = -1; 7 while(j<n-1) 8 { 9 if(k==-1 || src[j] == src[
演算法4-6:KMP字串模式匹配演算法實現 (c語言)
[提交] [統計] [提問] 題目描述 KMP演算法是字串模式匹配演算法中較為高效的演算法之一,其在某次子串匹配母串失敗時並未回溯母串的指標而是將子串的指標移動到相應的位置。嚴蔚敏老師的書中詳細描述了KMP演算法,同時前面的例子中也描述了子串移動位置的陣列實現的演算法。前面你已經實現
基於聚類(Kmeans)演算法實現客戶價值分析系統(電信運營商)
開發環境 jupyter notebook 一、電信運營商–客戶價值分析 從客戶需求出發,瞭解客戶需要什麼,他們有怎麼樣的特徵, 電信運營商為客戶設定不同的優惠套餐 爭取更多的使用者:推出不同的優
基於樸素貝葉斯分類演算法實現垃圾郵箱分類
貝葉斯決策理論 在機器學習中,樸素貝葉斯是基於貝葉斯決策 的一種簡單形式,下面給出貝葉斯的基本公式,也是最重要的公式: 其中X是一個m*n的矩陣,m為他的樣本數,n為特徵的個數,即我們要求的是:在已知的樣本情況下的條件概率。 )表示
基於MATLAB的Sobel邊緣檢測演算法實現
影象邊緣就是影象灰度值突變的地方,也就是影象在該部分的畫素值變化速度非常之快,就比如在座標軸上一條曲線有剛開始的平滑突然來個大轉彎,在變化出的導數非常大。 Sobel運算元主要用作邊緣檢測,它是一離散型差分運算元,用來計算影象亮度函式灰度之近似值。 邊緣是指其周圍
基於使用者的協同過濾推薦演算法原理和實現
在推薦系統眾多方法中,基於使用者的協同過濾推薦演算法是最早誕生的,原理也較為簡單。該演算法1992年提出並用於郵件過濾系統,兩年後1994年被 GroupLens 用於新聞過濾。一直到2000年,該演算法都是推薦系統領域最著名的演算法。 本文簡單介紹基於使用者的協同
文字挖掘——基於TF-IDF的KNN分類演算法實現
一、專案背景 此專案是用於基建大資料的文字挖掘。首先爬蟲師已經從各個公開網站上採集了大量的文字,這些文字是關於基建行業的各種招中標公告,文本里會有部分詞彙明顯或者隱晦的介紹此專案是關於哪一工程類別的,比如公路工程,市政工程,建築工程,軌道交通工程,等等。
基於OpenCV的三種光流演算法實現原始碼及測試結果
本文包括基於OpenCV的三種光流演算法的實現原始碼及測試結果。具體為HS演算法,LK演算法,和ctfLK演算法,演算法的原實現作者是Eric Yuan,這裡是作者的部落格主頁:http://eric-yuan.me。本文對這三種光流演算法進行了相關除錯及結果驗證,供大家
字串匹配演算法總結 (分析及Java實現)
字串模式匹配演算法(string searching/matchingalgorithms) 顧名思義,就是在一個文字或者較長的一段字串中,找出一個或多個指定字串(Pattern),並返回其位置。這類演算法屬基礎演算法,各種程式語言都將其
影象配準】基於灰度的模板匹配演算法(一):MAD、SAD、SSD、MSD、NCC、SSDA、SATD演算法
簡介: 本文主要介紹幾種基於灰度的影象匹配演算法:平均絕對差演算法(MAD)、絕對誤差和演算法(SAD)、誤差平方和演算法(SSD)、平均誤差平方和演算法(MSD)、歸一化積相關演算法(NCC)、序貫相似性檢測演算法(SSDA)、hadamard變換演算法(
php 基於redis使用令牌桶演算法實現流量控制
本文介紹php基於redis,使用令牌桶演算法,實現訪問流量的控制,提供完整演算法說明及演示例項,方便大家學習使用。 每當國內長假期或重要節日時,國內的景區或地鐵都會人山人海,導致負載過大,部分則會採用限流措施,限制進入的人數,當區內人數降低到一定值,再允