
演算法之美——求解 字串間最短距離(動態規劃)
Minimum Edit Distance 問題
解法一:
對於不同的字串,判斷其相似度。
定義了一套操作方法來把兩個不相同的字串變得相同,具體的操作方法為:
1.修改一個字元(如把“a”替換為“b”)
2.增加一個字元(如把“abdd”變為“aebdd”)
3.刪除一個字元(如把“travelling”變為“traveling”)
定義:把這個操作所需要的最少次數定義為兩個字串的距離,而相似度等於“距離+1”的倒數
採用遞迴的思想將問題轉化成規模較小的同樣的問題。
u如果兩個串的第一個字元相同,如A=xabcdae和B=xfdfa,只要計算A[2,…,7]=abcdae和B[2,…,5]=fdfa的距離就可以了。
1.刪除A串的第一個字元,然後計算A[2,…,lenA]和B[1,…,lenB]的距離。
2.刪除B串的第一個字元,然後計算A[1,…,lenA]和B[2,…,lenB]的距離。
3.修改A串的第一個字元為B串的第一個字元,然後計算A[2,…,lenA]和
B[2,…,lenB]的距離。
4.修改B串的第一個字元為A串的第一個字元,然後計算A[2,…,lenA]和
B[2,…,lenB]的距離。
5.增加B串的第一個字元到A串的第一個字元之前,然後計算
A[1,…,lenA]和B[2,…,lenB]的距離。
6.增加A串的第一個字元到B串的第一個字元之前,然後計算
A[2,…,lenA]和B[1,…,lenB]的距離。
我們並不在乎兩個字串變得相等之後的字串是怎樣的。
可以將上面6個操作合併為:
1.一步操作之後,再將A[2,…,lenA]和B[1,…,lenB]變成相同字串。
2.一步操作之後,再將A[1,…,lenA]和B[2,…,lenB]變成相同字串。
3.一步操作之後,再將A[2,…,lenA]和B[2,…,lenB]變成相同字串。
虛擬碼
[cpp] view plaincopyprint?-
int calculateStringDistance(string strA, int pABegin, intpAEnd, string strB, int pBBegin, int pBEnd)
- {
- if(pABegin > pAEnd) //遞迴終止條件
- {
- if(pBBegin > pBEnd) return 0;
- elsereturn pBEnd - pBBegin + 1;
- }
- if(pBBegin > pBEnd)
- {
- if(pABegin > pAEnd) return 0;
- elsereturn pAEnd - pABegin + 1;
- }
- if(strA[pABegin] == strB[pBBegin]) //演算法核心
- {
- return calculateStringDistance(strA, pABegin+1, pAEnd, strB, pBBegin+1, pBEnd);
- }
- else
- {
- int t1 = calculateStringDistance(strA, pABegin, pAEnd, strB, pBBegin+1, pBEnd);
- int t2 = calculateStringDistance(strA, pABegin+1, pAEnd, strB, pBBegin, pBEnd);
- int t3 = calculateStringDistance(strA, pABegin+1, pAEnd, strB, pBBegin+1, pBEnd);
- return minValue(t1, t2, t3) + 1;
- }
- }
簡潔版
- #define MAX 100
- char s1[MAX];
- char s2[MAX];
- int distance(char *s1,char *s2) //求字串距離
- { int len1=strlen(s1);
- int len2=strlen(s2);
- if(len1==0||len2==0)
- {
- return max(len1,len2);
- }
- if(s1[0]==s2[0]) return distance(s1+1,s2+1);
- elsereturn min(distance(s1,s2+1),distance(s1+1,s2),distance(s1+1,s2+1))+1;
- }
上面的演算法有什麼地方需要改進呢?
演算法中,有些資料被重複計算。

為了避免這種重複計算,我們可以考慮將子問題計算後的解儲存起來
動態規劃 求解
本篇內容將講述Edit Distance(編輯距離的定義詳見正文),具體又包含5個方面的內容:- Defining Minimum Edit Distance
- Computing Minimum Edit Distance
- Backtrace for Computing Alignments
- Weighted Minimum Edit Distance
- Minimum Edit Distance in Computational Biololgy
1. Definition of Minimum Edit Distance
Edit Distance用於衡量兩個strings之間的相似性。 兩個strings之間的Minimum edit distance是指把其中一個string通過編輯(包括插入,刪除,替換操作)轉換為另一個string的最小運算元。 如上圖所示,d(deletion)代表刪除操作,s(substitution)代表替換操作,i(insertion)代表插入操作。
(為了簡單起見,後面的Edit Distance 簡寫為ED)
如果每種操作的cost(成本)為1,那麼ED = 5.
如果s操作的cost為2(即所謂的Levenshtein Distance),ED = 8.
如上圖所示,d(deletion)代表刪除操作,s(substitution)代表替換操作,i(insertion)代表插入操作。
(為了簡單起見,後面的Edit Distance 簡寫為ED)
如果每種操作的cost(成本)為1,那麼ED = 5.
如果s操作的cost為2(即所謂的Levenshtein Distance),ED = 8.
2. Computing Minimum Edit Distance
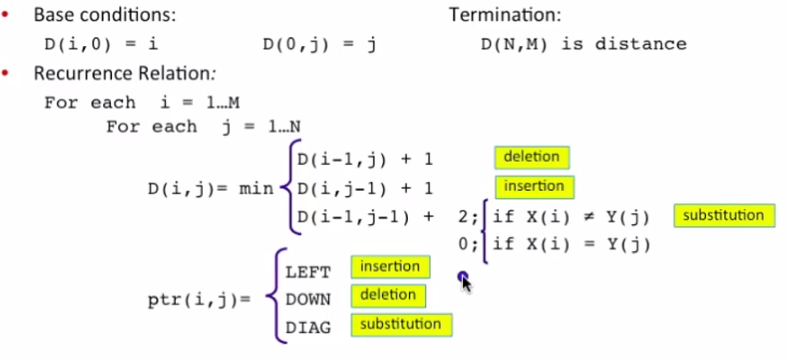
那麼如何找到兩個strings的minimun edit distance呢?要知道把一個string轉換為另一個string可以有很多種方法(或者說“路徑“)。我們所知道起始狀態(第一個string)、終止狀態(另一個string)、基本操作(插入、刪除、替換),要求的是最短路徑。 對於如下兩個strings: X的長度為n Y的長度為m 我們定義D(i,j)為 X 的前i個字元 X[1...i] 與 Y 的前j個字元 Y[1...j] 之間的距離,其中0<i<n, 0<j<m,因此X與Y的距離可以用D(n,m)來表示。 假如我們想要計算最終的D(n,m),那麼可以從頭開始,先計算D(i, j) (i和j從1開始)的值,然後基於前面的結果計算更大的D(i, j),直到最終求得D(n,m)。 演算法過程如下圖所示:
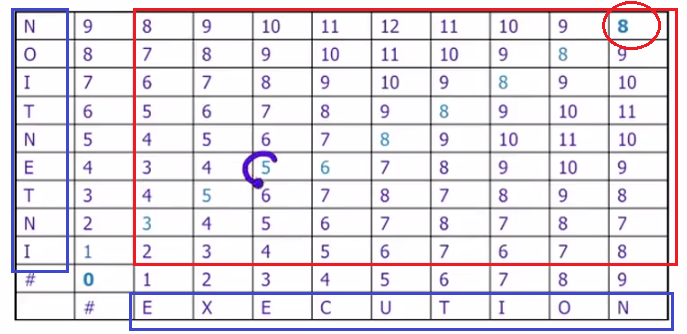
上圖中使用的是”Levenshtein Distance“即替換的成本為2. 請讀者深入理解一下上圖中的迴圈體部分: D(i,j)可能的取值為: 1. D(i-1, j) +1 ; 2. D(i, j-1) +1 ; 3. D(i-1, j-1) + 2 (當X新增加的字元和Y新增加的字元不同時,需要替換)或者 + 0(即兩個字串新增加的字元相同) 下圖即對字串 INTENTION 和 EXECUTION 一步步求ED形成的表。左上角畫紅圈的8就是兩個字串間的最小ED。
3. Backtrace for Computing Alignments
上一節課我們求得了Edit distance,但是僅有Edit distance也是是不夠的,有時我們也需要把兩個strings中的每個字元都一一對應起來(有的字母會與“空白”對應),這可以通過Backtrace(追蹤)ED的計算過程得到。 通過上一節我們知道,D(i, j)的取值來源有三種,D(i-1, j)、D(i, j-1)或者D(i-1, j-1),下表通過新增箭頭的方式顯而易見地給出來整個表格的計算過程(下面的陰影表示的只是一種路徑,你會發現得到最後結果的路徑不是惟一的,因為每個單元格數字可能由左邊、下邊或者左下邊的得到)。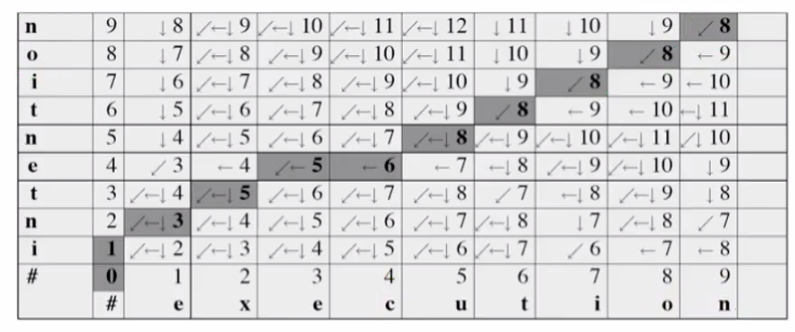
從表格右上角開始,沿著追蹤的剪頭,就可以拎出一條路徑出來(不惟一),這條路徑的剪頭可以輕易的展現是通過哪種方法(插入、刪除、替換)完成的。 表格右上角陰影部分四個格子,路徑只有一條,我們也可以很輕易地看出最後四個字母是相同的,但這種情況並不絕對,比如中間的陰影6格也只有一種路徑,可是卻分別對應於字母e和c。 演算法實現“尋找路徑”的思想很簡單——就是給每個單元格定義一個指標,指標的值為LEFT/DOWN/DIAG(不明白為什麼他為什麼說是指標),如下圖所示。
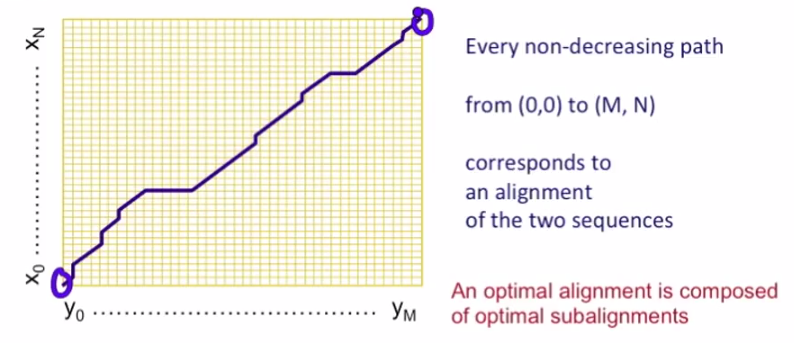
想一下普通的情況,如下圖,從(0,0)到(M,N)的任何一條非下降路徑都對應於兩個strings間的一個排列,而最佳的排列由最佳的子排列組成。
簡單思考一下演算法的效能 Time: O(nm) Space: O(nm) Backtrace: O(n+m)
4. Weighted Minimum Edit Distance
ED也可以新增權重,因為在拼寫中,某些字母更容易寫錯。如下圖顯示的混淆矩陣,數值越大就代表被誤寫的可能性越高。如a就很可能被誤寫為e,i,o,u
眾所周知,鍵盤排佈會對誤寫產生影響。 Weighted Min Edit Distance的演算法如下圖所示

這幅圖將del、ins、sub三種操作都定義了不同的權重,在“萊溫斯基距離“中,del和ins的cost都是1,sub是2。
5. Minimum Edit Distance in Computational Biology
本段講述Minimum Edit Distance在計算生物學中的應用。比如比較如下圖(上班部分)兩個基因組序列,我們希望最後能把兩個序列對齊(下半部分),進而研究不同的基因片段的功能等。
在Natural Language Processing我們討論了最小distance和weight,而在Computational Biology中我們將要介紹最大Similarity(相似性)和scores。 在Computational Biology中有個重要演算法——Needleman-Wunsch演算法。

自然語言處理(NLP)中,有一個基本問題就是求兩個字串的minimal Edit Distance, 也稱Levenshtein distance。受到一篇Edit Distance介紹文章的啟發,本文用動態規劃求取了兩個字串之間的minimal Edit Distance. 動態規劃方程將在下文進行講解。
1. what is minimal edit distance?
簡單地說,就是僅通過插入(insert)、刪除(delete)和替換(substitute)個操作將一個字串s1變換到另一個字串s2的最少步驟數。熟悉演算法的同學很容易知道這是個動態規劃問題。
其實一個替換操作可以相當於一個delete+一個insert,所以我們將權值定義如下:
I (insert):1
D (delete):1
S (substitute):2
2. example:
intention->execution
Minimal edit distance:
delete i ; n->e ; t->e ; insert c ; n->u 求和得cost=8
3.calculate minimal edit distance dynamically
思路見註釋,這裡D[i,j]就是取s1前i個character和s2前j個character所得minimal edit distance
三個操作動態進行更新:
D(i,j)=min { D(i-1, j) +1, D(i, j-1) +1 , D(i-1, j-1) + s1[i]==s2[j] ? 0 : 2};中的三項分別對應D,I,S。
[cpp] view plaincopyprint?- /*
- * minEditDis.cpp
- *
- * @Created on: Jul 10, 2012
- * @Author: sophia
- * @Discription: calculate the minimal edit distance between 2 strings
- *
- * Method : DP (dynamic programming)
- * D[i,j]: the minimal edit distance for s1的前i個字元和 s2的前j個字元
- * DP Formulation: D[i,j]=min(D[i-1,j]+1,D[i,j-1]+1,D[i-1,j-1]+flag);//其中if(s1[i]!=s2[j])則flag=2,else flag=0;
- *
- */
- #include"iostream"
- #include"stdio.h"
- #include"string.h"
- usingnamespace std;
- #define N 100
- #define INF 100000000
- #define min(a,b) a<b?a:b
- int dis[N][N];
- char s1[N],s2[N];
- int n,m;//length of the two string
- int main()
- {
- int i,j,k;
- while(scanf("%s%s",&s1,&s2)!=EOF)
- {
- n=strlen(s1);m=strlen(s2);
- for(i=0;i<=n+1;i++)
- for(j=0;j<=m+1;j++)
- dis[i][j]=INF;
- dis[0][0]=0;
- for(i=0;i<=n;i++)
- for(j=0;j<=m;j++)
- {
- if(i>0) dis[i][j] = min(dis[i][j],dis[i-1][j]+1); //delete
- if(j>0) dis[i][j] = min(dis[i][j],dis[i][j-1]+1);//insert
- //substitute
- if(i>0&&j>0)
- {
- if(s1[i-1]!=s2[j-1])
- dis[i][j] = min(dis[i][j],dis[i-1][j-1]+2);
- else
- dis[i][j] = min(dis[i][j],dis[i-1][j-1]);
- }
- }
- printf("min edit distance is: %d\n",dis[n][m]);
- }
- return 0;
- }
執行結果:
intention
execution
min edit distance is: 8
abc
acbfbcd
min edit distance is: 4
zrqsophia
aihposqrz
min edit distance is: 16
Reference: