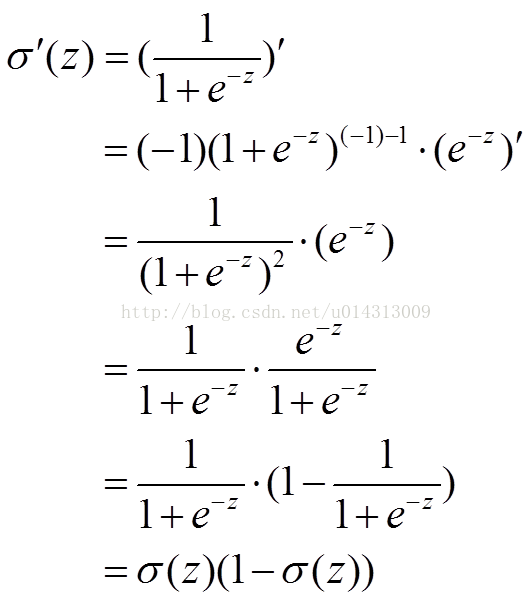交叉熵代價函式(作用及公式推導
交叉熵代價函式(Cross-entropy cost function)是用來衡量人工神經網路(ANN)的預測值與實際值的一種方式。與二次代價函式相比,它能更有效地促進ANN的訓練。在介紹交叉熵代價函式之前,本文先簡要介紹二次代價函式,以及其存在的不足。
1. 二次代價函式的不足
ANN的設計目的之一是為了使機器可以像人一樣學習知識。人在學習分析新事物時,當發現自己犯的錯誤越大時,改正的力度就越大。比如投籃:當運動員發現自己的投籃方向離正確方向越遠,那麼他調整的投籃角度就應該越大,籃球就更容易投進籃筐。同理,我們希望:ANN在訓練時,如果預測值與實際值的誤差越大,那麼在反向傳播訓練的過程中,各種引數調整的幅度就要更大,從而使訓練更快收斂。
以一個神經元的二類分類訓練為例,進行兩次實驗(ANN常用的啟用函式為sigmoid函式,該實驗也採用該函式):輸入一個相同的樣本資料x=1.0(該樣本對應的實際分類y=0);兩次實驗各自隨機初始化引數,從而在各自的第一次前向傳播後得到不同的輸出值,形成不同的代價(誤差):
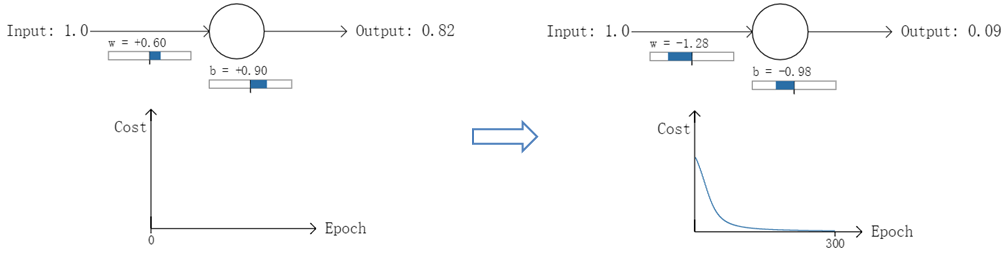
實驗1:第一次輸出值為0.82

實驗2:第一次輸出值為0.98
在實驗1中,隨機初始化引數,使得第一次輸出值為0.82(該樣本對應的實際值為0);經過300次迭代訓練後,輸出值由0.82降到0.09,逼近實際值。而在實驗2中,第一次輸出值為0.98,同樣經過300迭代訓練,輸出值只降到了0.20。
從兩次實驗的代價曲線中可以看出:實驗1的代價隨著訓練次數增加而快速降低,但實驗2的代價在一開始下降得非常緩慢;直觀上看,初始的誤差越大,收斂得越緩慢。
其實,誤差大導致訓練緩慢的原因在於使用了二次代價函式。二次代價函式的公式如下:
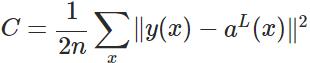
其中,C表示代價,x表示樣本,y表示實際值,a表示輸出值,n表示樣本的總數。為簡單起見,同樣一個樣本為例進行說明,此時二次代價函式為:
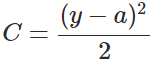
目前訓練ANN最有效的演算法是反向傳播演算法。簡而言之,訓練ANN就是通過反向傳播代價,以減少代價為導向,調整引數。引數主要有:神經元之間的連線權重w,以及每個神經元本身的偏置b。調參的方式是採用梯度下降演算法(Gradient
descent),沿著梯度方向調整引數大小。w和b的梯度推導如下:
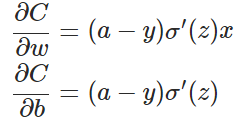
其中,z表示神經元的輸入,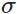
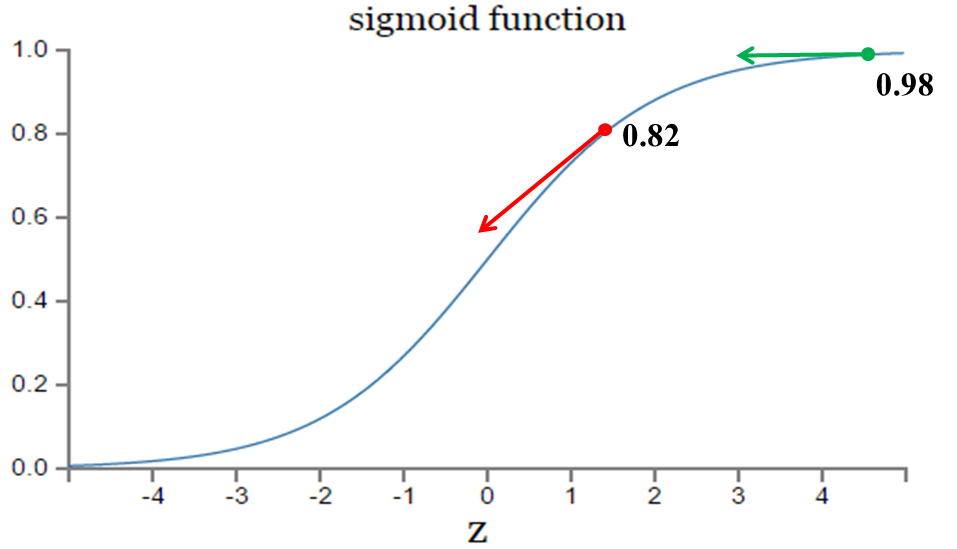
如圖所示,實驗2的初始輸出值(0.98)對應的梯度明顯小於實驗1的輸出值(0.82),因此實驗2的引數梯度下降得比實驗1慢。這就是初始的代價(誤差)越大,導致訓練越慢的原因。與我們的期望不符,即:不能像人一樣,錯誤越大,改正的幅度越大,從而學習得越快。
可能有人會說,那就選擇一個梯度不變化或變化不明顯的啟用函式不就解決問題了嗎?圖樣圖森破,那樣雖然簡單粗暴地解決了這個問題,但可能會引起其他更多更麻煩的問題。而且,類似sigmoid這樣的函式(比如tanh函式)有很多優點,非常適合用來做啟用函式,具體請自行google之。
2. 交叉熵代價函式
換個思路,我們不換啟用函式,而是換掉二次代價函式,改用交叉熵代價函式:
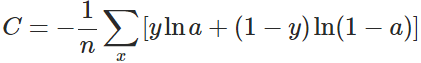
其中,x表示樣本,n表示樣本的總數。那麼,重新計算引數w的梯度:
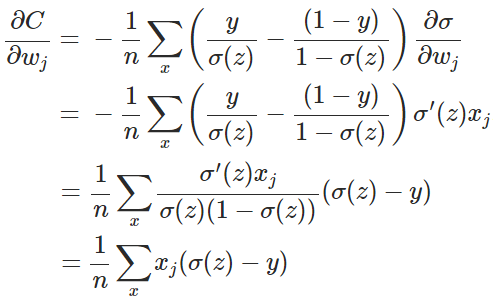
其中(具體證明見附錄):
因此,w的梯度公式中原來的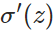

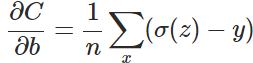
實際情況證明,交叉熵代價函式帶來的訓練效果往往比二次代價函式要好。
3. 交叉熵代價函式是如何產生的?
以偏置b的梯度計算為例,推匯出交叉熵代價函式:
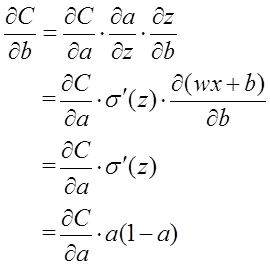
在第1小節中,由二次代價函式推匯出來的b的梯度公式為:
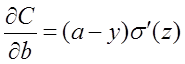
為了消掉該公式中的
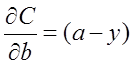
即:
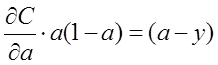
對兩側求積分,可得:
而這就是前面介紹的交叉熵代價函式。
附錄:
sigmoid函式為:

可證: