
編譯原理——LL(1)分析
前言:這是我學習編譯原理,課程實驗的內容,課程早已結束,現整理髮表。
一、實驗任務
- 儲存文法;
- 計算給定文法所有非終結符的
FIRST集合; - 計算給定文法所有非終結符的
FOLLOW集合; - 構造該文法的
LL(1)文法的分析表 - 根據
LL(1)分析表判斷文法是否LL(1)文法; - 完成完整的
LL(1)分析過程。
二、實驗內容
- 確定文法的檔案儲存格式,儲存文法的非終結符集合、開始符號、終結符集合和產生式規則集合。
要求為3個以上測試文法準備好相應的儲存檔案。 - 計算給定文法所有非終結符的
FIRST集合。 - 計算給定文法所有非終結符的
FOLLOW集合; - 確定
LL(1)分析表的檔案儲存格式。
要求為3個以上測試文法準備好相應LL(1)分析表的儲存檔案。 - 根據
LL(1)分析表判斷文法是否LL(1)文法。
看每個表項是否最多隻有一條候選式,如是該文法是LL(1)文法。 - 實現
LL(1)分析過程。
當 5. 判斷出該文法是LL(1)文法時,要求給出3個以上輸入串的LL(1)分析過程,並判斷輸入串是否該文法的合法句子。 - 完成完整的
LL(1)分析過程。
三、儲存格式
- 文法
E->TE`
E`->+TE`|e
T->FT`
T`->*FT`|e
F->(E)|id - 改變
E`用Y代替
T`用X代替- 非終結符號
EYTXF- 終結符號
i+*()$- 文法改寫儲存
E,TY
Y,+TY
Y,e
T,FX
X,*FX
X,e
F,(E)
F,i- 分析表用一個結構體的二維陣列儲存,會很複雜,看程式碼理解。
四、程式設計
- 結構體類
struct.h
注意理清裡面的結構體巢狀。
#include <string>
#ifndef MAXNUM
#define MAXNUM 100
#endif
#ifndef _STRUCT_H
#define _STRUCT_H
/******資料定義******/ - 獲得
first和follow集文法類getFirFol.h
#include "getFirFol.h"
#include "struct.h"
#ifndef _LL_H
#define _LL_H
class LL{
public:
LL(getFirst_Follow *ff,std::string ts, std::string nts, std::string rl);
/***構造分析表***/
void fillInTheTable();
/***分析字串***/
void analyzeChars(std::string path);
/***在對應的分析表單元格加入文法***/
bool addInTableCell(int h,int l,int gramNum);
private:
getFirst_Follow *getff;
std::string terSymbol; //終結符號集合
int tsLength=0; //終結符號數量
std::string nonTerSymbol; //非終結符號集合
int ntsLength=0; //非終結符號數量
rule *grammer = NULL; //文法
int gramNum = 0; //文法公式數目
tableCell **analyzeTable; //預測分析表
bool isLLGrammer=true; //判斷是為LL(1)文法
};
#endif
- 主函式
main.cpp
#include"getFirFol.h"
#include"LL.h"
#include<iostream>
#include<string>
#include<queue>
#include<fstream>
using namespace std;
int main(){
string ts="test1\\terminalSymbol.ll";
string nts="test1\\nonTerminalSymbol.ll";
string rl = "test1\\rule.ll";
string path="test1\\input1.ll";
getFirst_Follow gff(ts,nts,rl);
gff.getFirst();
gff.getFollow();
LL ll(&gff,ts,nts,rl);
ll.fillInTheTable();
ll.analyzeChars(path);
system("pause");
return 0;
}
五、實驗測試
- 文法分析結果

LL(1)分析結果
1)輸入串
i+i*i2) 分析
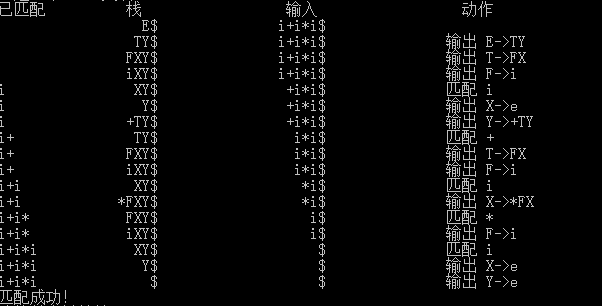
六、實驗總結
哇,東西好少,我也覺得好簡單的感覺,這是還是當初我寫的覺得放棄的程式碼麼?
還是的,如果你看具體程式碼就覺得不那麼簡單了,尤其是入了結構體的坑,覺得用結構體好好用的,然後就不停的用,而上篇的程式碼和這篇的程式碼都是這樣的產物。。。
總之,這篇是最後一篇編譯原理的程式碼了,總共10個實驗,前面4個必寫,後面6個任選2個,要寫6個實驗,然後你會說不對啊,不夠6個啊,系列不是隻有4篇麼?
呃,其實這篇是後面6個實驗中的2個實驗的,分別是獲得first和follow集和用分析表進行LL(1)進行分析兩個實驗的綜合,那還有一個實驗呢?第4個實驗我沒有寫出來,或者說放棄寫了。
為什麼?因為第四個實驗要構建完整的語法分析程式!
不想寫了,太累了,老實說寫這個和前一個實驗花了我很多時間和精力的,程式碼完全是我自己寫的,沒有參考其他的人的,本來就臨近期末了,就放棄了。改tiny的語法分析提交一些實驗內容,就沒有寫後面的自己定義的語法分析器了。太累了。
老實說,當初寫完的時候要我分享我辛辛苦苦寫的程式碼給別人我是一百個不願意的,因為按我的想法,憑什麼你就能輕鬆的獲得我的勞動成果,我在辛苦寫的時候你輕鬆玩,然後再來拿我的成果,不可以,不行,不願意。不過,也沒有人來說來拿我的程式碼,因為有其他人寫好的,人也比我更好接觸,即使知道我寫好能用了驗收過了,也沒有人來要我的程式碼,因為我是個不愛分享的人,或者說,自私的人。
那你怎麼又拿出來了?因為還是想要自己的成果能讓別人知道的,積灰還不如造福下社會,畢竟我也是在網上學到很多東西的人,反補下也是合理的,至於有沒有幫助到就不得而知了。
不過,我有個請求,如果你是參考了我的程式碼的寫的,請不要說完全是自己寫的,你就說是從網上參考的,那我就很開心的了。
廢話完了,程式碼還是很難看懂的,希望能耐心看一看,會有些幫助。
七、資料下載
程式碼詳見LL(1)。
編譯原理——Fin