
人工智障學習筆記——深度學習(2)卷積神經網路
上一章最後提到了多層神經網路(deep neural network,DNN),也叫多層感知機(Multi-Layer perceptron,MLP)。
當下流行的DNN主要分為應對具有空間性分佈資料的CNN(卷積神經網路)和應對具有時間性分佈資料的RNN(遞迴神經網路,又稱迴圈神經網路)。
概念
CNN是一種前饋神經網路,它的人工神經元可以響應一部分覆蓋範圍內的周圍單元,對於大型影象處理有出色表現。與普通神經網路非常相似,它們都由具有可學習的權重和偏置常量(biases)的神經元組成。每個神經元都接收一些輸入,並做一些點積計算,輸出是每個分類的分數,普通神經網路裡的一些計算技巧到這裡依舊適用。
CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由於CNN的特徵檢測層通過訓練資料進行學習,所以在使用CNN時,避免了顯示的特徵抽取,而隱式地從訓練資料中進行學習;再者由於同一特徵對映面上的神經元權值相同,所以網路可以並行學習,這也是卷積網路相對於神經元彼此相連網路的一大優勢。卷積神經網路以其區域性權值共享的特殊結構在語音識別和影象處理方面有著獨特的優越性,其佈局更接近於實際的生物神經網路,權值共享降低了網路的複雜性,特別是多維輸入向量的影象可以直接輸入網路這一特點避免了特徵提取和分類過程中資料重建的複雜度。
結構
卷積神經網路通常包含以下幾種層:
卷積層(Convolutional layer)
池化層(Pooling layer),通常在卷積層之後會得到維度很大的特徵,將特徵切成幾個區域,取其最大值或平均值,得到新的、維度較小的特徵。
全連線層( Fully-Connected layer), 把所有區域性特徵結合變成全域性特徵,用來計算最後每一類的得分。
1.卷積層
每一層計算的操作本質上即輸入層和權重的卷積!這也就是卷積神經網路名字的由來。
主要引數:
W : 輸入單元的大小(寬或高)
F : 感受野(receptive field)
S : 步幅(stride)
P : 補零(zero-padding)的數量
K : 深度,輸出單元的深度
2.池化層
池化(pool)即下采樣(downsamples),目的是為了減少特徵圖。池化操作對每個深度切片獨立,規模一般為 2*2,相對於卷積層進行卷積運算,池化層進行的運算一般有以下幾種:
最大池化(Max Pooling)。取4個點的最大值。這是最常用的池化方法。
均值池化(Mean Pooling)。取4個點的均值。
高斯池化。借鑑高斯模糊的方法。不常用。
可訓練池化。訓練函式 ff ,接受4個點為輸入,出入1個點。不常用。
3.全連線層
全連線層和卷積層可以相互轉換:
對於任意一個卷積層,要把它變成全連線層只需要把權重變成一個巨大的矩陣,其中大部分都是0 除了一些特定區塊(因為區域性感知),而且好多區塊的權值還相同(由於權重共享)。
相反地,對於任何一個全連線層也可以變為卷積層。比如,一個K=4096 的全連線層,輸入層大小為 7∗7∗512,它可以等效為一個 F=7, P=0, S=1, K=4096 的卷積層。換言之,我們把 filter size 正好設定為整個輸入層大小。
特點
1.區域性感知:通過上一章可以看出,傳統神經網路把輸入層和隱含層進行全連線,這使得計算量非常的龐大。而卷積神經網路在這部分進行了優化,即巻積層對隱含單元和輸入單元間的連線加以限制:每個隱含單元僅僅只能連線輸入單元的一部分。每個隱含單元連線的輸入區域大小叫r神經元的感受野(receptive field)。卷積層的引數包含一系列過濾器(filter),每個過濾器訓練一個深度,有幾個過濾器輸出單元就具有多少深度。
2.權重共享:我們把同一深度的平面叫做深度切片,那麼同一個切片應該共享同一組權重和偏置。我們仍然可以使用梯度下降的方法來學習這些權值,只需要對原始演算法做一些小的改動, 這裡共享權值的梯度是所有共享引數的梯度的總和。這樣做的好處是重複單元能夠對特徵進行識別,而不考慮它在可視域中的位置。另一方面,權重共享使得我們能更有效的進行特徵抽取,因為它極大的減少了需要學習的自由變數的個數。通過控制模型的規模,卷積網路對視覺問題可以具有很好的泛化能力。
3.多卷積核&層&map
深度調參是門手藝,卷積神經網路的卷積核大小、卷積層數、每層map個數等對其效果及計算量都影響巨大,卷積網路本身就是個bp網路, 他調整卷積核的權值是跟資料傳播完全逆向的過程。對於某層的實際輸出和目標輸出的差值。需要對這一層進行權值矩陣的導數求解,即雅各比行列式。然後再逆向對上一層做同樣的修正(即訓練) 所以層數決定調整的迭代次數。至於其側重方向,有一位大♂師曾這樣說過:喜歡小而深,厭惡大而短。

框架
CNN主要流行框架有:
1.Caffe:源於Berkeley的主流CV工具包,支援C++,python,matlab,Model Zoo中有大量預訓練好的模型供使用
2.TensorFlow:Google的深度學習框架,TensorBoard視覺化很方便,資料和模型並行化好,速度快
3.Torch:Facebook用的卷積神經網路工具包,通過時域卷積的本地介面,使用非常直觀,定義新網路層簡單
例項程式碼:
以降維小結內章的手寫數字為例(python的TensorFlow框架):

import tensorflow as tf
from sklearn.datasets import load_digits
import numpy as np
from time import time
digits = load_digits()
X_data = digits.data.astype(np.float32)
Y_data = digits.target.astype(np.float32).reshape(-1,1)
#print (X_data.shape)
#print (Y_data.shape)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
from sklearn.preprocessing import OneHotEncoder
Y = OneHotEncoder().fit_transform(Y_data).todense() #one-hot編碼
# 轉換為圖片的格式 (batch,height,width,channels)
X = X_data.reshape(-1,8,8,1)
batch_size = 8 # 使用MBGD演算法,設定batch_size為8
def generatebatch(X,Y,n_examples, batch_size):
for batch_i in range(n_examples // batch_size):
start = batch_i*batch_size
end = start + batch_size
batch_xs = X[start:end]
batch_ys = Y[start:end]
yield batch_xs, batch_ys # 生成每一個batch
tf.reset_default_graph()
# 輸入層
tf_X = tf.placeholder(tf.float32,[None,8,8,1])
tf_Y = tf.placeholder(tf.float32,[None,10])
# 卷積層+啟用層
conv_filter_w1 = tf.Variable(tf.random_normal([3, 3, 1, 10]))
conv_filter_b1 = tf.Variable(tf.random_normal([10]))
relu_feature_maps1 = tf.nn.relu(\
tf.nn.conv2d(tf_X, conv_filter_w1,strides=[1, 1, 1, 1], padding='SAME') + conv_filter_b1)
# 池化層
max_pool1 = tf.nn.max_pool(relu_feature_maps1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
print (max_pool1)
# 卷積層
conv_filter_w2 = tf.Variable(tf.random_normal([3, 3, 10, 5]))
conv_filter_b2 = tf.Variable(tf.random_normal([5]))
conv_out2 = tf.nn.conv2d(relu_feature_maps1, conv_filter_w2,strides=[1, 2, 2, 1], padding='SAME') + conv_filter_b2
print (conv_out2)
# BN歸一化層+啟用層
batch_mean, batch_var = tf.nn.moments(conv_out2, [0, 1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros([5]))
scale = tf.Variable(tf.ones([5]))
epsilon = 1e-3
BN_out = tf.nn.batch_normalization(conv_out2, batch_mean, batch_var, shift, scale, epsilon)
print (BN_out)
relu_BN_maps2 = tf.nn.relu(BN_out)
# 池化層
max_pool2 = tf.nn.max_pool(relu_BN_maps2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='SAME')
print (max_pool2)
# 將特徵圖進行展開
max_pool2_flat = tf.reshape(max_pool2, [-1, 2*2*5])
# 全連線層
fc_w1 = tf.Variable(tf.random_normal([2*2*5,50]))
fc_b1 = tf.Variable(tf.random_normal([50]))
fc_out1 = tf.nn.relu(tf.matmul(max_pool2_flat, fc_w1) + fc_b1)
# 輸出層
out_w1 = tf.Variable(tf.random_normal([50,10]))
out_b1 = tf.Variable(tf.random_normal([10]))
pred = tf.nn.softmax(tf.matmul(fc_out1,out_w1)+out_b1)
loss = -tf.reduce_mean(tf_Y*tf.log(tf.clip_by_value(pred,1e-11,1.0)))
train_step = tf.train.AdamOptimizer(1e-3).minimize(loss)
y_pred = tf.argmax(pred,1)
bool_pred = tf.equal(tf.argmax(tf_Y,1),y_pred)
accuracy = tf.reduce_mean(tf.cast(bool_pred,tf.float32)) # 準確率
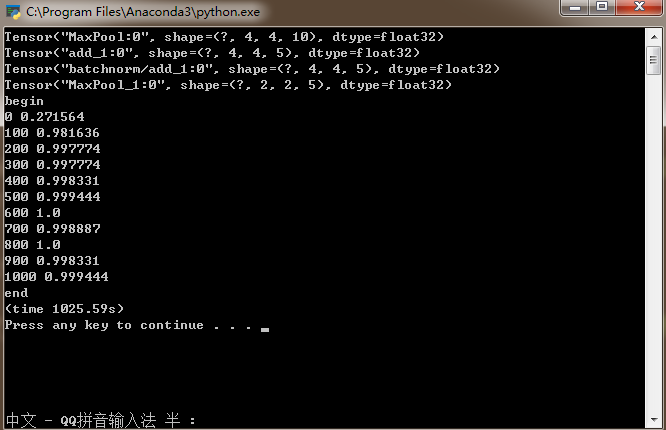
print ('begin')
t0 = time()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(1001): # 迭代週期
for batch_xs,batch_ys in generatebatch(X,Y,Y.shape[0],batch_size): # 每個週期進行MBGD演算法
sess.run(train_step,feed_dict={tf_X:batch_xs,tf_Y:batch_ys})
if(epoch%100==0):
res = sess.run(accuracy,feed_dict={tf_X:X,tf_Y:Y})
print (epoch,res)
res_ypred = y_pred.eval(feed_dict={tf_X:X,tf_Y:Y}).flatten() # 只能預測一批樣本,不能預測一個樣本
#print (res_ypred)
print ('end')
print ("(time %.2fs)" %(time() - t0))其準確率:
相關學習資源