
PCA主成分數量(降維維度)選擇
阿新 • • 發佈:2019-02-02
介紹
我們知道,PCA是用於對資料做降維的,我們一般用PCA把m維的資料降到k維(k < m)。
那麼問題來了,k取值多少才合適呢?
PCA誤差
PCA的原理是,為了將資料從n維降低到k維,需要找到k個向量,用於投影原始資料,是投影誤差(投影距離)最小。
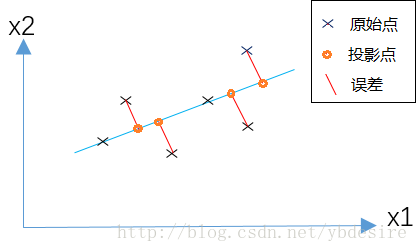
用公式來表示,如下
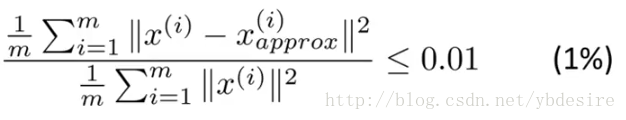
其中
- m表示特徵個數
分子表示原始點與投影點之間的距離之和,而誤差越小,說明降維後的資料越能完整表示降維前的資料。如果這個誤差小於0.01,說明降維後的資料能保留99%的資訊。
k值選取的原理
實際應用中,我們一般根據上式,選擇能使誤差小於0.01(99%的資訊都被保留)或0.05(95%的資訊都被保留)的k值。
而在實際編碼中,參考文章《詳解主成分分析PCA》,在PCA的實現過程中,對協方差矩陣做奇異值分解時,能得到S矩陣(特徵值矩陣)。
PCA誤差的表示式等效於下式
從程式碼示例中,可以看出,將資料從三維降到二維,保留了99.997%的資訊。
[U,S,V] = np.linalg.svd(sigma) # 奇異值分解
(S[0]+S[1])/(S[0]+S[1]+S[2])
# result = 0.99996991682077252實際使用
用sklearn封裝的PCA方法,做PCA的程式碼如下。PCA方法引數n_components,如果設定為整數,則n_components=k。如果將其設定為小數,則說明降維後的資料能保留的資訊。
from sklearn.decomposition import PCA
import numpy as np
from sklearn.preprocessing import StandardScaler
x=np.array([[10001,2,55], [16020,4,11], [12008,6,33], [13131,8,22]])
# feature normalization (feature scaling)
X_scaler = StandardScaler()
x = X_scaler.fit_transform(x)
# PCA
pca = PCA(n_components=0.9 所以在實際使用PCA時,我們不需要選擇k,而是直接設定n_components為float資料。
總結
PCA主成分數量k的選擇,是一個數據壓縮的問題。通常我們直接將sklearn中PCA方法引數n_components設定為float資料,來間接解決k值選取問題。
但有的時候我們降維只是為了觀測資料(visualization),這種情況下一般將k選擇為2或3。