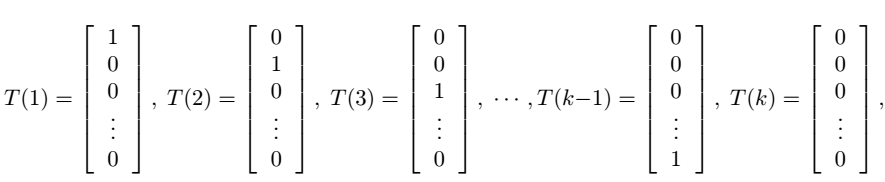廣義線性模型(Generalized Linear Models, GLM)
轉載地址:http://lib.csdn.net/article/machinelearning/39601
1. 指數分佈族
首先,我們先來定義指數分佈族(exponential family),如果一類分佈可以寫成如下的形式,那麼它就是屬於指數分佈族的:
這裡η叫做分佈的自然引數(natural parameter),或者叫標準引數(canonical parameter);T(y)是充分統計量( sufficient statistic),對於我們考慮的大多數分佈,T(y)=y;然後a(η)叫做log partition function
這個指數分佈族是何方神聖呢?為什麼要先講它呢?因為我們前面講過的伯努利分佈和高斯分佈都可以歸為指數分佈族的一種。什麼?這兩個長得毫不相關的分佈可以歸為一起嗎?我的天吶,這麼神奇嗎?(小嶽嶽臉)哈哈,是的!下面我們就來說一說這是怎麼回事。
伯努利分佈就是我們前面講的y只能取0和1時的情況,它就可以變成指數分佈族的形式,我們試一試:
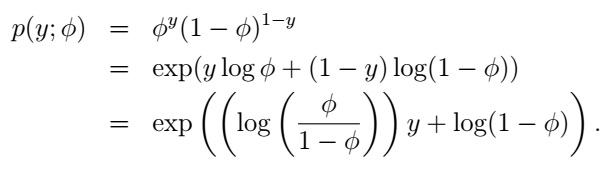
這裡,我們選擇自然引數η=log(ϕ/(1−ϕ)),誒,有個很有趣的事情:如果我們用η表示ϕ,我們可以得到ϕ=1/(1+e−η),是不是很眼熟?這不就是sigmoid function嗎?沒錯!更神奇的還在後面呢。現在我們把伯努利分佈寫成了指數分佈族的形式。什麼?不是很明顯?它們的對應關係是這樣的:
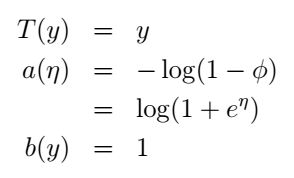
好,我們再來說高斯分佈。前面我們說了,高斯分佈的σ2對模型的結果是沒有影響的那我們就乾脆令它為1好了(其實如果我們把它當做變數,依然行的通,只是得到的η將會是二維的)。高斯分佈也寫成指數分佈族的形式,推導是這樣的:
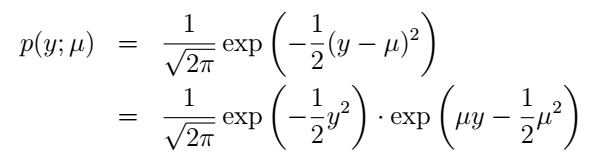
它與指數分佈族的對應關係為:
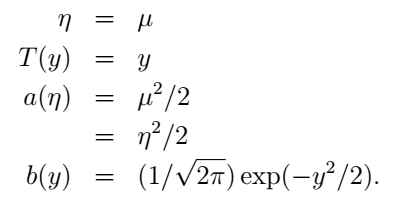
上面我們展示了伯努利和高斯分佈,實際上,還有multinomial(後面將會談到),泊松分佈,gamma和指數分佈,beta和狄裡克雷分佈等等都是屬於指數分佈族的。怎麼樣,這個廣義線性模型還是有兩下子的的,原來我們前面討論的分類都可以統一為指數分佈族的形式。但這還不夠,我們怎麼從指數分佈族中推出我們想要的東西呢?下面我們就來看一看怎樣通過構造廣義線性模型來解決實際問題。
2. 構造GLMs
現在我們來把之前的分類問題擴充套件一下。生活中的很多事物肯定不止一個種類,我們來考慮多類別的分類問題,討論一下如何利用GLMs來解決。
首先,和之前一樣,我們構造模型都是有一定的條件的。我們先來作三個假設:
1. y|x;θ∼ExpoentialFamily(η)。這當然是必須的,我們就是要用指數分佈族來解決問題嘛。
2. 我們的目標是給定x,預測T(y)期望。比如我們剛才說了,大多數情況下T(y)=y,而在邏輯迴歸問題中,我們要預測的hθ=p(y=1|x;θ)=0⋅p(y=0|x;θ)+1⋅(y=1|x;θ)=E[y|x;θ]。
3. 自然引數η滿足η=θTx。
如果我們的問題需要滿足這三個假設,那麼我們就可以通過構造廣義線性模型來解決。線性迴歸和邏輯迴歸都是滿足這三個假設的,就可以使用這個模型。
2.1 普通的最小平方(Ordinary Least Squares)問題
線上性迴歸的最小平方問題中,目標變數y(在GLM的術語中也稱作響應變數(response variable))是連續的,給定x,y的條件分佈符合我們剛剛討論過的高斯分佈,均值為μ。套用前面GLM的推導,我們有μ=η。所以,我們可以得到線性迴歸的假設函式就是: 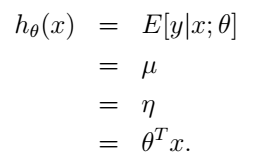
這樣,我們就從廣義線性模型的角度得到了線性迴歸的解決方案。
2.2 邏輯迴歸
在二元分類問題中,給定x,y服從我們剛才討論的伯努利分佈,均值為ϕ。同樣利用前面的推導我們可以得到邏輯迴歸的假設函式就是: 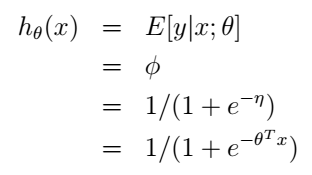
最後一個等號是由前面第3個假設的到的。同樣的,我們也從廣義線性模型的角度得到了邏輯迴歸的解決方案。這裡,我們就知道了為什麼在邏輯迴歸中我們的假設函式要用sigmoid function了吧,並不是憑空才出來的喔。
這裡我們介紹幾個術語。g(η)=E[T(y);η]被稱為canonical
response function,它的反函式g−1,被稱為canonical
link function。
2.3 Softmax Regression
好了,鋪墊了這麼久,我們終於可以考慮我們的多類別分類的問題了,我們首先用multinomial distribution來給它建立模型。假設我們的類別y∈{1,2,…,k}。我們可以用一個k維的向量來表示分類結果,當y=i時,向量的第i個元素為1,其它均為零。但這樣做是存在冗餘的,因為如果我們知道了前k-1個元素,那麼第k個其實就已經確定了,也就是說,這k個元素不獨立。因此我們可以只用k-1維向量來表示,每一維對應的引數為ϕi。為了方便,我們也使用ϕk,但應該記住,它並不是一個真正的引數,它只表示ϕk=1−∑k−1i=1ϕi。這樣我們可以定義:
注意,這裡就和前面T(y)=y不一樣了,這裡的T(y)是一個向量了。我們用(T(y))i表示T(y)的第i個元素。
為了表示方便,我們用符號1{⋅}表示判斷,{}中的表示式為真時輸出1,為假時輸出0。於是我們有(T(y))i=1{y=i},它表示只有當y=i時(T(y))i才不為零。另外,由於ϕi表示第i個類別的概率,我們有E[(T(y))i]=P(y=i)=ϕi。
好,我們仿照前面二元分類的過程,來說明這個multinomial也是屬於指數分佈族的:
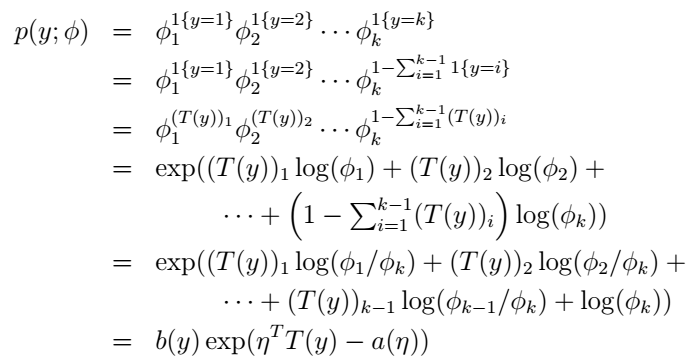
這裡,
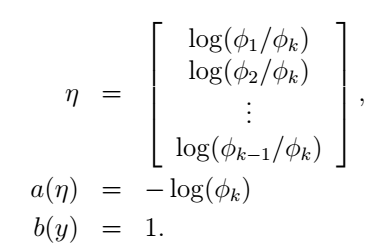
我們可以看到:
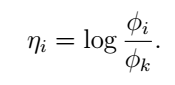
當i=0時上式為零。我們的目的是為了得到引數ϕ,於是
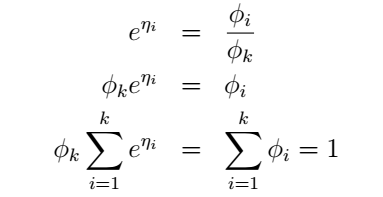
最後我們終於得到:
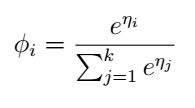
我們再利用假設3,就可以得到引數ϕ了:
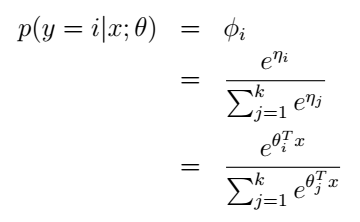
這個模型就被稱為softmax regression,它是邏輯迴歸在多類別情況下的擴充套件。綜合起來,我們的假設函式的輸出為:
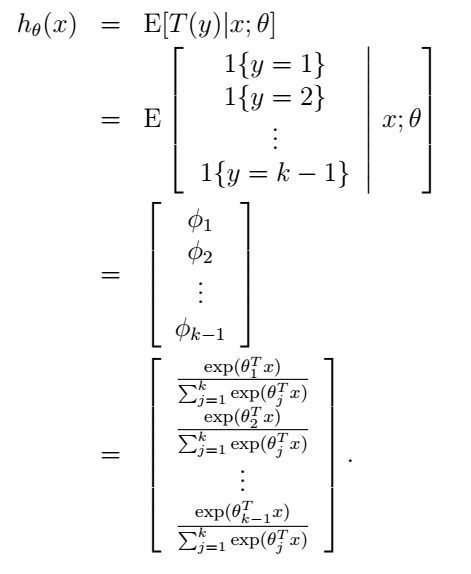
最後就是引數的學習了。我們依然可以使用最大似然的方法來學習θ,似然函式為:
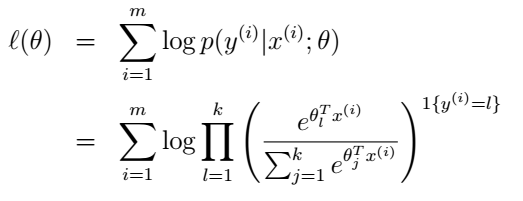
然後使用梯度上升或牛頓方法等來求出使似然函式最大的θ值,就大功告成了!