
損失函式改進總結
阿新 • • 發佈:2019-02-03
深度學習交流QQ群:116270156
這篇部落格主要列個引導表,簡單介紹在深度學習演算法中損失函式可以改進的方向,並給出詳細介紹的部落格連結,會不斷補充。
1、Large Marge Softmax Loss
ICML2016提出的Large Marge Softmax Loss(L-softmax)通過在傳統的softmax loss公式中新增引數m,加大了學習的難度,逼迫模型不斷學習更具區分性的特徵,從而使得類間距離更大,類內距離更小。核心內容可以看下圖:
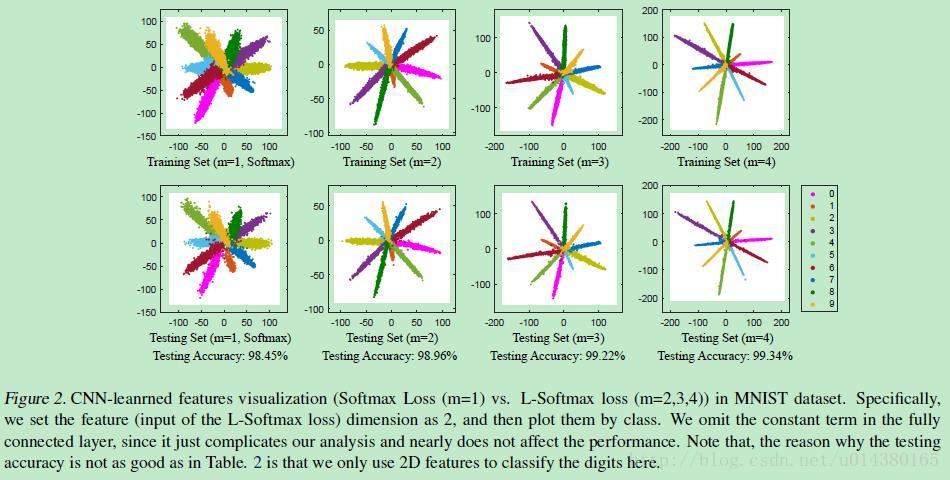
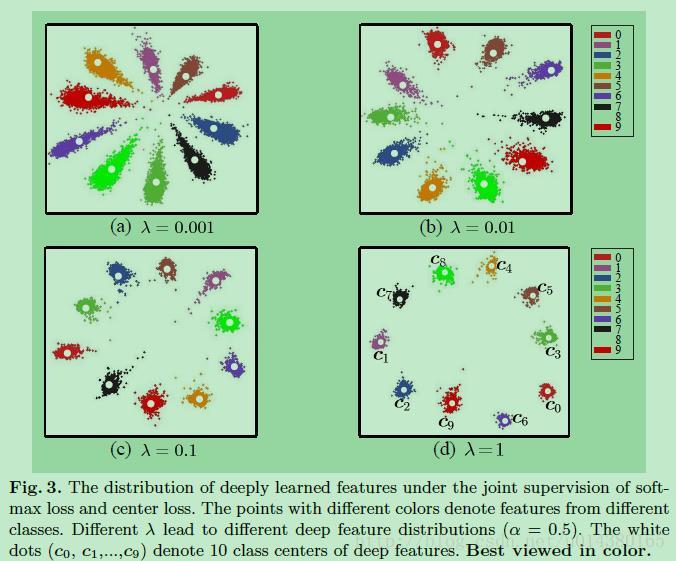
2、Center Loss
ECCV2016提出的center loss是通過將特徵和特徵中心的距離和softmax loss一同作為損失函式,使得類內距離更小,有點L1,L2正則化的意思。核心內容如下圖所示:
3、A-softmax Loss
CVPR2017提出的A-softmax loss(angular softmax loss)用來改進原來的softmax loss。A-softmax loss簡單講就是在large margin softmax loss的基礎上添加了兩個限制條件||W||=1和b=0,使得預測僅取決於W和x之間的角度。核心思想可以參看下面這個圖。
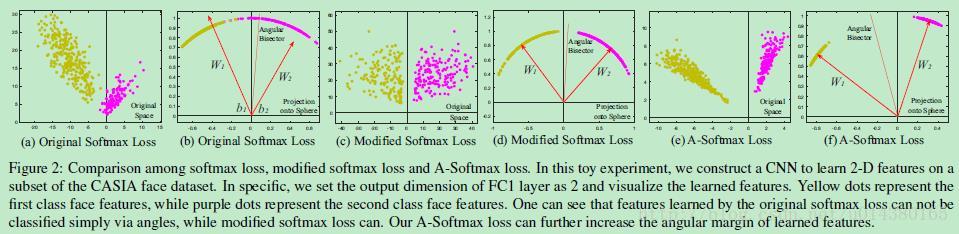
4、Focal Loss
這是Facebook的RBG和Kaiming大神前天放在arxiv的新作,立馬就引來了業界的圍觀,在COCO資料集上的AP和速度都有明顯提升。核心思想在於概括了object detection演算法中proposal-free一類演算法準確率不高的原因在於:類別不均衡。於是在傳統的交叉熵損失上進行修改得到Focal Loss