
logistic 演算法 及其程式碼實現
阿新 • • 發佈:2019-02-05
logistic regression model
這個模型是用來解決分類問題的一種常用的模型,當然在解決這個種模型的時候仍然需要用到梯度下降法。
在這個模型中 我們設定一個個 cost function (x,y);
它等於下面的一個等式
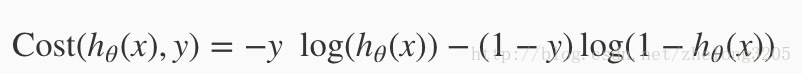
關於這個公式的來源,並不是沒有他內在的數學原理,他的數學原理需要用到概率論中的極大似然估計法,以及高等數學中的微積分,如果感興趣的話可以看一下這個部落格 解釋的十分詳細 :
我們注意到這個函式的一個特徵
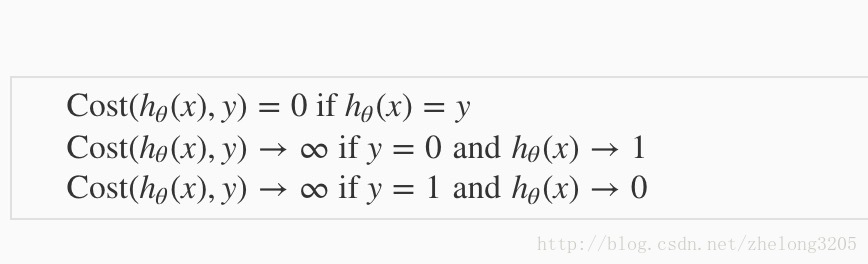
cost 是預測出來的值,我們發現這個函式可以充分反映出 theta 與 y 的偏差。
其中的 h 函式為

因為 y 的取值只有 0 和 1 所以說這個函式還是可以充分反映出代價函式的變化的。至於為什麼選擇這樣的一個函式原因有下面兩點
1. 這個函式可以更快、更方便的找到 theta 的值
2. 這個函式有一個隱藏的優點就是,這個函式自身是一個凸函式,這樣就保證了我們在使用梯度下降的時候可以收斂到一個區域性最優解,這是非常必要的
這個時候我們得到的代價函式 J (theta) 便也得到了這個函式的表示式

我們現在的目的便是最小化這個函式 J 。
最小化函式我們學過兩種辦法,一種叫做正規方程法,另外一種叫做梯度下降法,由於正規方程法只適用於線性迴歸 (因為線性模型在求導的時候具有特殊的形式,解導數等於零就可以解出這個特殊方程,但是要注意這個方程可能沒有解),所以我們在最小化這個 函式的時候要用到梯度下降法。
梯度下降法的所有的條件不變類似於什麼 標準化還是需要的,特點也存在,那個便是這個j 的偏導數。

這基本上就是整個模型的演算法流程,得到theta 的值以後就可以對新出現的值進行預測了
# 將包匯入