
偏置方差分解Bias-variance Decomposition
偏置-方差分解(Bias-Variance Decomposition)
偏置-方差分解(Bias-Variance Decomposition)是統計學派看待模型複雜度的觀點。Bias-variance 分解是機器學習中一種重要的分析技術。給定學習目標和訓練集規模,它可以把一種學習演算法的期望誤差分解為三個非負項的和,即本真噪音noise、bias和 variance。
noise 本真噪音是任何學習演算法在該學習目標上的期望誤差的下界;( 任何方法都克服不了的誤差)
bias 度量了某種學習演算法的平均估計結果所能逼近學習目標的程度;(獨立於訓練樣本的誤差,刻畫了匹配的準確性和質量:一個高的偏置意味著一個壞的匹配)
variance 則度量了在面對同樣規模的不同訓練集時,學習演算法的估計結果發生變動的程度。(相關於觀測樣本的誤差,刻畫了一個學習演算法的精確性和特定性:一個高的方差意味著一個弱的匹配)
偏差度量了學習演算法期望預測與真實結果的偏離程度,即刻畫了學習演算法本身的擬合能力;方差度量了同樣大小的訓練集的變動所導致的學習效能的變化,即刻畫了資料擾動所造成的影響;噪聲表達了在當前任務上任何學習演算法所能達到的期望泛化誤差的下界,即刻畫了學習問題本身的難度……泛化效能是由學習演算法的能力、資料的充分性以及學習任務本身的難度所共同決定的。給定學習任務,為了取得好的泛化效能,則需使偏差較小,即能夠充分擬合數據,並且使方差較小,即使得資料擾動產生的影響小。-周志華《機器學習》
期望誤差
整的來說,誤差可以分為3個部分

偏置方差
而誤差中的偏置方差部分是通過下式分解得到的:
假設我們有K個數據集,每個資料集都是從一個分佈p(t,x)中獨立的抽取出來的(t代表要預測的變數,x代表特徵變數)。對於每個資料集D,我們都可以在其基礎上根據學習演算法來訓練出一個模型y(x;D)來。在不同的資料集上進行訓練可以得到不同的模型。學習演算法的效能是根據在這K個數據集上訓練得到的K個模型的平均效能來衡量的,亦即:

其中的h(x)代表生成資料的真實函式,亦即t=h(x)。
我們可以看到,給定學習演算法在多個數據集上學到的模型的和真實函式h(x)之間的誤差,是由偏置(Bias)和方差(Variance)兩部分構成的。
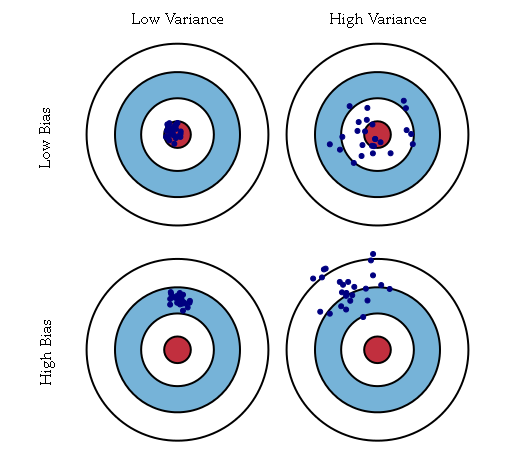
其中偏置描述的是學到的多個模型和真實的函式之間的平均誤差,而方差描述的是學到的某個模型和多個模型的平均之間的平均誤差(PRML上的原話是variance measures the extent to which the solutions for individual data sets vary around their average)。偏置刻畫的是構建的模型和真實模型之間的差異。例如資料集所反映的真實模型為二次模型,但是構建的是線性模型,則該模型的結果總是和真實值結果直接存在差異,這種差異是有構建的模型的不準確所導致的,即為偏置bias;如上圖中的下面兩個圖,真實的模型是紅心(即每次都是要瞄準紅心的),但是構建的模型是偏離紅心的(即在射擊時瞄準的是紅心偏上方向)。方差刻畫的是構建的模型自身的穩定性。例如資料集本身是二次模型,但是構建的是三次模型,對於多個不同的訓練集,可以得到多個不同的三次模型,那麼對於一個固定的測試點,這多個不同的三次模型得到多個估計值,這些估計值之間的差異即為模型的方差;如上圖中的右側兩圖,不論構建的模型是否是瞄準紅心,每個模型的多次結果之間存在較大的差異。
推導
期望損失

迴歸問題中,損失函式的一個通常的選擇是平方損失

最優解h(x):條件均值

變分法求解

當然,其實我們可以不嚴謹地直接假設解是條件均值,直接變成bias--var + 噪聲從最小化只與第一項相關看出解是對的。
損失分解
暫時叫這個名字吧,就是將期望損失分解成bias--var + 噪聲


偏置-方差分解
如果我們使用由引數向量 w 控制的函式 y(x, w) 對 h(x) 建模,那麼從貝葉斯的觀點來看,我們模型的不確定性是通過 w 的後驗概率分佈來表示的。
頻率學家的方法涉及到根據資料集 D 對 w 進行點估計,然後試著通過下面的思想實驗來表示估計的不確定性。假設我們有許多資料集,每個資料集的大小為 N ,並且每個資料集都獨立地從分佈 p(t, x) 中抽取。對於任意給定的資料集 D ,我們可以執行我們的學習演算法,得到一個預測函式 y(x; D) 。不同的資料集會給出不同的函式,從而給出不同的平方損失的值。這樣,特定的學習演算法的表現就可以通過取各個資料集上的表現的平均值來進行評估。
考慮公式(3.37)的第一項的被積函式,對於一個特定的資料集 D ,它的形式為


這個量與特定的資料集 D 相關,因此我們對所有的資料集取平均。但是首先我們在括號內加上然後減去 E D [y(x; D)] ,然後展開,最後一項等於零,得


第一項,被稱為平方偏置( bias ),表示所有資料集的平均預測與預期的迴歸函式之間的差異。
第二項,被稱為方差( variance ),度量了對於單獨的資料集,模型所給出的解在平均值附近波動的情況,因此也就度量了函式 y(x; D) 對於特定的資料集的選擇的敏感程度。
考慮整個輸入變數的外部積分得

[prml]
偏置和方差之間的權衡和折中
在偏置和方差之間有一個折中。對於非常靈活的模型來說,偏置較小,方差較大。對於相對固定的模型來說,偏置較大,方差較小。有著最優預測能力的模型時在偏置和方差之間取得最優的平衡的模型。
靈活的模型(次數比較高的多項式)會有比較低的偏置和比較高的方差,而比較嚴格的模型(比如一次線性迴歸)就會得到比較高的偏置和比較低的方差。
示例
下圖形象的說明了以上兩種情況:



訓練正弦資料集100個數據集合,每個集合都包含 N = 25 個數據點,都是獨立地從正弦曲線 h(x) = sin (2πx) [圖中的綠線]抽取的。資料集的編號為 l = 1, . . . , L ,其中 L = 100 ,並且對於每個資料集 D (l) ,我們通過最小化正則化的誤差函式擬合了一個帶有24個高斯基函式的模型,然後給出了預測函式 y ^(l) (x) ,如圖3.5所示。
引數λ控制模型的靈活性(複雜度),λ越大,模型越簡單(嚴格),反之越複雜(靈活)。左圖第一行對應著較大的正則化係數 λ ,這樣的模型的方差很小(因為左側圖中的紅色曲線看起來很相似),但是偏置很大(因為右側圖中的兩條曲線看起來相當不同)。相反,在最後一行,正則化係數 λ 很小,這樣模型的方差較大(因為左側圖中的紅色曲線變化性相當大),但是偏置很小(因為平均擬合的結果與原始正弦曲線十分吻合)。我們看到,小的 λ 使得模型對於各個資料集裡的噪聲的擬合效果非常好,導致了較大的方差。相反,大的 λ 把權值引數拉向零,導致了較大的偏置。
注意,把 M = 25 這種複雜模型的多個解進行平均,會產生對於迴歸函式非常好的擬合,這表明求平均是一個很好的步驟。事實上,將多個解加權平均是貝葉斯方法的核心,雖然這種求平均針對的是引數的後驗分佈,而不是針對多個數據集。

偏置方差分解評價
雖然偏置-方差分解能夠從頻率學家的角度對模型的複雜度提供一些有趣的認識,但是它的實用價值很有限。這是因為偏置-方差分解依賴於對所有的資料集求平均,而在實際應用中我們只有一個觀測資料集。如果我們有大量的已知規模的獨立的訓練資料集,那麼我們最好的方法是把它們組合成一個大的訓練集,這顯然會降低給定複雜度的模型的過擬合程度。
造成偏置和方差的原因除了學習方法的不同和引數的不同(比如λ)之外,資料集本身也會對其造成影響。如果訓練資料集和新資料集的分佈是不同的,會增大偏置。如果訓練資料集過少,會增大方差。
應用

Bagging方法:Bagging是一種再抽樣方法(resampling),對訓練資料進行有放回的抽樣K次(行抽樣和列抽樣,抽樣獨立),生成K份新的訓練資料,在這K個新的訓練資料上訓練得到K個模型,然後使用K個模型的平均來作為新的模型。如:隨機森林。
並行,更小var, data和features大小可以很大。
Boosting方法:誤判抽樣(抽樣依賴)。如Adaboost, GBDT。序列,更小的bias( high var, overfit)。但是加資料可以減小high var。
Ps:Bias-variance decomposition推導2

Note:ED是對所有資料集D求期望,而不是對x或者y。


ref:Bishop. PRML(Pattern Recognization and Machine Learning). p11-16