
資料分析基礎--SQL
阿新 • • 發佈:2019-02-10
我們在做資料分析的工作時,會用到大量的資料,而這些資料都來自於資料庫,SQL可以讓我們很方便的去訪問和查詢資料庫。
作為一個數據分析師,我們需要掌握一些SQL的核心技能
1.資料庫
什麼是資料庫?
對於這個問題每個人都有自己的理解資料庫(Database):就是一個儲存資料的倉庫,其本身其實是一張張表格,每張表格間又通過一定的聯絡連線在一起,就這樣組成了一個數據庫。可以這樣理解資料庫中最基本的元素為表(table),每張表都有一個主鍵(用於對錶的身份進行標識,主鍵具有唯一性),表中包含列和行,列為名稱標籤,行為記錄具體資料。在資料庫中如何關聯其他的表後面會講到選取主流的資料庫
市場上主流的資料有MySQL、Oracle、SQL Server等,而MySQL 是一個開源的關係型的資料庫管理系統,應用非常廣泛,因而選擇使用Mysql學習sql是個不錯的選擇。mysql的安裝與配置非常簡單,我們從官網下載社群版本安裝,windows使用者可以選擇安裝MSI安裝(Windows Installer),一直預設安裝,到了資料庫使用者和密碼設定時,設定即可。
選取MySQL的GUI工具
這樣的工具有很多種,每個人都有自己的喜好,我用的是HeidiSQL該工具操作簡單方便這裡不過多敘述使用方法SQL的基本操作
建立資料庫,含有一個簡單的資料表,並進行C(建立)U(更新)R(讀取,查詢)D(刪除)操作資料表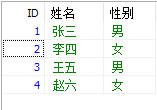
建立資料庫
CREATE DATABASE 資料庫名稱CREATE DATABASE STUDENTS開啟資料庫
USE 資料庫名稱USE STUDENTS檢視所有資料庫
#檢視所有資料庫
SHOW DATABASES
#檢視當前開啟的資料庫
SELECT DATABASE()刪除資料庫
DROP DATABASES 資料庫名稱
DROP DATABASE STUDENTS在資料庫中建立資料表,根據具體資料型別,選擇想用資料長度
CREATE TABLE tb1(
ID INT(20) NOT NULL,
姓名 varchar(20),
性別 varchar(5)
)
#檢視資料表
SHOW TABLES FROM STUDENTS
#檢視資料表結構
SHOW COLUMNS FROM STUDENTS向表中寫入記錄
INSERT 表名稱 (列1, 列2,...) VALUES (值1, 值2,....)INSERT tb1(ID, 姓名, 性別) VALUES(1,'張三', '男');
INSERT tb1(ID, 姓名, 性別) VALUES(2,'李四', '女');
INSERT tb1(ID, 姓名, 性別) VALUES(3,'王五', '男');
INSERT tb1(ID, 姓名, 性別) VALUES(4,'趙六', '女');刪除記錄的資料
DELETE FROM 表名 WHERE 列名稱 = 某值DELETE FROM tb1 WHERE 姓名 = '趙六' 更新記錄的資料
UPDATE 表名稱 SET 列名稱 = 新值 WHERE 列名稱 = 某值UPDATE persons SET 性別 = '男' WHERE 姓名 ='趙六'2.SQL重點知識
我們在進行資料分析時,最常用的功能就是查詢功能,所以首先我們要明確SQL中一些語句的執行順序select---from---where---groupby---having---orderby一、基礎知識
列出一些關鍵字
- select.....from
- where
- group by --having
- order by
- like
- distinct
- 常用函式:sum,count, max, min,avg
- case when then else end
select 列名稱 from 表名稱
select * from 表名稱 #獲取所有列WHERE 列 運算子 值需要理解篩選的條件,合理利用運算子獲取資料
group by:對指定的欄位進行分組,產生彙總資訊,一般結合sum,count函式使用。
select 欄位1,欄位2 from Table1
GROUP BY 欄位1,欄位2group by 使用中需要注意的問題
1,注意返回結果集的欄位,,這些欄位要麼要包含在Group By語句的後面,作為分組的依據;要麼就要被包含在聚合函式中
2,where 搜尋條件在進行group by 分組操作之前應用,不能使用聚合函式
3, having 搜尋條件在進行分組操作之後應用,可以使用聚合函式
order by : 根據指定的列對結果集進行排序, 預設按照升序,降序用descORDER BY 欄位1,欄位2where column_namelike patterndistinct: 去重欄位,需注意,只能放在select 語句首欄位中
SELECT DISTINCT 列名稱 FROM 表名稱sum:返回數值列的總數、 avg: 返回列的平均值、 count()返回表中的記錄數
max():返回最大值、 min():返回最小值
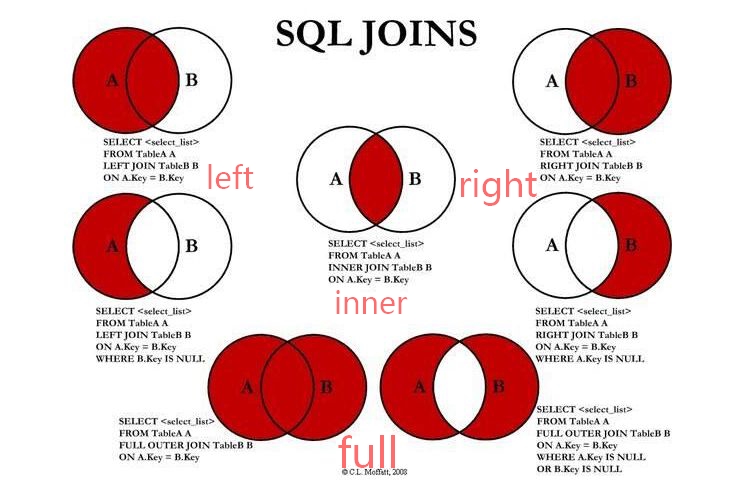
二、連線(join)查詢
- 內連線
- 外連線
內連線
等值連線:在連線條件中使用等於號(=)運算子比較被連線列的列值,其查詢結果中列出被連線表中的所有列,包括其中的重複列。不等值連線:在連線條件使用除等於運算子以外的其它比較運算子比較被連線的列的列值。這些運算子包括>、>=、<=、<、!>、!<和<>。
自然連線:在連線條件中使用等於(=)運算子比較被連線列的列值,但它使用選擇列表指出查詢結果集合中所包括的列,並刪除連線表中的重複列。
多表內連線:將多張表連線在一起,只列出匹配的記錄
FROM 表1 [INNER] JOIN 表2 ON〈聯接條件〉FROM 表1 表名1 [INNER] JOIN 表1 表名2 ON〈聯接條件〉外連線
包括,左、右連線,返回所有的行FROM 表1 LEFT JOIN 表2 ON〈連線條件〉左聯接 left join,以 join 前面一張表為主,返回其所有行,如果與右表有相同的欄位,全部返回,否則為空,右聯接剛好與之相反。
全連線 Full join, 兩張表全部返回
圖解如下
三、子查詢
說白了就是巢狀查詢,包含在某個查詢中,如果子查詢依賴於外部條件,則被稱為相關子查詢;
反之為非相關子查詢