C++程式碼實現梯度下降演算法並給出測試用例
阿新 • • 發佈:2019-02-11
此處僅給出程式碼實現,具體原理及過程請看前面的博文
測試檔案輸入格式如下:
2 10 0.01 10
2104 3 399900
1600 3 329900
2400 3 369000
1416 2 232000
3000 4 539900
1985 4 299900
1534 3 314900
1427 3 198999
1380 3 212000
1494 3 242500
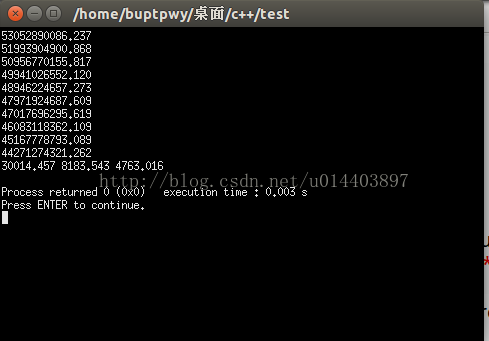
輸出如下:
53052890086.237 51993904900.868 50956770155.817 49941026552.120 48946224657.273 47971924687.609 47017696295.619 46083118362.109 45167778793.089 44271274321.262 30014.457 8183.543 4763.016
含義如下:

特徵值的歸一化方法與之前的博文不太一樣,採用了另一種歸一方式:

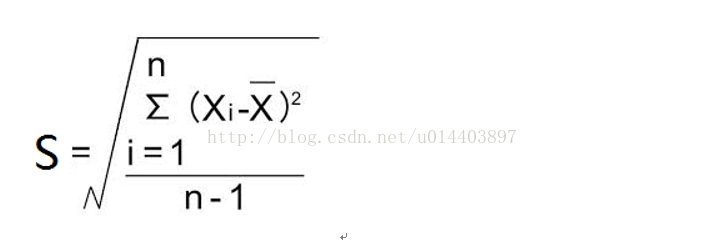
具體的實現程式碼如下:
#include <iostream> #include <stdio.h> #include <math.h> using namespace std; double predict(double* w,double* data,int feature_num){ double sum=0; for(int i=0;i<feature_num;i++){ sum+=w[i]*data[i]; } return sum; } double Theta(double **training_set,int featue_num,int training_num,double* w){ double sum=0; for(int i=0;i<training_num;i++){ sum+=(training_set[i][featue_num]-predict(w,training_set[i],featue_num))*(training_set[i][featue_num]-predict(w,training_set[i],featue_num)); } return sum/(2*training_num); } void gradient_descent(double** training_set,int feature_num,int training_num,double* w,double a,int iterator_time){ while(iterator_time--){ double* del_theta=new double[feature_num]; for(int i=0;i<feature_num;i++){ del_theta[i]=0; for(int j=0;j<training_num;j++){ del_theta[i]+=(predict(w,training_set[j],feature_num)-training_set[j][feature_num])*training_set[j][i]; } } //w[i]的更新必須等所有的del_theta測算出來了才可以!不然更新的會影響沒更新的 //上述問題在程式碼內表示即是下面的for迴圈不能和上面的合併! for(int i=0;i<feature_num;i++) w[i]-=a*del_theta[i]/(double)training_num; printf("%.3lf\n", Theta(training_set,feature_num,training_num,w)); delete[] del_theta; } for(int i=0;i<feature_num-1;i++){ printf("%.3lf ", w[i]); } printf("%.3lf\n", w[feature_num-1]); return; } void feature_normalize(double **feature_set,int feature_num,int training_num){ //特徵歸一化,此處特徵歸一化方法略有不同於梯度下降那篇的特徵歸一化方法 //問題:特徵歸一化Y的值需要歸一化麼?不需要! double *average=new double[feature_num]; double *stanrd_divition=new double[feature_num]; for(int i=1;i<feature_num;i++){ double sum=0; for(int j=0;j<training_num;j++){ sum+=feature_set[j][i]; } average[i]=sum/training_num; } for(int i=1;i<feature_num;i++){ double sum=0; for(int j=0;j<training_num;j++){ sum+=(feature_set[j][i]-average[i])*(feature_set[j][i]-average[i]); } stanrd_divition[i]=sqrt((sum/(training_num-1))); } for(int i=1;i<feature_num;i++) for(int j=0;j<training_num;j++){ feature_set[j][i]=(feature_set[j][i]-average[i])/(double)stanrd_divition[i]; } delete[] stanrd_divition; delete[] average; } int main(){ int feature_num,training_num,times; double a; //自己測試時請修改路徑 freopen("in.txt","r",stdin); while(cin>>feature_num>>training_num>>a>>times){ double **featurn_set=new double*[training_num]; //int *arr=new int[10] 意味著聲明瞭一個數組,大小為10,型別為int for(int i=0;i<training_num;i++){ featurn_set[i]=new double[feature_num+2]; } for(int i=0;i<training_num;i++) featurn_set[i][0]=1; for(int i=0;i<training_num;i++){ for(int j=1;j<=feature_num+1;j++){ cin>>featurn_set[i][j]; } } //在特徵標準化的時候w0完全一樣,就直接賦值為一,不要進行標準化了,不然會出錯 feature_normalize(featurn_set,feature_num+1,training_num); for(int i=0;i<training_num;i++) featurn_set[i][0]=1; double* w=new double[feature_num+1]; for(int i=0;i<=feature_num;i++) w[i]=0; gradient_descent(featurn_set,feature_num+1,training_num,w,a,times); for(int i=0;i<training_num;i++) delete[] featurn_set[i]; delete[] featurn_set; delete[] w; //一般情況,需要將w=NULL,原因是為了防止w再次呼叫delete刪除了不該刪除的東西 } return 0; }
執行結果如下: