
SVM-支援向量機原理詳解與實踐之一
SVM-支援向量機原理詳解與實踐
-
前言
去年由於工作專案的需要實際運用到了SVM和ANN演算法,也就是支援向量機和人工神經網路演算法,主要是實現專案中的實時採集圖片(工業高速攝像頭採集)的影象識別的這一部分功能,雖然幾經波折,但是還好最終還算順利完成了專案的任務,忙碌一年,趁著放假有時間好好整理並總結一下,本文的內容包括:前面的部分是對支援向量機原理的分析,後半部分主要直接上手的一些實踐的內容。
本文的原理部分針對支援向量機的原理,特別拉格朗日對偶性,求解拉個拉格朗日函式,以及和函式與核技巧再到軟間隔和正則化等重要內容做了一些討論。
實踐部分的目標則是通過對實踐時碰到的問題,調參的過程的講解可以對前半部分講解的SVM原理部分的內容有一個更深入的瞭解。
-
SVM、機器學習與深度學習
-
人工智慧領域
-
在大資料,人工智慧的時代,深度學習可以說火得一塌糊塗。美國矽谷的大公司都在佈局著這個領域,而中國國內,騰訊,百度,阿里巴巴等等知名企業也都在這個領域爭先發力,2017年初,百度迎來陸奇-前微軟全球執行副總裁,人工智慧領域世界級的權威,要知道百度還有人工智慧大牛Andrew Ng – 吳恩達。所有跡象表明人工智慧必然是繼網際網路之後的全球各大公司甚至國家必爭的高地。
-
機器學習與深度學習
由於深度學習在大資料預測能力上的卓越表現,當下出現了深度學習是否會替代傳統機器學習演算法並淘汰他們的討論,但是另一方面,大多數人仍然相信深度學習不會代替其他的模型或者演算法。對於大多數的應用,像一些簡單的演算法如邏輯迴歸、支援向量機表現的已經很不錯了,使用深度學習會讓問題複雜化。
深度學習是可以應用到大部分領域的,但是就像前面說的,深度學習並非所有問題的最優方案,如果你的工作中有用到機器學習演算法,你可以嘗試傳統的機器學習演算法,也可以達到很好的效果。雖然現在已經有一些工作去把各領域的知識融入到深度學習中的,但這並不能完全替代原有的。
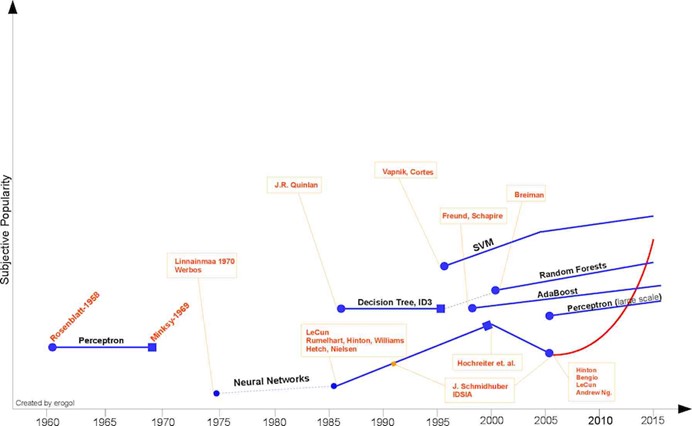
上圖是一個關於機器學習演算法的時間線來自於Eren Golge。
就像在20世紀早期SVM一樣,深度學習會成為主流,但首先深度學習應當解決其在大資料需求及複雜性方面的問題,這樣它才會成為人們的第一選擇。
-
SVM簡介
SVM(support vector machine)簡單的說是一個分類器,並且是二類分類器。
- Vector:通俗說就是點,或是資料。
- Machine:也就是classifier,也就是分類器。
SVM作為傳統機器學習的一個非常重要的分類演算法,它是一種通用的前饋網路型別,最早是由Vladimir N.Vapnik 和 Alexey Ya.Chervonenkis在1963年提出,目前的版本(soft margin)是Corinna Cortes 和 Vapnik在1993年提出,1995年發表。深度學習(2012)出現之前,SVM被認為是機器學習中近十幾年最成功表現最好的演算法。
-
SVM原理分析
-
快速理解SVM原理
-
很多講解SVM的書籍都是從原理開始講解,如果沒有相關知識的鋪墊,理解起來還是比較吃力的,以下的一個例子可以讓我們對SVM快速建立一個認知。
給定訓練樣本,支援向量機建立一個超平面作為決策曲面,使得正例和反例的隔離邊界最大化。
決策曲面的初步理解可以參考如下過程,
- 如下圖想象紅色和藍色的球為球檯上的桌球,我們首先目的是找到一條曲線將藍色和紅色的球分開,於是我們得到一條黑色的曲線。
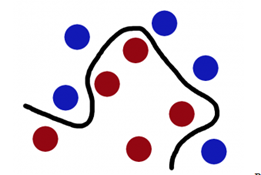
圖一.
2) 為了使黑色的曲線離任意的藍球和紅球距離(也就是我們後面要提到的margin)最大化,我們需要找到一條最優的曲線。如下圖,
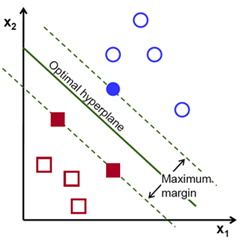
圖二.
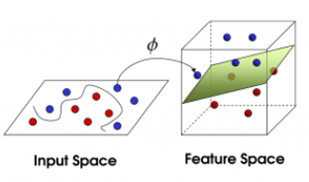
3) 想象一下如果這些球不是在球桌上,而是被拋向了空中,我們仍然需要將紅色球和藍色球分開,這時就需要一個曲面,而且我們需要這個曲面仍然滿足跟所有任意紅球和藍球的間距的最大化。需要找到的這個曲面,就是我們後面詳細瞭解的最優超平面。
4) 離這個曲面最近的紅色球和藍色球就是Support Vector。
-
線性可分和線性不可分
線性可分-linearly separable, 在二維空間可以理解為可以用一條直線(一個函式)把兩型別的樣本隔開,被隔離開來的兩類樣本即為線性可分樣本。同理在高維空間,可以理解為可以被一個曲面(高維函式)隔開的兩類樣本。
線性不可分,則可以理解為自變數和因變數之間的關係不是線性的。
實際上,線性可不分的情況更多,但是即使是非線性的樣本通常也是通過高斯核函式將其對映到高維空間,在高維空間非線性的問題轉化為線性可分的問題。
-
函式間隔和幾何間隔
-
函式間隔functional margin:給定一個訓練樣本
有:
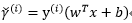
函式間隔代表了特徵是正例或是反例的確信度。
-
幾何間隔 geometrical margin:
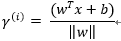
向量點到超平面的距離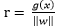
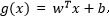
-
超平面分析與幾何間隔詳解
前面已經對SVM的原理有了一個大概的瞭解,並且簡單介紹了函式間隔和幾何間隔的概念,為了更好的理解線性可分模式下超平面,以下將進行深入的剖析推導過程,我們假設有訓練樣本集,期望的響應為,這裡我們用類+1和類-1來代表,以表明樣本是線性可分的。
決策曲面方程如下:
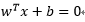
其中
x:輸入向量,也就是樣本集合中的向量;
w:是可調權值向量,每個向量可調權值;
T:轉置,向量的轉置;
b:偏置,超平面相對原點的偏移。
根據邏輯迴歸定義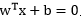
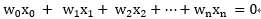
其中假設約定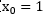
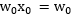
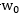
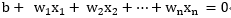
而
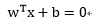
這裡假設模式線性可分:
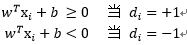
線性可分模式下最優超平面的示意圖如下:
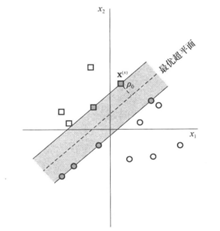
如上圖所示:
為分離邊緣,即超平面和最近資料點的間隔。如果一個平面能使
最大,則為最優超平面。
- 灰色的方形點和原形點就是我們所說的支援向量。
假設和向量和偏置的最優解,則最優超平面的函式為:
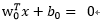
相應的判別函式是:
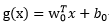
以下是點x到最優超平面的二維示意圖:
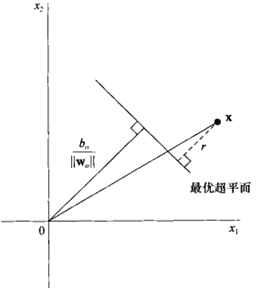
由上圖可知r 為點x到最優超平面的距離:
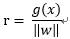
那麼代數距離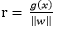
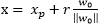
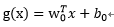
可以得到r,其中:
為x在最優超平面的正軸投影,
因為
在平面上
下面給出一種更為簡單且直觀的理解:
首先我們必須要知道Euclidean norm範數,即歐幾里德範數(以下用w表示多維的向量):
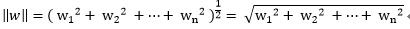
再參考點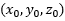
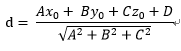
也就是
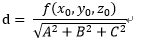
類似的,擴充套件到多維的w向量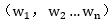
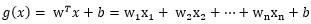
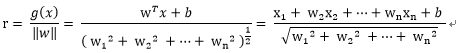
對比點平面的公式,以上的r也就多維度空間向量的到最優超平面的距離。
再看上圖,如果x = 0 即原點則有
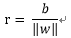
那麼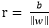
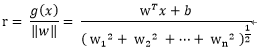
因為x = 0,它在原點,它與任意可調權值向量w相乘都等於0,於是有:
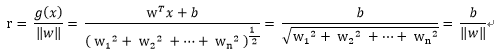
注意b為偏置,只是決定了決策曲面相對原點的偏離,結合上圖我們可知道:
- b > 0 則原點在最優超平面的正面;
- b < 0 則原點在最優超平面的負面;
- b = 0 則原點就在最優超平面上。
找到的這個最優超平面的引數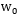
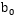
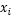
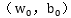
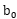
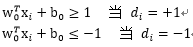
滿足上式的點就是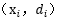
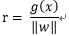
在超平面的正面和負面我們有任一支援向量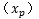
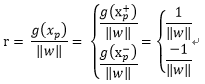
如果讓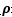
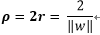
所以我們可以看出,如果要使得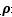
-
二次最優化
回頭看我們前面提到的,給定一個訓練集,我們的需求就是嘗試找到一個決策邊界使得幾何間隔最大,迴歸到問題的本質那就是我們如何找到這個最大的幾何間隔? 要想要最大化間隔(margin),正如上面提到的:
最大化兩個類之間的分離邊緣等價於最小化權值向量w的歐幾里得範數。
即:
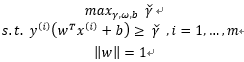
其中: 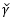
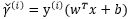
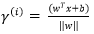
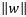
或是將優化的問題轉化為以下式子:
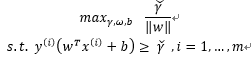
其中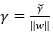
我們發現以上兩個式子都可以表示最大化間隔的優化問題,但是我們同時也發現無論上面哪個式子都是非凸的,並沒有現成的可用的軟體來解決這兩種形式的優化問題。
於是一個行之有效的優化問題的形式被提出來,注意它是一個凸函式形式,如下:
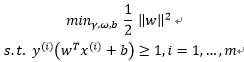
以上的優化問題包含了一個凸二次優化物件並且線性可分,概括來說就是需找最優超平面的二次最優化,這個優化的問題可以用商業的凸二次規劃程式碼來解。
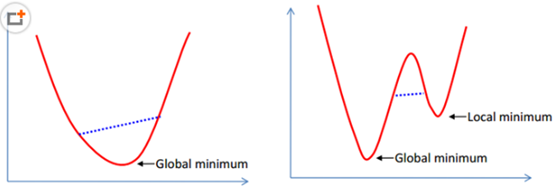
凸函式:
在凸集中任取兩個點連成一條直線,這條直線上的點仍然在這個集合內部,左邊
凸函式區域性最優就是全域性最優,而右邊的非凸函式的區域性最優就不是全域性最優了。
下面要具體介紹的拉格朗日對偶性,它可以引導我們到優化問題的對偶形式,因為對偶形式在高維空間有效的運用核(函式)來得到最優間隔分類器的方法中扮演了非常重要的角色。對偶形式讓我們得到一個有效的演算法來解決上述的優化問題並且相較通用的二次規劃商業軟體更好。
優化問題的對偶形式的方法簡單來說就是通過Lagrange Duality變換到對偶變數 (dual variable)的優化問題之後,應用拉格朗日對偶性,通過求解對偶問題得到最優解,這就是線性可分條件下支援向量機的對偶演算法,這樣做的優點在於:
- 一是原問題的對偶問題往往更容易求解
- 二者可以自然的引入核函式,進而推廣到非線性分類問題。
接下篇SVM-支援向量機原理詳解與實踐之二