
貝葉斯公式的理解
最近我自己在學習一些關於機器學習的東西,目前學到了貝葉斯統計這一塊,我覺得很感興趣,於是便找了一些資料看了看,在自己琢磨一段時間後,寫了一篇部落格,原文地址:機器學習(一) —— 淺談貝葉斯和MCMC。正好題主也說了希望從哲學角度解釋一下,我自認為文章寫得還算深入淺出,能給大家帶來幫助。
為了有打廣告之嫌疑,我還是內文章內主要的內容在這裡重新編輯一遍,省去全文中MCMC和sklearn的部分,有興趣的可以自行前往。
淺談貝葉斯
不論是學習概率統計還是機器學習的過程中,貝葉斯總是是繞不過去的一道坎,大部分人在學習的時候都是在強行地背公式和套用方法,沒有真正去理解其牛逼的思想內涵。我看了一下自己學校裡一些涉及到貝葉斯統計的課程,content裡的第一條都是 Philosophy of Bayesian statistics
歷史背景
什麼事都要從頭說起,貝葉斯全名為托馬斯·貝葉斯(Thomas Bayes,1701-1761),是一位與牛頓同時代的牧師,是一位業餘數學家,平時就思考些有關上帝的事情,當然,統計學家都認為概率這個東西就是上帝在擲骰子。當時貝葉斯發現了古典統計學當中的一些缺點,從而提出了自己的“貝葉斯統計學”,但貝葉斯統計當中由於引入了一個主觀因素(先驗概率,下文會介紹),一點都不被當時的人認可。直到20世紀中期,也就是快200年後了,統計學家在古典統計學中遇到了瓶頸,伴隨著計算機技術的發展,當統計學家使用貝葉斯統計理論時發現能解決很多之前不能解決的問題,從而貝葉斯統計學一下子火了起來,兩個統計學派從此爭論不休。
什麼是概率?
什麼是概率這個問題似乎人人都覺得自己知道,卻有很難說明白。比如說我問你 擲一枚硬幣為正面的概率為多少?,大部分人第一反應就是50%的機率為正。不好意思,首先這個答案就不正確,只有當材質均勻時硬幣為正面的機率才是50%(所以不要覺得打麻將的時候那個骰子每面的機率是相等的,萬一被做了手腳呢)。好,那現在假設硬幣的材質是均勻的,那麼為什麼正面的機率就是50%呢?有人會說是因為我擲了1000次硬幣,大概有492次是正面,508次是反面,所以近似認為是50%,說得很好(擲了1000次我也是服你)。
擲硬幣的例子說明了古典統計學的思想,就是概率是基於大量實驗的,也就是 大數定理。那麼現在再問你,有些事件,例如:明天下雨的概率是30%;A地會發生地震的概率是5%;一個人得心臟病的概率是40%……
舉個例子:生病的機率
一種癌症,得了這個癌症的人被檢測出為陽性的機率為90%,未得這種癌症的人被檢測出陰性的機率為90%,而人群中得這種癌症的機率為1%,一個人被檢測出陽性,問這個人得癌症的機率為多少?
猛地一看,被檢查出陽性,而且得癌症的話陽性的概率是90%,那想必這個人應該是難以倖免了。那我們接下來就算算看。
我們用 表示事件 “測出為陽性”, 用
表示“得癌症”,
表示“未得癌症”。根據題目,我們知道如下資訊:
那麼我們現在想得到人群中檢測為陽性且得癌症的機率 :
這裡 表示的是聯合概率,得癌症且檢測出陽性的概率是人群中得癌症的概率乘上得癌症時測出是陽性的機率,是0.009。同理可得未得癌症且檢測出陽性的概率:
這個概率是什麼意思呢?其實是指如果人群中有1000個人,檢測出陽性並且得癌症的人有9個,檢測出陽性但未得癌症的人有99個。可以看出,檢測出陽性並不可怕,不得癌症的是絕大多數的,這跟我們一開始的直覺判斷是不同的!可直到現在,我們並沒有得到所謂的“在檢測出陽性的前提下得癌症的 概率 ”,怎麼得到呢?很簡單,就是看被測出為陽性的這108(9+99)人裡,9人和99人分別佔的比例就是我們要的,也就是說我們只需要新增一個歸一化因子(normalization)就可以了。所以陽性得癌症的概率 為:
, 陽性未得癌症的概率
為:
。 這裡
,
中間多了這一豎線
成為了條件概率,而這個概率就是貝葉斯統計中的 後驗概率!而人群中患癌症與否的概率
就是 先驗概率!我們知道了先驗概率,根據觀測值(observation),也可稱為test evidence:是否為陽性,來判斷得癌症的後驗概率,這就是基本的貝葉斯思想,我們現在就能得出本題的後驗概率的公式為:
由此就能得到如下的貝葉斯公式的一般形式。
貝葉斯公式
我們把上面例題中的 變成樣本(sample)
, 把
變成引數(parameter)
, 我們便得到我們的貝葉斯公式:
可以看出上面這個例子中, 事件的分佈是離散的,所以在分母用的是求和符號
。那如果我們的引數
的分佈是連續的呢?沒錯,那就要用積分,於是我們終於得到了真正的 貝葉斯公式 :
其中指的是引數的概率分佈,
指的是先驗概率,
指的是後驗概率,
指的是我們觀測到的樣本的分佈,也就是似然函式(likelihood),記住 豎線
左邊的才是我們需要的。其中積分求的區間
指的是引數
所有可能取到的值的域,所以可以看出後驗概率
是在知道
的前提下在
域內的一個關於
的概率密度分佈,每一個
都有一個對應的可能性(也就是概率)。
理解貝葉斯公式
這個公式應該在概率論書中就有提到,反正當時我也只是死記硬背住,然後遇到題目就套用。甚至在國外讀書時學了一門統計推斷的課講了貝葉斯,大部分時間我還是在套用公式,直到後來結合了一些專門講解貝葉斯的課程和資料才有了一些真正的理解。要想理解這個公式,首先要知道這個豎線 的兩側一會是
,一會是
到底指的是什麼,或者說似然函式和引數概率分佈到底指的是什麼。
似然函式
首先來看似然函式 ,似然函式聽起來很陌生,其實就是我們在概率論當中看到的各種概率分佈
,那為什麼後面要加個引數
呢?我們知道,擲硬幣這個事件是服從伯努利分佈的
,
次的伯努利實驗就是我們熟知的二項分佈
, 這裡的
就是一個引數,原來我們在做實驗之前,這個引數就已經存在了(可以理解為上帝已經定好了),我們抽樣出很多的樣本
是為了找出這個引數,我們上面所說的擲硬幣的例子,由於我們擲了1000次有492次是正面,根據求期望的公式
(492就是我們的期望)可以得出引數
為
,所以我們才認為正面的概率是近似50%的。
現在我們知道了,其實我們觀測到樣本的分佈是在以某個引數
為前提下得出來的,所以我們記為
,只是我們並不知道這個引數是多少。所以 引數估計 成為了統計學裡很大的一個課題,古典統計學中常用的方法有兩種:矩方法(momnet) 和 最大似然估計(maximum likelihood estimate, mle) ,我們常用的像上面擲硬幣例子中求均值的方法,本質就是矩估計方法,這是基於大數定理的。而統計學中更廣泛的是使用最大似然估計的方法,原理其實很簡單,在這簡單說一下:假設我們有
個樣本
, 它們每一個變數都對應一個似然函式:
我們現在把這些似然函式乘起來:
我們只要找到令這個函式最大的
值,便是我們想要的引數值(具體計算參考[2]中p184)。
後驗分佈(Posterior distribution)
現在到了貝葉斯的時間了。以前我們想知道一個引數,要通過大量的觀測值才能得出,而且是隻能得出一個引數值。而現在運用了貝葉斯統計思想,這個後驗概率分佈其實是一系列引數值
的概率分佈,再說簡單點就是我們得到了許多個引數
及其對應的可能性,我們只需要從中選取我們想要的值就可以了:有時我們想要概率最大的那個引數,那這就是 後驗眾數估計(posterior mode estimator);有時我們想知道引數分佈的中位數,那這就是 後驗中位數估計(posterior median estimator);有時我們想知道的是這個引數分佈的均值,那就是 後驗期望估計。這三種估計沒有誰好誰壞,只是提供了三種方法得出引數,看需要來選擇。現在這樣看來得到的引數是不是更具有說服力?
置信區間和可信區間
在這裡我想提一下 置信區間(confidence interval, CI) 和 可信區間(credibility interval,CI),我覺得這是剛學貝葉斯時候非常容易弄混的概念。
再舉個例子:一個班級男生的身高可能服從某種正態分佈 ,然後我們把全班男生的身高給記錄下來,用高中就學過的求均值和方差的公式就可以算出來這兩個引數,要知道我們真正想知道的是這個引數
,當然樣本越多,得出的結果就接近真實值(其實並沒有人知道什麼是真實值,可能只有上帝知道)。等我們算出了均值和方差,我們這時候一般會構建一個95%或者90%的置信區間,這個置信區間是對於 樣本
來說的,我只算出了一個
和 一個
引數值的情況下,95%的置信區間意味著在這個區間裡的樣本是可以相信是服從以
為引數的正態分佈的,一定要記住置信區間的概念中是指 一個引數值 的情況下!
而我們也會對我們得到的後驗概率分佈構造一個90%或95%的區間,稱之為可信區間。這個可信區間是對於 引數來說的,我們的到了 很多的引數值,取其中概率更大一些的90%或95%,便成了可信區間。
先驗分佈(Prior distribution)
說完了後驗分佈,現在就來說說先驗分佈。先驗分佈就是你在取得實驗觀測值以前對一個引數概率分佈的 主觀判斷,這也就是為什麼貝葉斯統計學一直不被認可的原因,統計學或者數學都是客觀的,怎麼能加入主觀因素呢?但事實證明這樣的效果會非常好!
再拿擲硬幣的例子來看(怎麼老是拿這個舉例,是有多愛錢。。。),在扔之前你會有判斷正面的概率是50%,這就是所謂的先驗概率,但如果是在打賭,為了讓自己的描述準確點,我們可能會說正面的概率為0.5的可能性最大,0.45的機率小點,0.4的機率再小點,0.1的機率幾乎沒有等等,這就形成了一個先驗概率分佈。
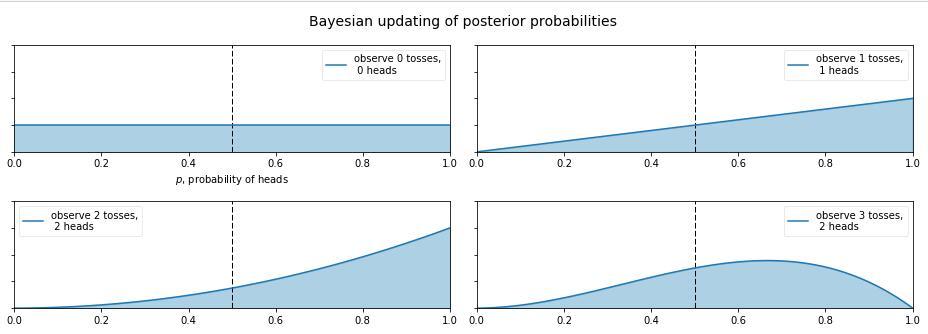
那麼現在又有新的問題了,如果我告訴你這個硬幣的材質是不均勻的,那正面的可能性是多少呢?這就讓人犯糊塗了,我們想有主觀判斷也無從下手,於是我們就想說那就先認為0~1之間每一種的可能性都是相同的吧,也就是設定成0~1之間的均勻分佈 作為先驗分佈吧,這就是貝葉斯統計學當中的 無資訊先驗(noninformative prior)!那麼下面我們就通過不斷擲硬幣來看看,這個概率到是多少,貝葉斯過程如下: (圖來自[3])
 <img src="https://pic2.zhimg.com/50/v2-0fc8c439d5a4eebf0ca11b46d1b5135d_hd.jpg" data-caption="" data-size="normal" data-rawwidth="937" data-rawheight="318" class="origin_image zh-lightbox-thumb" width="937" data-original="https://pic2.zhimg.com/v2-0fc8c439d5a4eebf0ca11b46d1b5135d_r.jpg">
<img src="https://pic2.zhimg.com/50/v2-0fc8c439d5a4eebf0ca11b46d1b5135d_hd.jpg" data-caption="" data-size="normal" data-rawwidth="937" data-rawheight="318" class="origin_image zh-lightbox-thumb" width="937" data-original="https://pic2.zhimg.com/v2-0fc8c439d5a4eebf0ca11b46d1b5135d_r.jpg">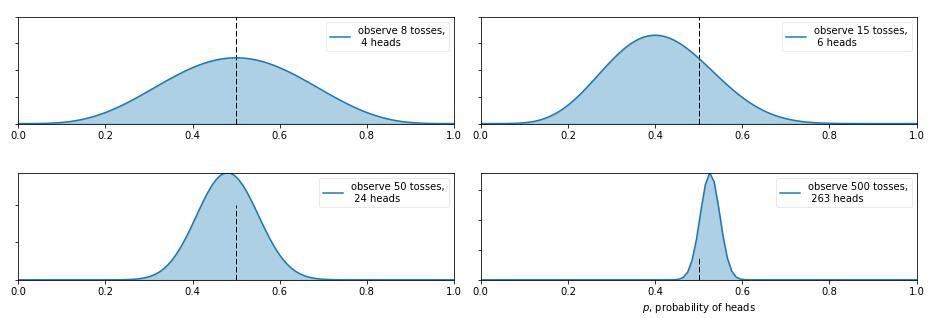
從圖中我們可以看出,0次試驗的時候就是我們的先驗假設——均勻分佈,然後擲了第一次是正面,於是概率分佈傾向於1,第二次又是正,概率是1的可能性更大了,但 注意:這時候在0.5的概率還是有的,只不過概率很小,在0.2的概率變得更小。第三次是反面,於是概率分佈被修正了一下,從為1的概率最大變成了2/3左右最大(3次試驗,2次正1次反當然概率是2/3的概率最大)。再下面就是進行更多次的試驗,後驗概率不斷根據觀測值在改變,當次數很大的時候,結果趨向於0.5(哈哈,結果這還是一枚普通的硬幣,不過這個事件告訴我們,直覺是不可靠的,一定親自實驗才行~)。有的人會說,這還不是在大量資料下得到了正面概率為0.5嘛,有什麼好稀奇的? 注意了!畫重點了!(敲黑板) 記住,不要和一個統計學家或者數學家打賭!跑題了,跑題了。。。說回來,我們上面就說到了古典概率學的弊端就是如果擲了2次都是正面,那我們就會認為正面的概率是1,而在貝葉斯統計學中,如果我們擲了2次都是正面,只能說明正面是1的可能性最大,但還是有可能為0.5, 0.6, 0.7等等的,這就是對古典統計學的一種完善和補充,於是我們也就是解釋了,我們所謂的 地震的概率為5%;生病的概率為10%等等這些概率的意義了,這就是貝葉斯統計學的哲學思想。
共軛先驗(Conjugate prior)
共軛先驗應該是每一個貝葉斯統計初學者最頭疼的問題,我覺得沒有“之一”。這是一個非常大的理論體系,我試著用一些簡單的語言進行描述,關鍵是去理解其思想。
繼續拿擲硬幣的例子,這是一個二項試驗 ,所以其似然函式為:
在我們不知道情況時就先假設其先驗分佈為均勻分佈 ,即:
那現在根據貝葉斯公式求後驗概率分佈:
我們得到結果為:
這麼一大串是什麼呢?其實就是大名鼎鼎的貝塔分佈(Beta distribution)。 簡寫就是 。 比如我擲了10次(n=10),5次正(x=5),5次反,那麼結果就是
, 這個分佈的均值就是0.5(
),很符合我們想要的結果。
現在可以說明,我們把主觀揣測的先驗概率定為均勻分佈是合理的,因為我們在對一件事物沒有了解的時候,先認為每種可能性都一樣是非常說得通的。有人會認為,既然無資訊先驗是說得通的,而且貝葉斯公式會根據我們的觀測值不斷更新後驗概率,那是不是我們隨便給一個先驗概率都可以呢?當然......不行!!這個先驗概率是不能瞎猜的,是需要根據一些前人的經驗和常識來判斷的。比如我隨便猜先驗為一個分段函式:
靠,是不是很變態的一個函式...就是假設一個極端的情況,如果你把這個情況代入貝葉斯公式,結果是不會好的(當然我也不知道該怎麼計算)。
這個例子中,我看到了可能的後驗分佈是 分佈,看起來感覺有點像正態分佈啊,那我們用正態分佈作為先驗分佈可以嗎?這個是可以的(所以要學會觀察)。可如果我們把先驗分佈為正態分佈代入到貝葉斯公式,那計算會非常非常麻煩,雖然結果可能是合理的。那怎麼辦?不用擔心,因為我們有共軛先驗分佈!
繼續拿上面這個例子,如果我們把先驗分佈 設為貝塔分佈
,結果是什麼呢?我就不寫具體的計算過程啦,直接給結果:
有沒有看到,依然是貝塔分佈,結果只是把之前的1換成了 (聰明的你可能已經發現,其實我們所說的均勻分佈
等價於
,兩者是一樣的)。
由此我們便可以稱 二項分佈的共軛先驗分佈為貝塔分佈!注意!接著畫重點!:共軛先驗這個概念必須是基於似然函式來討論的,否則沒有意義! 好,那現在有了共軛先驗,然後呢?作用呢?這應該是很多初學者的疑問。
現在我們來看,如果你知道了一個觀測樣本的似然函式是二項分佈的,那我們把先驗分佈直接設為 ,於是我們就 不用計算複雜的含有積分的貝葉斯公式 便可得到後驗分佈
了!!!只需要記住試驗次數
,和試驗成功事件次數
就可以了!互為共軛的分佈還有一些,但都很複雜,用到的情況也很少,推導過程也極其複雜,有興趣的可以自行搜尋。我說的這個情況是最常見的!
注意一下,很多資料裡會提到一個概念叫偽計數(pseudo count),這裡的偽計數值得就是a,b對後驗概率分佈的影響,我們會發現如果我們取,這個先驗概率對結果的影響會很小,可如果我們設為
,那麼我們做10次試驗就算是全是正面的,後驗分佈都沒什麼變化。
參考書籍
[1]韋來生,《貝葉斯統計》,高等教育出版社,2016
[2]John A.Rice, 《數理統計與資料分析》(原書第三版), 機械工業出版社, 2016
[3]Cameron Davidson-Pilon, Probabilistic Programming and Bayesian Methods for Hackers(https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers), 2016
宣告:
本篇內容結合了我在報的Python機器學習課程以及Udacity裡ud-120:機器學習入門課程的講解,讓我對貝葉斯有了一個新的理解和認識,表示感謝。
這篇文章主要介紹了貝葉斯統計的數學思想,希望能對大家有所幫助,如果有任何錯誤和解釋不當的地方,請給我評論,我也只是個初學者,也希望能得到大神的指點。
( 本文僅限於非商業性轉載,且註明出處)