
Spark叢集安裝
Spark的版本1.6.0,Scala的版本2.12,jdk版本1.8。最近使用spark,在這裡記錄下。
一個master和三個worker,同時Hadoop-2.7.7叢集,namdenode在master上,倆個datanode在worker1和worker2上。
List-1
192.168.33.30 worker1 master
192.168.33.31 worker2
192.168.33.32 worker3修改master機器的hostname為master,修改worker2機器的hostname為node1,修改worker2機器的hostname為node2。
將spark放置於/opt下,如下List-2所示,三臺機器上的都一樣:
List-2
[root@master opt]# ll total 20 drwxr-xr-x 2 root root 22 4月 13 13:51 applog drwxr-xr-x 11 root root 4096 4月 11 16:31 hadoop-2.7.7 drwxr-xr-x 8 root root 4096 4月 11 14:52 jdk1.8 drwxr-xr-x 6 root root 46 4月 13 13:35 scala2.12 drwxr-xr-x 14 root root 4096 4月 13 13:27 spark-1.6.0-bin-hadoop2.6
master到倆個node的ssh面密就可以了,即在master上ssh node1/node2都可以面密碼。
/etc/profile如下List-3,在master這樣就可以了。
List-3
#spark
export SPARK_HOME=/opt/spark-1.6.0-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
最重要的是spark的conf下的配置檔案,在master上,如下描述:
1、spark-env.sh
cp spark-env.sh.template spark-env.sh,之後修改spark-env.sh的內容,如下,之後用這個檔案替換node1和node2的spark-env.sh。
List-4
export JAVA_HOME=/opt/jdk1.8
export HADOOP_HOME=/opt/hadoop-2.7.7
export SCALA_HOME=/opt/scala2.12
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKDER_CORES=4
export SPARK_WORKER_MEMORY=1024m
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.7/bin/hadoop classpath);
2、spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf,之後修改spark-defaults.conf,如下List-5。此外要手動在hdfs中建/opt/applogs/spark-eventlog目錄,用於儲存spark的event日誌。之後用這個檔案替換node1和node2的spark-defaults.conf。
List-5
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/opt/applogs/spark-eventlog3、log4j.properties
cp log4j.properties.template log4j.properties,修改log4j.properties,內容如下List-6。最後用這個檔案替換node1和node2的此檔案。
- log4j.rootCategory的值最後加上", FILE"。
- 加入List-7中的內容,最終結果是List-6所示。
List-6
log4j.rootCategory=INFO, console,FILE
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
log4j.appender.FILE=org.apache.log4j.DailyRollingFileAppender
log4j.appender.FILE.Threshold=INFO
log4j.appender.FILE.file=/opt/applog/spark.log
log4j.appender.logFile.Encoding = UTF-8
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=[%-5p] [%d{yyyy-MM-dd HH:mm:ss}] [%C{1}:%M:%L] %m%n
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
List-7 通過實際實踐發現/opt/applog/spark.log這個目錄最終在宿主機上,而非在hdfs上
log4j.appender.FILE=org.apache.log4j.DailyRollingFileAppender
log4j.appender.FILE.Threshold=INFO
log4j.appender.FILE.file=/opt/applog/spark.log
log4j.appender.logFile.Encoding = UTF-8
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.ConversionPattern=[%-5p] [%d{yyyy-MM-dd HH:mm:ss}] [%C{1}:%M:%L] %m%n
4、slaves
cp slaves.template slaves,修改slaves檔案,如下List-8。最後用這個檔案替換node1和node2上的此檔案。
List-8 這個檔案裡面的host上,都會啟動spark worker
master
node1
node2
在master上執行List-9中的start-all.sh,之後在master上用jps命令檢視會看到有個master和worker,在node1/node2上用jps命令可以看到worker。
List-9
[root@node1 spark-1.6.0-bin-hadoop2.6]# pwd
/opt/spark-1.6.0-bin-hadoop2.6
[root@node1 spark-1.6.0-bin-hadoop2.6]# sbin/start-all.sh 在瀏覽器中輸入http://192.168.33.30:8080/,看到如下
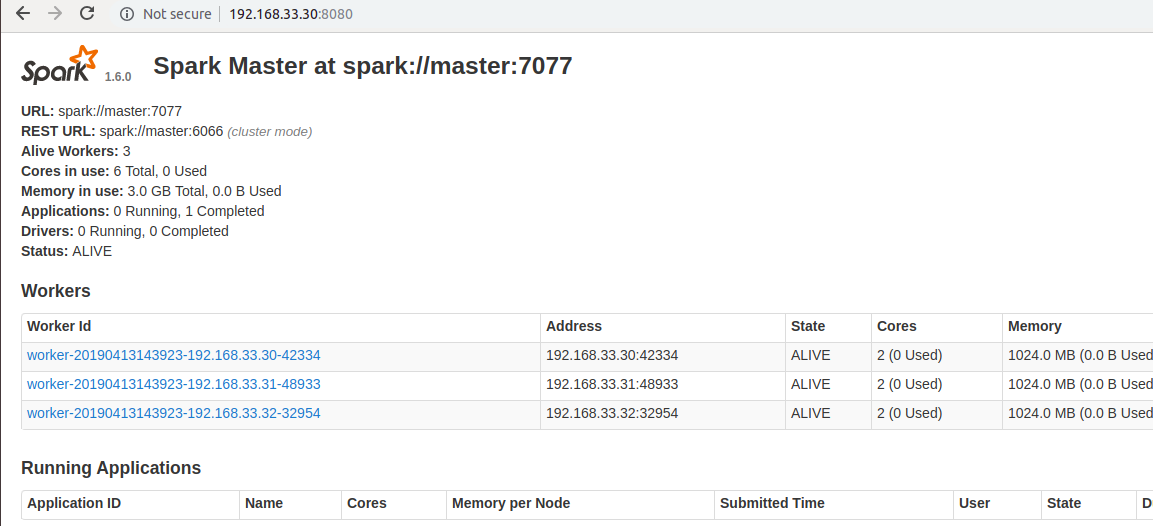
圖1
Reference:
- https://www.jianshu.com/p