
從頭學pytorch(十八):GoogLeNet
GoogLeNet
GoogLeNet和vgg分別是2014的ImageNet挑戰賽的冠亞軍.GoogLeNet則做了更加大膽的網路結構嘗試,雖然深度只有22層,但大小卻比AlexNet和VGG小很多,GoogleNet引數為500萬個,AlexNet引數個數是GoogleNet的12倍,VGGNet引數又是AlexNet的3倍,因此在記憶體或計算資源有限時,GoogleNet是比較好的選擇;從模型結果來看,GoogLeNet的效能卻更加優越。
之前轉過一篇文章,詳細描述了GoogLeNet的演化,有興趣的可以去看看:https://www.cnblogs.com/sdu20112013/p/11308388.html
基本結構Inception
GoogleNet的基礎結構叫Inception.如下所示:
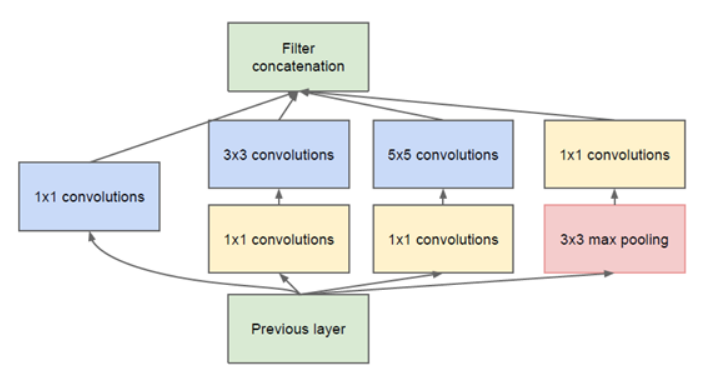
這個結構的好處主要是:
- 增加了網路寬度(增加了每一層的神卷積核的數量),提高了模型學習的能力.
- 使用了不同大小的卷積核,增加了對不同模式的特徵的提取能力.也增強了模型對不同尺度的適應性.
Inception中3x3和5x5之前的1x1主要用於降低channel維度數量,減少計算量.
這個結構中的每一個通路的卷積核的數量是超引數,可調的.
那麼,我們定義inception結構
class Inception(nn.Module): def __init__(self,in_c,c1,c2,c3,c4): super(Inception, self).__init__() self.branch1 = nn.Conv2d(in_c,c1,kernel_size=1) self.branch2_1 = nn.Conv2d(in_c,c2[0],kernel_size=1) self.branch2_2 = nn.Conv2d(c2[0],c2[1],kernel_size=3,padding=1) self.branch3_1 = nn.Conv2d(in_c,c3[0],kernel_size=1) self.branch3_2 = nn.Conv2d(c3[0],c3[1],kernel_size=5,padding=2) self.branch4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) self.branch4_2 = nn.Conv2d(in_c,c4,kernel_size=1) def forward(self,x): o1 = self.branch1(x) o1 = F.relu(o1) print("o1:",o1.shape) o2 = self.branch2_1(x) o2 = F.relu(o2) o2 = self.branch2_2(o2) o2 = F.relu(o2) print("o2:",o2.shape) o3 = self.branch3_1(x) o3 = F.relu(o3) o3 = self.branch3_2(o3) o3 = F.relu(o3) print("o3:",o3.shape) o4 = self.branch4_1(x) o4 = self.branch4_2(o4) o4 = F.relu(o4) print("o4:",o4.shape) concat = torch.cat((o1,o2,o3,o4),dim=1) print("concat:",concat.shape) return concat
如前所示,inception分為4個分支.每個分支的卷積核的數量是可調的引數.
GoogLeNet完整結構
我們根據論文裡的結構來實現GoogleNet.
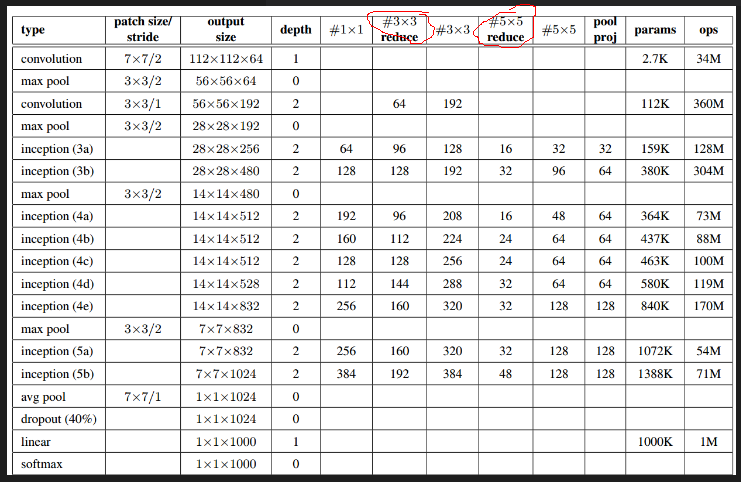
上圖裡的紅圈處代表的即3x3或5x5卷積之前的用於降維的1x1卷積.
第一層是普通卷積,64組卷積核,卷積核大小7x7,stride=2.池化層視窗大小為3x3,stride=2.
第二層是先做1x1卷積,再做3x3卷積.
可寫出以下程式碼:
X = torch.randn((1,1,224,224)) conv1 = nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3) max_pool1 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) o=conv1(X) print(o.shape) #[1,64,112,112] o=max_pool1(o) print(o.shape) #[1,64,56,56] conv2_1 = nn.Conv2d(64,64,kernel_size=1) conv2_2 = nn.Conv2d(64,192,kernel_size=3,stride=1,padding=1) max_pool2 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) o=conv2_1(o) print(o.shape) #[1,64,56,56] o=conv2_2(o) print(o.shape) #[1,192,56,56] o=max_pool2(o) print(o.shape) #[1,192,28,28]
接下來是第一個inception結構.
inception_3a = Inception(192,64,(96,128),(16,32),32)
o=inception_3a(o)
print(o.shape)輸出
o1: torch.Size([1, 64, 28, 28])
o2: torch.Size([1, 128, 28, 28])
o3: torch.Size([1, 32, 28, 28])
o4: torch.Size([1, 32, 28, 28])
concat: torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])依次類推,最終我們可以給出模型定義:
class GoogLeNet(nn.Module):
def __init__(self):
super(GoogLeNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)
self.inception_3a = Inception(192,64,(96,128),(16,32),32)
self.inception_3b = Inception(256,128,(128,192),(32,96),64)
self.max_pool3 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.inception_4a = Inception(480,192,(96,208),(16,48),64)
self.inception_4b = Inception(512,160,(112,224),(24,64),64)
self.inception_4c = Inception(512,128,(128,256),(24,64),64)
self.inception_4d = Inception(512,112,(144,288),(32,64),64)
self.inception_4e = Inception(528,256,(160,320),(32,128),128)
self.max_pool4 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.inception_5a = Inception(832,256,(160,320),(32,128),128)
self.inception_5b = Inception(832,384,(192,384),(48,128),128)
self.avg_pool = nn.AvgPool2d(kernel_size=7)
self.dropout = nn.Dropout(p=0.4)
self.fc = nn.Linear(1024,10,bias=True)
def forward(self,x):
feature = self.conv1(x)
feature = self.conv2(feature)
feature = self.inception_3a(feature)
feature = self.inception_3b(feature)
feature = self.max_pool3(feature)
feature = self.inception_4a(feature)
feature = self.inception_4b(feature)
feature = self.inception_4c(feature)
feature = self.inception_4d(feature)
feature = self.inception_4e(feature)
feature = self.max_pool4(feature)
feature = self.inception_5a(feature)
feature = self.inception_5b(feature)
feature = self.avg_pool(feature)
feature = self.dropout(feature)
out = self.fc(feature.view(x.shape[0],-1))
return out測試一下輸出
X=torch.randn((1,1,224,224))
net = GoogLeNet()
# for name,module in net.named_children():
# X=module(X)
# print(name,X.shape)
out = net(X)
print(out.shape)輸出
torch.Size([1, 10])上面的程式碼只是看起來複雜,其實對著前面圖裡描述的GoogleNet結構實現起來並不難.比如先寫出
class GoogLeNet(nn.Module):
def __init__(self):
super(GoogLeNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)然後用
X=torch.randn((1,1,224,224))
net = GoogLeNet()
for name,module in net.named_children():
X=module(X)
print(name,X.shape) 測試一下輸出,如果不對,就調整程式碼,看看是kernel_size,padding還是哪裡寫錯了.如果正確就繼續擴充套件程式碼為
class GoogLeNet(nn.Module):
def __init__(self):
super(GoogLeNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1,64,kernel_size=7,stride=2,padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64,64,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64,192,kernel_size=3,padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1),
)再次測試輸出的shape,如此,一層層layer新增下去,最終就可以完成整個模型的定義.
載入資料
batch_size,num_workers=16,4
train_iter,test_iter = learntorch_utils.load_data(batch_size,num_workers,resize=224)定義模型
net = GoogLeNet().cuda()
print(net)定義損失函式
loss = nn.CrossEntropyLoss()定義優化器
opt = torch.optim.Adam(net.parameters(),lr=0.001)定義評估函式
def test():
start = time.time()
acc_sum = 0
batch = 0
for X,y in test_iter:
X,y = X.cuda(),y.cuda()
y_hat = net(X)
acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
batch += 1
#print('acc_sum %d,batch %d' % (acc_sum,batch))
acc = 1.0*acc_sum/(batch*batch_size)
end = time.time()
print('acc %3f,test for test dataset:time %d' % (acc,end - start))
return acc訓練
num_epochs = 3
save_to_disk = False
def train():
for epoch in range(num_epochs):
train_l_sum,batch,acc_sum = 0,0,0
start = time.time()
for X,y in train_iter:
# start_batch_begin = time.time()
X,y = X.cuda(),y.cuda()
y_hat = net(X)
acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
l = loss(y_hat,y)
opt.zero_grad()
l.backward()
opt.step()
train_l_sum += l.item()
batch += 1
mean_loss = train_l_sum/(batch*batch_size) #計算平均到每張圖片的loss
start_batch_end = time.time()
time_batch = start_batch_end - start
train_acc = acc_sum/(batch*batch_size)
if batch % 100 == 0:
print('epoch %d,batch %d,train_loss %.3f,train_acc:%.3f,time %.3f' %
(epoch,batch,mean_loss,train_acc,time_batch))
if save_to_disk and batch % 1000 == 0:
model_state = net.state_dict()
model_name = 'nin_epoch_%d_batch_%d_acc_%.2f.pt' % (epoch,batch,train_acc)
torch.save(model_state,model_name)
print('***************************************')
mean_loss = train_l_sum/(batch*batch_size) #計算平均到每張圖片的loss
train_acc = acc_sum/(batch*batch_size) #計算訓練準確率
test_acc = test() #計算測試準確率
end = time.time()
time_per_epoch = end - start
print('epoch %d,train_loss %f,train_acc %f,test_acc %f,time %f' %
(epoch + 1,mean_loss,train_acc,test_acc,time_per_epoch))
train()實驗發現googlenet收斂比較慢.可能和全連線層用全域性平均池化取代有關.因為用全域性平均池化的話,相當於在全域性平均池化之前,提取到的特徵就是有高階語義的了,每一個feature map就代表了一個類別,所以前面負責特徵提取的卷積部分就需要提取出更高階的特徵.所以收斂會變慢.
完整代