
【論文閱讀】增量學習近期進展及未來趨勢預測
阿新 • • 發佈:2020-05-12
【摘要】 本文通過三篇發表在CVPR 2019上的論文,對增量學習任務進行簡單的介紹和總結。在此基礎上,以個人的思考為基礎,對這一研究領域的未來趨勢進行預測。
一、背景介紹
目前,在滿足一定條件的情況下,深度學習演算法在影象分類任務上的精度已經能夠達到人類的水平,甚至有時已經能夠超過人類的識別精度。但是要達到這樣的效能,通常需要使用大量的資料和計算資源來訓練深度學習模型,並且目前主流的影象分類模型對於訓練過程中沒見過的類別,識別的時候完全無能為力。一種比較簡單粗暴的解決方法是:對於當前模型識別不了的類別,收集大量的新資料,並和原來用於訓練模型的資料合併到一起,對模型進行重新訓練。但是以下的一些因素限制了這種做法在實際中的應用:- 當儲存資源有限,不足以儲存全部資料的時候,模型的識別精度無法保證;
- 重新訓練模型需要消耗大量的算力,會耗費大量的時間,同時也會付出大量的經濟成本(如電費、伺服器租用費等)。
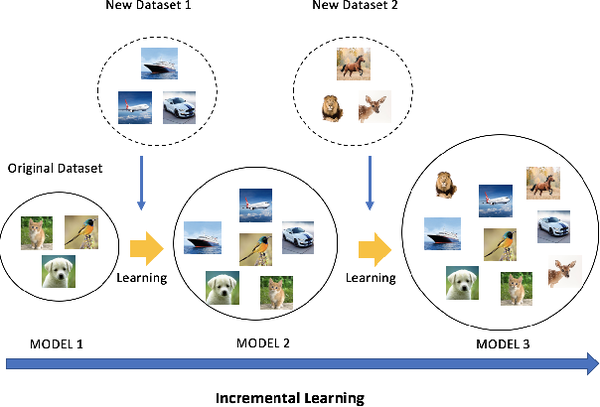
- 不同類別的資料是分批次提供給演算法模型進行學習的,如下圖所示;
- 系統的儲存空間有限,至多隻能儲存一部分歷史資料,無法儲存全部歷史資料,這一點比較適用於手機、PC機等應用場景;
- 在每次提供的資料中,新類別的資料量比較充足。
 這類任務的難點主要體現在兩方面:
這類任務的難點主要體現在兩方面:
- 由於每次對模型的引數進行更新時,只能用大量的新類別的樣本和少量的舊類別的樣本,因此會出現新舊類別資料量不均衡的問題,導致模型在更新完成後,更傾向於將樣本預測為新增加的類別,如下圖所示;
- 由於只能儲存有限數量的舊類別樣本,這些舊類別的樣本不一定能夠覆蓋足夠豐富的變化模式,因此隨著模型的更新,一些罕見的變化模式可能會被遺忘,導致新的模型在遇到一些舊類別的樣本的時候,不能正確地識別,這個現象被稱作“災難性遺忘”。
 目前主流地增量學習演算法可以分為兩類:
目前主流地增量學習演算法可以分為兩類:
- 基於GAN的方法。這類方法不儲存舊類別的樣本,但是會使用生成對抗網路(GAN),學習生成每類的樣本。因此,在對模型進行更新的時候,只要使用GAN隨機生成一些影象即可,無需儲存大量的樣本;
- 基於代表性樣本的方法。這類方法對於每個舊類別,儲存一定數量的代表性樣本,在訓練的時候,使用舊類別的代表性樣本和新類別的樣本來更新模型,從而保證模型既能準確地識別舊類別,也能準確地識別新類別。下面針對這兩類方法,分別簡單介紹一些發表在CVPR 2019上的論文,並簡單總結一下這兩類方法各自的優勢和不足。
二、基於GAN的方法
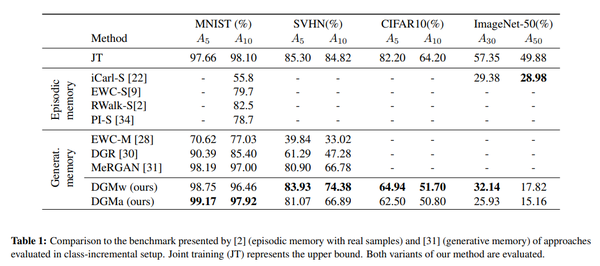
論文:Learning to Remember: A Synaptic Plasticity Driven Framework for Continual Learning 作者:Oleksiy Ostapenko, Mihai Puscas, Tassilo Klein, Patrick Jaehnichen, Moin Nabi 出處:CVPR 2019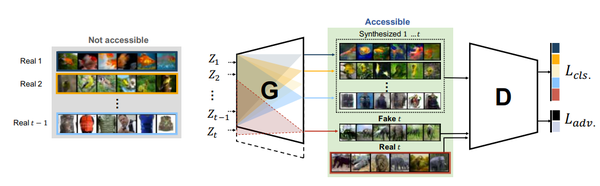 這篇文章提出了一種基於GAN的增量式學習方法,如上圖所示。其中判別器(D)部分的設計與ACGAN基本相同,包括對抗損失和分類損失兩部分;生成器的結構則比較特殊。具體來說,本文提出的生成器除了需要學習生成器的權重之外,還要對每一層的權重學習一個mask。這個mask的作用是限制每次允許更新的權重,從而防止模型忘記之前學習到的東西。由於mask的存在,模型越往後可以更新的權重值也會越少,因此可能會導致生成器的生成能力不足。為了解決這個問題,作者提出在每次學習完新資料之後,增加生成器的引數量,從而保證生成器的生成能力不會明顯下降。實驗結果顯示,在小規模的資料集上,該方法有比較明顯的效能優勢,如下表所示。
這篇文章提出了一種基於GAN的增量式學習方法,如上圖所示。其中判別器(D)部分的設計與ACGAN基本相同,包括對抗損失和分類損失兩部分;生成器的結構則比較特殊。具體來說,本文提出的生成器除了需要學習生成器的權重之外,還要對每一層的權重學習一個mask。這個mask的作用是限制每次允許更新的權重,從而防止模型忘記之前學習到的東西。由於mask的存在,模型越往後可以更新的權重值也會越少,因此可能會導致生成器的生成能力不足。為了解決這個問題,作者提出在每次學習完新資料之後,增加生成器的引數量,從而保證生成器的生成能力不會明顯下降。實驗結果顯示,在小規模的資料集上,該方法有比較明顯的效能優勢,如下表所示。
三、基於代表性樣本的方法
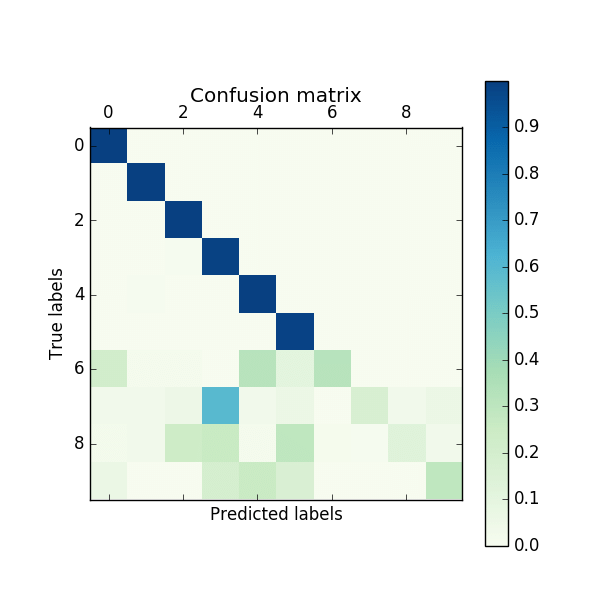
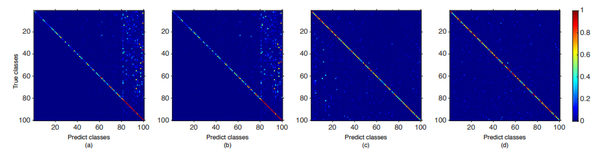
論文:Large Scale Incremental Learning 作者:Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, Yun Fu 出處:CVPR 2019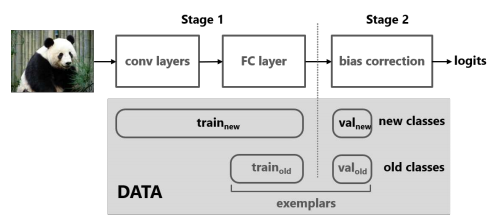 這篇文章首先假設增量學習的方法,相比於直接使用所有資料進行訓練的方法,效能下降大的原因,是因為CNN模型最後用於輸出類別預測概率的全連線層向新增加的類別偏移了(即更傾向於將類別預測為新加入的類別),並通過實驗(固定網路前邊的層並重新訓練全連線層、混淆矩陣)驗證了這個假設。為了解決這個問題,作者提出對新加入類別的概率進行修正,如上圖所示。
具體來說,本文方法需要儲存一定數量的舊類別的代表性樣本,在得到新類別資料的時候,包含三步操作:
這篇文章首先假設增量學習的方法,相比於直接使用所有資料進行訓練的方法,效能下降大的原因,是因為CNN模型最後用於輸出類別預測概率的全連線層向新增加的類別偏移了(即更傾向於將類別預測為新加入的類別),並通過實驗(固定網路前邊的層並重新訓練全連線層、混淆矩陣)驗證了這個假設。為了解決這個問題,作者提出對新加入類別的概率進行修正,如上圖所示。
具體來說,本文方法需要儲存一定數量的舊類別的代表性樣本,在得到新類別資料的時候,包含三步操作:
- 將舊類別的代表性樣本和新類別的樣本劃分為訓練集和校驗集,其中在校驗集裡,各類的樣本數量是均衡的;
- 使用訓練樣本訓練一個新模型,其中包含兩部分損失,一個是標準的分類損失,另一個是知識蒸餾損失,目標是保證新模型在舊類別上的概率預測值和舊模型儘可能相同,從而保留舊模型學到的資訊(新類別和舊類別的樣本都參與計算兩個損失);
- 使用校驗集的資料學習一個線性模型,對新模型預測的logits進行修正,其中保留舊類別上的logits,只對新類別上的logits進行修正,如下邊的公式所示。
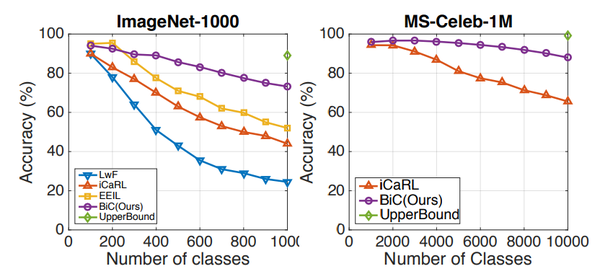
 實驗結果顯示,相比於經典的LwF方法、iCaRL方法,本文方法在大規模、大增幅(一次加入的類別多)的資料庫和設定下提升較明顯,在小資料庫上與已有方法效能相當,如下邊的圖表所示。
實驗結果顯示,相比於經典的LwF方法、iCaRL方法,本文方法在大規模、大增幅(一次加入的類別多)的資料庫和設定下提升較明顯,在小資料庫上與已有方法效能相當,如下邊的圖表所示。

 論文:Learning a Unified Classifier Incrementally via Rebalancing
作者:Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, Dahua Lin
出處:CVPR 2019
論文:Learning a Unified Classifier Incrementally via Rebalancing
作者:Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, Dahua Lin
出處:CVPR 2019
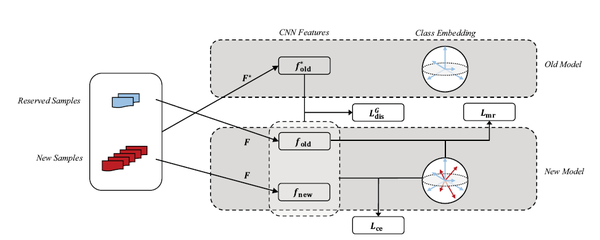 這篇文章根據現有增量學習演算法的問題,提出了三點改進,如上圖所示:
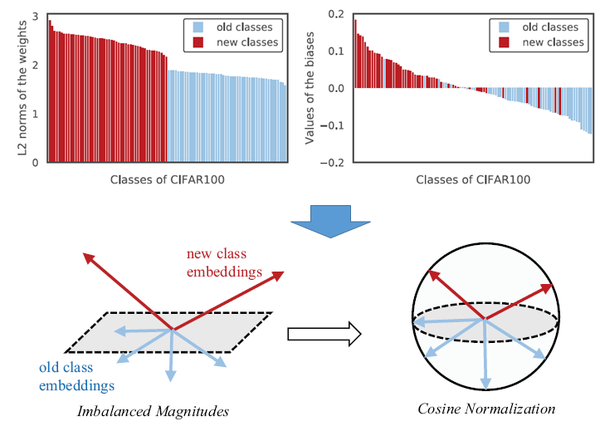
第一,作者發現,由於新類的特徵向量幅值和舊類的不一樣,因此模型會偏向於新類。為了解決這個問題,提出對特徵向量、分類器的權重向量進行歸一化,保證幅值等於1。相應的,分類損失和蒸餾損失也都在歸一化之後的特徵向量上使用,如下圖所示;
這篇文章根據現有增量學習演算法的問題,提出了三點改進,如上圖所示:
第一,作者發現,由於新類的特徵向量幅值和舊類的不一樣,因此模型會偏向於新類。為了解決這個問題,提出對特徵向量、分類器的權重向量進行歸一化,保證幅值等於1。相應的,分類損失和蒸餾損失也都在歸一化之後的特徵向量上使用,如下圖所示;
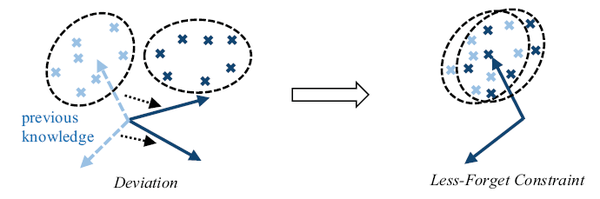
 第二,為了減少模型遺忘,要求新模型的歸一化特徵和舊模型儘量相同,因此提出了一種新的蒸餾損失。這個損失的思想是,舊模型學到的不同類別的特徵分佈一定程度上反映了類別之間的關係,因此保持這種關係對於防止遺忘也有意義,如下圖所示;
第二,為了減少模型遺忘,要求新模型的歸一化特徵和舊模型儘量相同,因此提出了一種新的蒸餾損失。這個損失的思想是,舊模型學到的不同類別的特徵分佈一定程度上反映了類別之間的關係,因此保持這種關係對於防止遺忘也有意義,如下圖所示;
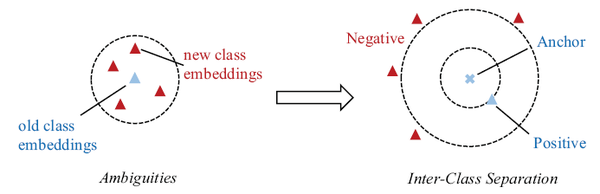
 第三,在分類的時候,使用large-margin的分類損失,使用易誤分的新類別作為難例,提升訓練的效率,如下圖所示。
第三,在分類的時候,使用large-margin的分類損失,使用易誤分的新類別作為難例,提升訓練的效率,如下圖所示。
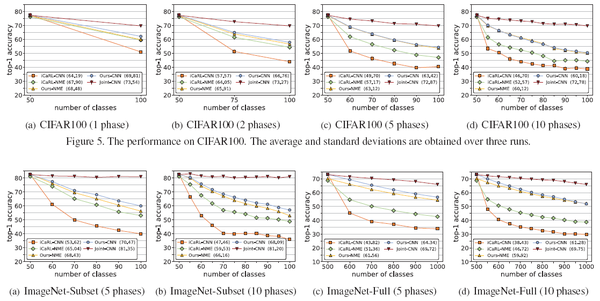
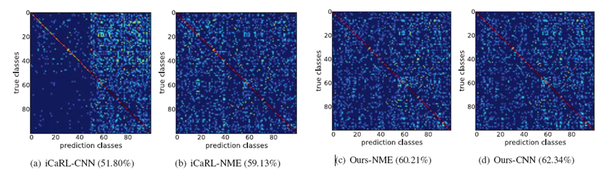
 實驗結果顯示,該方法相比於經典的iCaRL增量學習演算法,有十個點以上的提升,如下圖所示。
實驗結果顯示,該方法相比於經典的iCaRL增量學習演算法,有十個點以上的提升,如下圖所示。
四、總結
增量學習的主流方法分為基於GAN的方法和基於代表性樣本的方法兩大類。 其中,基於GAN的方法通過GAN“記住”舊類別的資料,在更新模型的時候,可以生成任意多的舊類別樣本,但是這類方法的上限受制於GAN的生成能力。此外,基於GAN的方法宣稱的一個優勢是不需要儲存歷史資料,但是一般來說,GAN模型本身也要佔用一定的儲存空間(通常在幾十MB這個數量級),如果用這部分空間來直接儲存代表性的歷史資料,按照一張圖片200kB計算,也可以儲存幾百張圖片了。所以一個很有意思的問題是,佔用同樣儲存空間的情況下,基於GAN的方法真的比基於代表性樣本的方法更好麼?從目前來看,基於GAN的方法識別精度通常不如基於代表性樣本的方法。未來基於GAN的增量學習方法如果想真正實用化,既要提升生成影象的質量,還要保證在使用同樣的儲存空間或者更少的儲存空間的情況下,達到更好的效能,任重而道遠。 另一方面,基於代表性樣本的方法則儲存少量的歷史樣本,在更新模型的時候,使用一個額外的蒸餾損失,保證舊模型的知識可以遷移到新模型中,目前來看,這類方法的識別精度通常更高一些。 不過增量學習的思路不應該侷限於這兩大類方法,是否有可能既不用GAN,也不儲存代表性的歷史樣本,而只使用舊模型本身來進行增量學習呢?或者是否有其他更高效的方法?這些都是值得未來繼續探索的方向。 總的來說,在條件允許的情況下,使用全部資料重新訓練模型的效果仍然是毫無爭議的最佳,GNN和代表性樣本兩種增量學習方法仍然達不到使用所有資料完全重新訓練的識別精度。因此,當前的增量學習演算法仍然有很長的路要走。但是目前看來,增量學習這條路如果能夠走通,無疑會大量減少雲服務對資源的需求量;另一方面,在一些對資料安全十分敏感的應用中,也可以保證資料不出內網,在有限的計算資源下即可完成模型的更新。所以在我看來,增量學習這個研究方向的前景還是很光明的,只是目前的技術還沒有發展到足夠使用的地步而已。 點選關注,第一時間瞭解華為雲新鮮技術~ &nbs
&nbs