
kylin streaming原理介紹與特點淺析
阿新 • • 發佈:2020-07-28
[toc]
# 前言
最近搭了Kylin Streaming並初步測試了下,覺得這個東西雖然有些限制,但還是蠻好用的,所以系統寫篇文章總結下其原理和一些配置。
Kylin Streaming是Kylin3.0最新引入的一個功能,意為OLAP查詢提供亞秒級的資料延遲,即在攝入資料後,立即可以在OLAP查詢中體現出來。
用過Kylin應該都知道,它主要是通過預構建的方式,將資料從Hive預先計算然後儲存到Hbase。查詢的時候一些複雜操作直接轉成Hbase的scan和filter操作,大大降低OLAP查詢響應時間。
而在比較早版本的Kylin其實是有提供從kafka構建流式應用的,只是那時候走的還是預構建然後存到hbase的路子。這其實是微批的思路,缺點是延遲會比較高(十幾分鍾級別的延遲)。
這個延遲在某些場景下肯定是無法使用的,所以19年Kylin開始對實時計算這塊進行開發,20年5月份時候的kylin3.0.2算是第一個正式可用的streaming版本(另外2020.7.2,kylin3.1.0已釋出)。資料來源還是kafka,只是現在增加了其他模組已支援亞秒級的資料延遲。
接下來主要從架構說起,再說到底層一些元件的實現方式,最後討論下一些功能方面的實現以及具體的配置。
# kylin streaming設計和原理
### 架構介紹
kylin streaming在架構上增加了兩個模組,可以看看架構圖。
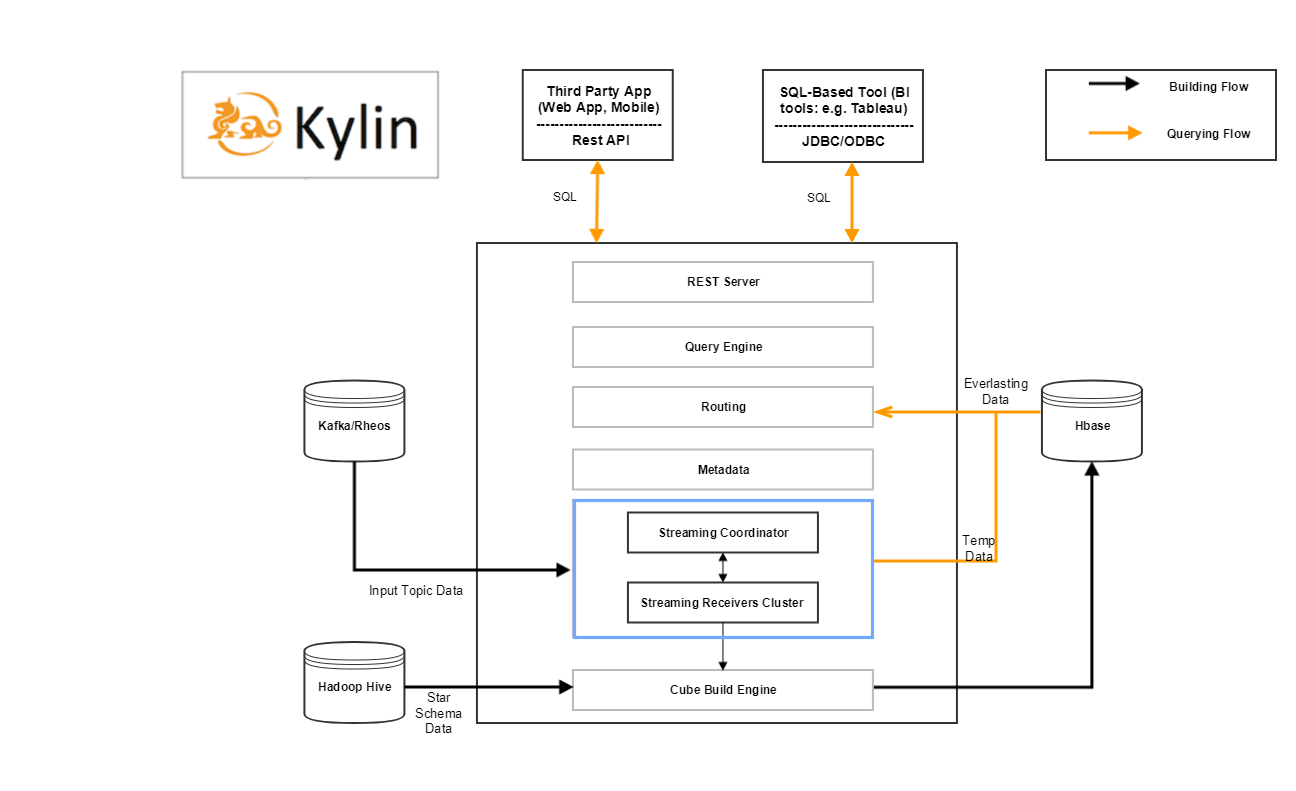
其中藍色方框內的就是增加的元件內容,那麼整個kylin streaming 包含的元件有:
- Kafka Cluster [data source]
- HBase Cluster [historical part storage]
- Zookeeper Cluster [receiver metadata storage]
- MapReduce [distributed computation]
- HDFS [distributed storage]
- **Kylin Process [job server/query server/coordinator]**
- **Kylin streaming receiver Cluster [real-time part computation and storage]**
- Query Engine,Build Engine
後面兩個就是在kylin streaming中新增加的模組,即streaming coordinator和streaming receiver cluster。其他的還有用於構建源表的kafka,儲存資料的Hdfs和Hbase,計算結果用的MapReduce。這裡只重點介紹後面兩個。
##### streaming coordinator
streaming coordinator相當於streaming receiver cluster的master,主要負責做一些協調分配工作,比如分配kafka哪個分割槽的資料分配到哪個streaming receiver的副本,控制消費速率等等。
而具體要指定哪個節點為streaming coordinator,只需要指定kylin.server.mode配置為all(all模式還包含了query server和job server模組)或stream_coordinator就行。另外可以部署多臺機器為streaming coordinator以預防單點故障。
##### streaming receiver cluster
streaming receiver即streaming receiver cluster的worker,被streaming coordinator管理。主要負責:
- 攝入實時資料
- 構建基礎的cuboid
- 接收查詢請求,根據自身資料執行請求並返回
- 將自己快取的segment資訊持久化到HDFS
另外為了容災,多個streaming receiver可以組成一個Replica Set。這一個Replica Set中的streaming receiver都會執行同樣的任務(即消費同樣的kafka分割槽),它們的作用僅僅是當某個receiver失效的時候可以快速切換。
當然還有Query Engine和Build Engine,即查詢引擎和構建引擎,這些都是kylin原先就有的模組。用於執行查詢SQL和構建cube。在kylin streaming中,都對原先的模組做了拓展,以支援實時情況下的查詢和構建。那麼接下來來看看實時情況下構建和查詢的流程。
### kylin streaming資料構建流程
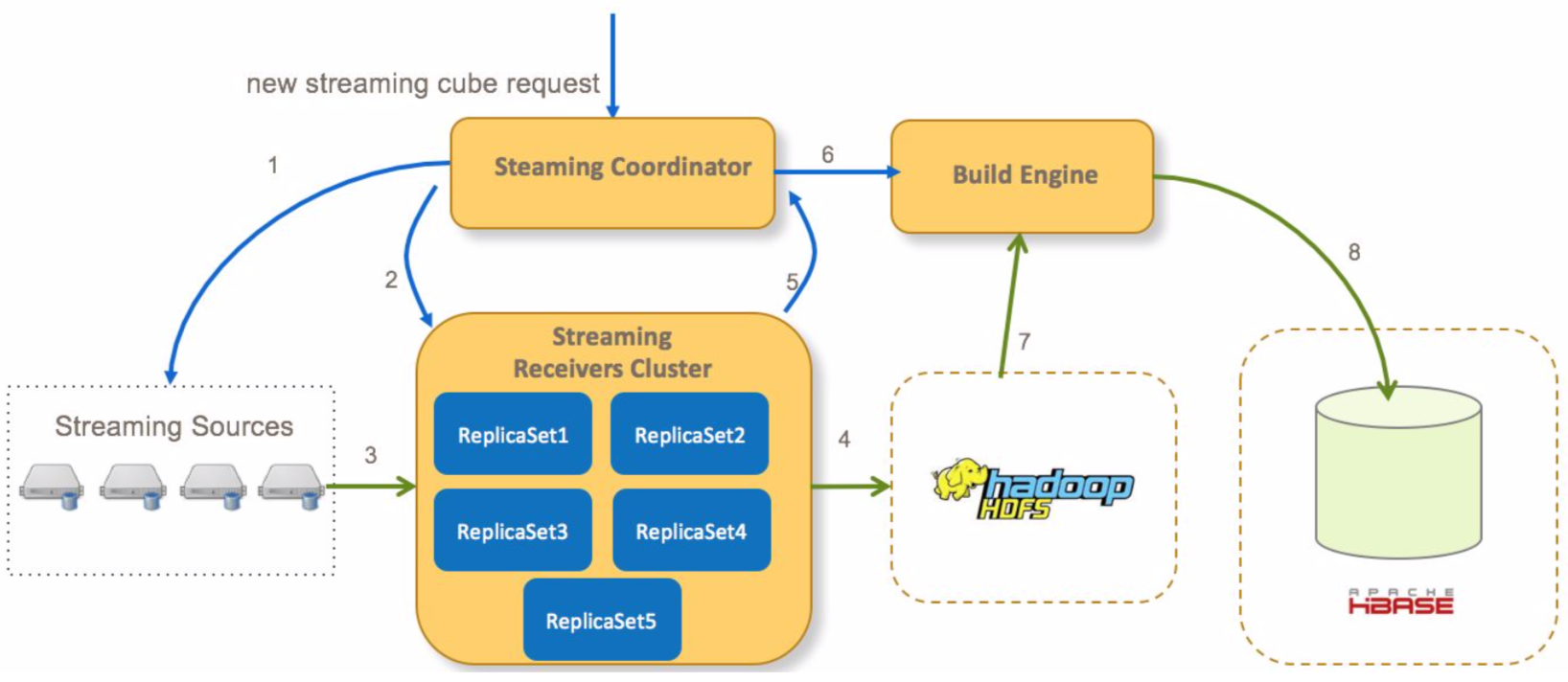
在kylin streaming種,資料會先儲存在記憶體中,經過一定時間後會通過構建cube的方式持久化到hdfs/hbase中,而這裡的資料構建流程,則是包含整個資料的生命週期。
這裡主要將文件種的內容搬過來,主要流程如下:
1. Coordinator向流式cube的所有分割槽的streaming source傳送請求確認資訊
2. Coordinator分配哪一個receivers消費streaming資料,並向receivers傳送請求開始消費資料
3. receiver消費資料並構建索引
4. 一段時間以後,receiver將immutable狀態的segment從本地持久化到hdfs(關於streaming segment狀態變更參見下文)
5. receiver通知coordinator一個segment已經持久化到hdfs
6. 在所有receivers(多個分割槽)提交其對應segment後,coordinator提交一個全量cube構建任務(在記憶體中segment只構建最基礎的cuboid)到build engine
7. build engine從hdfs檔案中構建全量的cuboid
8. build engine村寧次cuboid資料到hbase,然後coordinator會通知receivers刪除本地儲存的實時資料
然後接下來再看看查詢的流程
### kylin streaming查詢流程
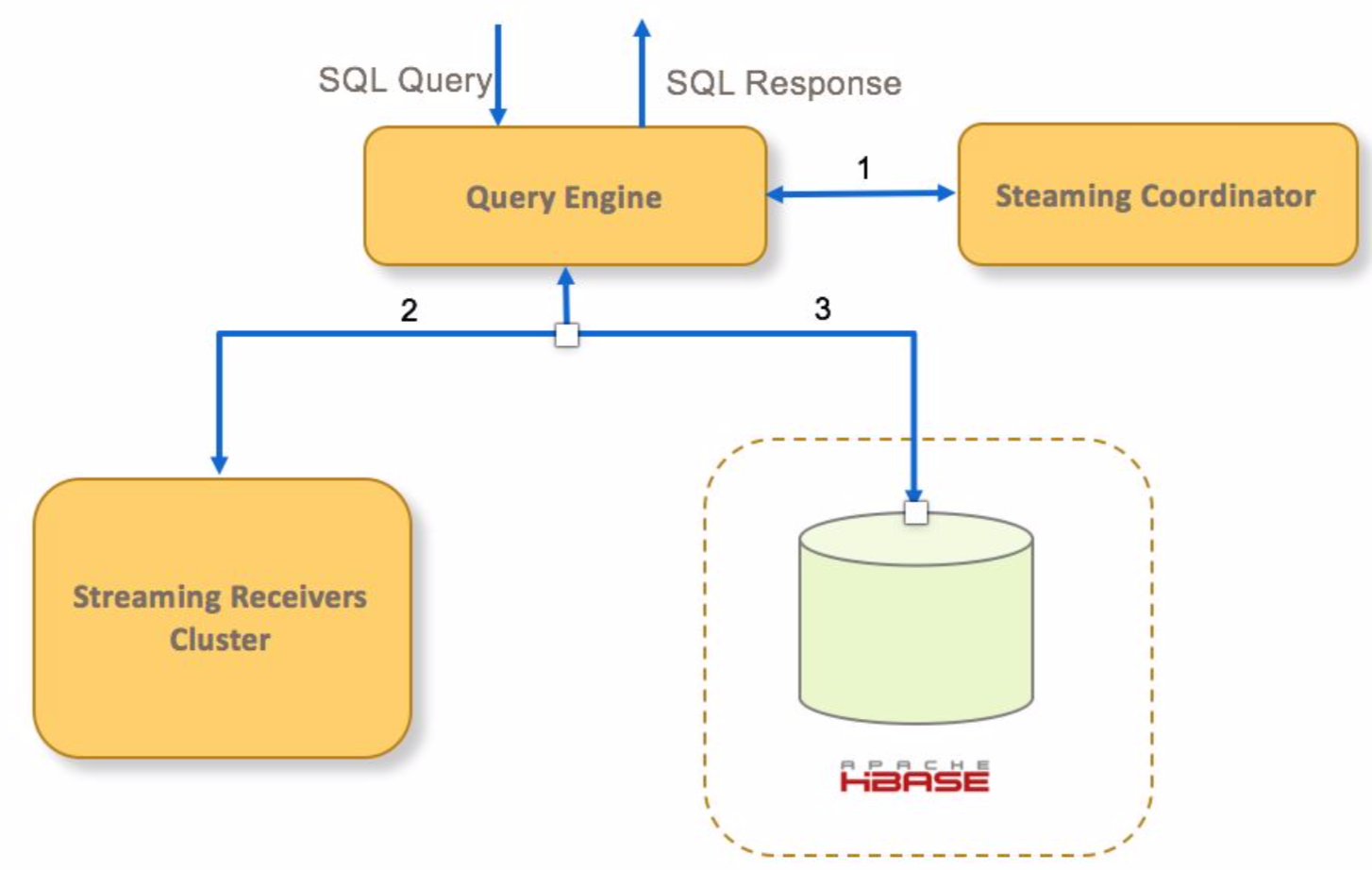
1. 如果查詢命中一個streaming cube,query engine向cube的receivers的Coordinator傳送請求
2. query engine傳送查詢請求到對應的receivers查詢實時segment
3. query engine傳送請求到hbase查詢已經持久化的歷史segment
4. query engine聚合實時和歷史資料,然後返回給客戶端
以上就是kylin streaming查詢引擎和構建引擎的大致流程,接下來再說說一些內部實現細則。
# kylin streaming實現細節
### kylin streaming segment儲存實現
常見的流處理處理的資料時間,通常有兩種,包括事件時間(event time),處理時間(process time)。kylin streaming的儲存結構是,按照事件時間,將資料儲存成一個一個的segment。
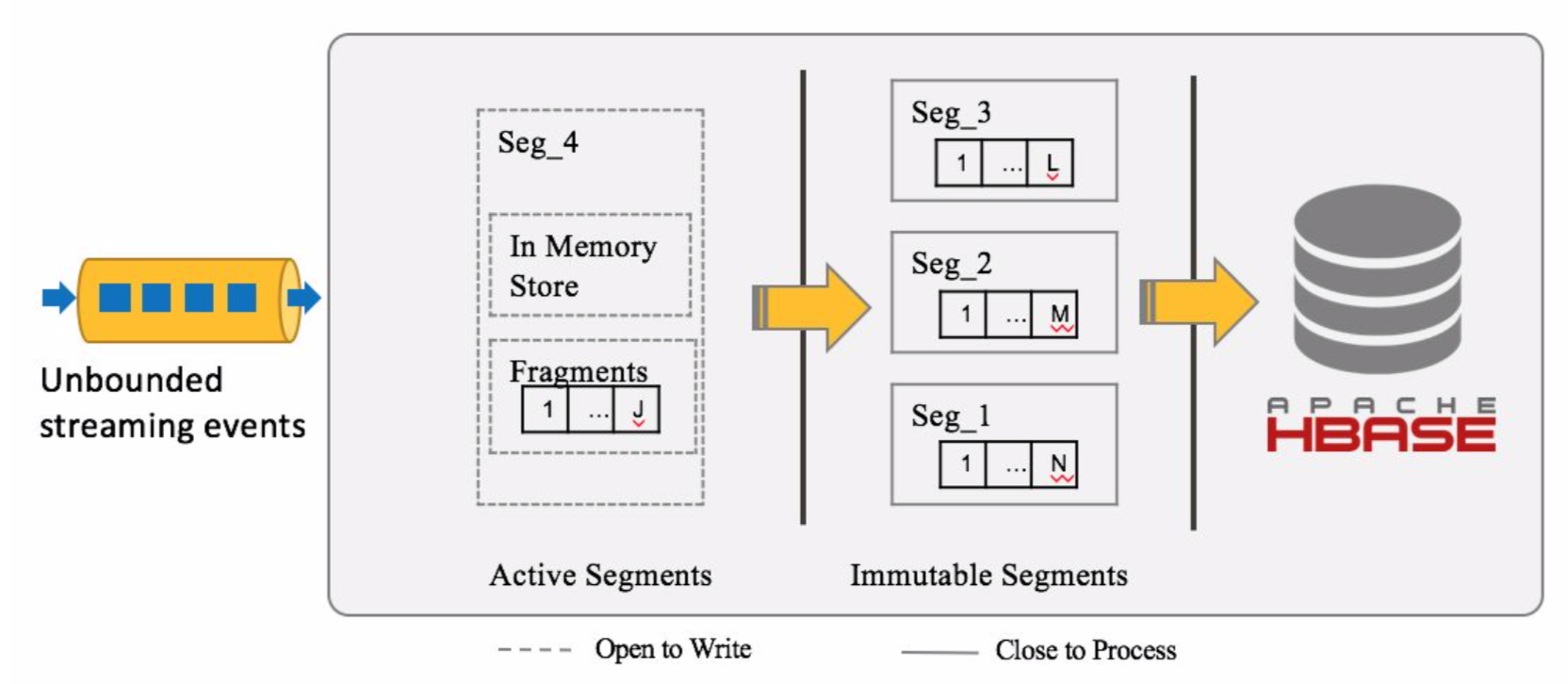
先說下訊息接收訊息的儲存邏輯,當一個訊息到達的時候,會根據事件時間查詢對應的segment存在否,如果不存在則去建立對應的segment。
而segment在一開始建立的時候,它的狀態是Active,但是當一定時間(這個時間根據配置)沒有訊息到達,該segment的狀態就會變成Immutable,然後儲存到Hdfs中。
初始的segment是在記憶體中進行資料聚合和度量計算的(注意receiver只計算基礎的coboid和指定的coboid,而非離線資料那樣計算全量的cuboid),但是到達一定大小(也是配置)後,會刷到磁碟上儲存成fragment檔案,而fragment檔案到達一定大小後,又會觸發merge操作,非同步將多個fragment檔案進行合併。
其中相同cuboid的資料會儲存在同一資料夾下,而metadata則以json格式另外儲存。
為了提高查詢效能,fragment的儲存格式是列式儲存格式,如下圖所示:
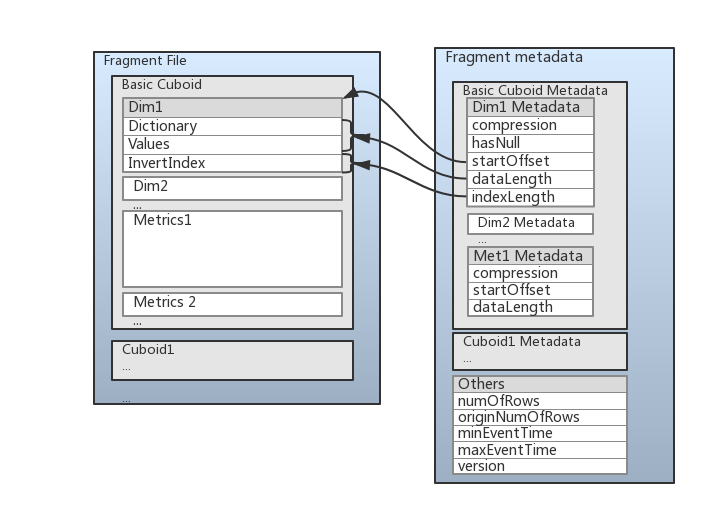
這張圖將前面講到的東西都基本包含了,資料中儲存了維度資料(dim)和度量資料(Metrics)。維度資料儲存成三個部分資料:
- 第一部分是Dictionary(字典)編碼部分,當維度的encoding屬性設定為‘Dict’時存在。
- 第二部分則是資料的值/dictionary編碼後的值,這部分資料會被壓縮。
- 第三部分是倒排索引,儲存倒排索引是資料結構是Roaring Bitmap,一種優化過後的bitmap結構。
### 重平衡/重分配
在某些情況下(比如Kafka訊息快速增長),當前的receiver叢集可能出現負載不平衡的現象,這時候需要讓revicer下線,重平衡以使整個叢集負載均衡。
重平衡是自動發生,這個過程可能會持續幾秒的時間。
在實際過程中,重平衡是一個從CurrentAssignment狀態到NewAssignment狀態的過程。 整個重平衡操作是一個分散式事務,可以分為四個步驟。 如果一個步驟失敗,將執行自動回滾操作。
主要流程如下:
1. 停止當前分配狀態(CurrentAssignment)所有Receiver,並且每個Receiver將消費的offset量報告給coordinator,coordinator合併每個分割槽的偏移量,保留最大偏移量(Replica Set中的Receiver可能消費進度不一樣)。然後通知Receiver消費到統一(最大)偏移量,然後再次停止消耗
2. coordinator向所有新分配狀態(NewAssignment)下的Receiver傳送一個分配請求,更新其分配情況。然後coordinator向所有newAssignment的Receiver傳送一個startConsumer請求,要求他們根據上一步中的分配情況開始消費。
3. 向刪除的Replica Set所屬的所有接收方傳送ImmutableCube請求,要求它們強制將所有segment轉換為Immutable segment。
4. 更新元資料並將NewAssignment + RemovedAssignment記錄到元資料中(已刪除的Replica Set仍會接受查詢請求,直到重分配完成)
### 故障恢復
在流處理中,由於資料是無界的,所以故障是不可避免的,哪怕是上面提到的Replica Set,也只能儘可能減少故障影響。所以對付故障的重點並非預防,而實在於如何進行故障恢復。
kylin streaming對故障恢復的做法是在receiver端定期進行checkpoint,這樣當receiver故障重啟後資料也能正確重新處理(依賴於kafka的上游備份能力)。
而checkpoint主要有兩部分內容需要checkpoint,第一部分是消費資訊,即kafka的消費offset資訊。第二部分則是磁碟資料狀態資訊,即最新的{segment:framentID}資訊。
那麼當重啟的時候,發現磁碟上的fragment資料比checkpoint記錄的磁碟資訊資料新怎麼辦呢?答案是刪除沒有checkpoint的資料。
# kylin streaming優化
首先先來說說Coordinator和Replica Set的數量,在實際生產環境中,為了避免單點故障問題,最好是能夠將Coordinator部署兩個或以上。而Replica Set的數量則與資料來源,即kafka topic的分割槽數相關。kylin本身提供一個配置,可以讓我們指定一個topic全部分割槽由多少個Replica Set消費,所以Replica Set的數量應該與topic的分割槽數呈倍數關係或冗餘一兩個,以便充分利用叢集的負載的同時增加容錯性。
還有一點,記得前面提到的一個Replica Set由多個Receiver組成嗎,所以最好一個Replica Set中配置兩個Receiver例項。
下面列舉下跟優化相關的一些配置,並且會解釋對於配置的作用。
PS:由於kylin streaming模組還處於高速迭代的階段,有些配置的說明或預設值可能會發生更改,詳細還是以官網最新資料為準。
- kylin.stream.receiver.use-threads-per-query:指定每個查詢預設的執行緒數(The parallelism of scan in receiver side),預設是8。可以根據負載和資料情況,適當調大此引數。
- kylin.stream.index.maxrows: 指定了快取在堆內的聚合後的事件最大行數。預設值是50000。這個引數會影響Fragment File的數量,可以根據需求適當調高。
- kylin.stream.cube-num-of-consumer-tasks: 指定了一個topic的全部訊息的攝入將由多少Replica Set來負責,即一個topic的全部分割槽分配到多少個Replica Set,當然也跟你當前的Replica Set數量有關。如果訊息速率較大,需要適當提升這個數值。預設值是3。
- kylin.stream.checkpoint.file.max.num: 指定了Receiver為每一個Cube保留的checkpoint檔案數量。預設值是 5。
- kylin.stream.index.checkpoint.intervals: 指定了Receiver進行checkpoint的間隔。預設值是 300秒。有關checkpoint內容請參閱上面介紹。
- kylin.stream.cube.window: 指定了Streaming Segment的時間間隔。比如說[2019-01-01 11:00:00, 2019-01-01 12:00:00]就是一個segment的時間間隔,在這個時間內到達的訊息都會歸檔到這個segment中(當然不能超過配置的大小),預設值是3600。
- kylin.stream.cube.duration: 指定了Streaming Segment會等待遲到的訊息多久,預設值7200。接上述的例子,意思是如果一個訊息遲到7200秒以內,它還是會被歸檔到[2019-01-01 11:00:00, 2019-01-01 12:00:00]這個segment中。
- kylin.stream.immutable.segments.max.num: 指定了在Receiver端,一個Cube最多可以保持多少個IMMUTABLE segment,因為Receiver端的效能和Fragment File的數量呈負相關。預設值是 100。
- kylin.stream.segment.retention.policy: 當Segment狀態變為IMMUTABLE,該配置指定了Receiver如何處理本地Segment Cache。可選值包含purge和fullBuild。設定為purge後,Receiver會等待一定時間後刪除本地資料;設定為fullBuild後,資料會上傳到HDFS並等待構建。預設值是fullBuild。
- kylin.stream.consume.offsets.latest:指定了Receiver從什麼位置開始消費,設定成true則從最新的offset開始消費,false則從最早的(earliest)位置消費。預設值是 true。
至於上述引數的最佳實踐,暫時沒有,kylin streaming還是比較新的,可能有些配置還需要不斷試錯才能知道哪個比較好~
# 總結
小結一下,本篇簡單介紹了kylin streaming的功能,介紹了構建和查詢在系統內部的邏輯流程。然後討論了下kylin streaming在內部的一些實現細節。最後從在配置上說明有哪些點可以進行優化(比較簡陋)。
總的來說,kylin streaming繼承了kylin的優點,那就是查詢快,能容納大量資料。但缺點也明顯,那就是靈活性欠佳,可能改下schema就要重新構建model,cube什麼的。
以上~~
參考文章:
[Real-time OLAP](http://kylin.apache.org/docs/tutorial/realtime_olap.html)
[Real-time Streaming Design in Apache Kylin
](http://kylin.apache.org/blog/2019/04/12/rt-streaming-design/)
[Deep dive into Kylin's Real-time OLAP](http://kylin.apache.org/blog/2019/07/01/deep-dive-real-time