
樣本標準差分母為何是n-1
大家好,今天給大家介紹標準差。標準差在統計領域是一個重要概念,有些地方晦澀難懂,特別是樣本標準差的分母為何是n-1,而不是n或n-2,接下來我會一一介紹並用計算機模擬難點。
什麽是標準差?下面看兩組數[28,29,30,31,32],[10,20,30,40,50],它們的平均數都是30。這兩組數是一致的嗎?實際上,這兩組數離散程度有很大區別。

用numpy模塊計算,兩組數的標準差相差10倍


方差是實際值與期望值之差平方的平均值。方差,通俗點講,就是和中心偏離的程度!用來衡量一批數據的波動大小(即這批數據偏離平均數的大小)並把它叫做這組數據的方差。記作S2。 在樣本容量相同的情況下,方差越大,說明數據的波動越大,越不穩定。標準差就是方差的平方根。方差和標準差用於不同場合,方便計算。
(標準差英文解釋)

方差公式

標準差公式

難點來了,總體標準差和樣本標準差的公式是有區別的,如下圖

樣本標準差公式中,分母是n-1。

為何樣本標準差的分母為何是n-1,而不是n或n-2?
我們用計算機建模,環境Anaconda(python2.7)
參數解釋:
Sigma表示總體標準差
S表示樣本標準差
ddofValue=0 表示樣本標準差分母是n
ddofValue=1 表示樣本標準差分母是n-1
ddofValue=2 表示樣本標準差分母是n-2
算法思路:
1.模擬出一個總體(服從正態分布的1000個隨機數)
2. 從總體中隨機抽樣(100個隨機數)
3.分別算出總體和樣本的標準差,然後相減得到distance差值
4.循環1000次試驗,把1000個distance相加,得到total_distance
5.在步驟3中,分別對樣本標準差的分母取n, n-1,n-2, 最終得到dict_modes
觀察dict_modes,ddof1的絕對值最小3.8
ddof1=1 表示樣本標準差分母是n-1

總結:s樣本標準差的分母采用n-1更加接近真實的總體標準差。通過計算機模擬,我們證明了為什麽樣本標準差的分母n-1比較合適,而不是n或n-2。
源代碼:
如果允許代碼有任何問題,請反饋至郵箱[email protected]
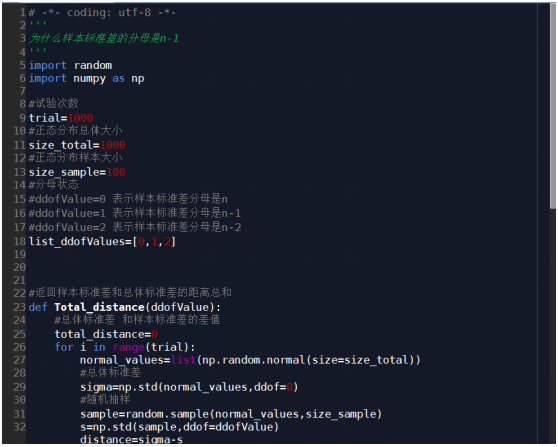
# -*- coding: utf-8 -*-
‘‘‘
為什麽樣本標準差的分母是n-1
‘‘‘
import random
import numpy as np
#試驗次數
trial=1000
#正態分布總體大小
size_total=1000
#正態分布樣本大小
size_sample=100
#分母狀態
#ddofValue=0 表示樣本標準差分母是n
#ddofValue=1 表示樣本標準差分母是n-1
#ddofValue=2 表示樣本標準差分母是n-2
list_ddofValues=[0,1,2]
#返回樣本標準差和總體標準差的距離總和
def Total_distance(ddofValue):
#總體標準差 和樣本標準差的差值
total_distance=0
for i in range(trial):
normal_values=list(np.random.normal(size=size_total))
#總體標準差
sigma=np.std(normal_values,ddof=0)
#隨機抽樣
sample=random.sample(normal_values,size_sample)
s=np.std(sample,ddof=ddofValue)
distance=sigma-s
total_distance+=distance
return total_distance
#選擇最佳模型
def Dict_modes():
distance_ddof0=Total_distance(list_ddofValues[0])
distance_ddof1=Total_distance(list_ddofValues[1])
distance_ddof2=Total_distance(list_ddofValues[2])
dict_modes={}
dict_modes["ddof0"]=distance_ddof0
dict_modes["ddof1"]=distance_ddof1
dict_modes["ddof2"]=distance_ddof2
return dict_modes
dict_modes=Dict_modes()
print dict_modes
‘‘‘
for i in range(trial):
normal_values=list(np.random.normal(size=n))
#總體標準差
sigma=np.std(normal_values,ddof=0)
#plt.hist(normal_values)
#隨機抽樣
sample=random.sample(normal_values,100)
#plt.hist(sample)
s=np.std(sample,ddof=ddofValue)
distance=sigma-s
total_distance+=distance
print"when ddofValue is:",ddofValue
print"Distance:",total_distance
‘‘‘
End.
樣本標準差分母為何是n-1