
殘差神經網路
之前的章節,我們利用一個僅包含一層隱藏層的簡單神經網路就在MNIST識別問題上獲得了98%左右的準確率。我們於是本能會想到用更多的隱藏層,構建更復雜的神經網路將會為我們帶來更好的結果。
就如同在進行影象模式識別的時候
,第一層的神經層可以學到邊緣特徵
,第二層的可以學到更復雜的圖形特徵,例如三角形,長方形等,第三層又會識別更加複雜的圖案。
這樣看來,多層的結構就會帶來更強大的模型,進行更復雜的識別。
那麼在這一章,就試著訓練這樣的神經網路來看看對結果有沒有什麼提升。不過我們發現,訓練的過程將會出現問題,我們的神經網路的效果並沒有什麼提升。
為什麼會出現這樣的情況呢,這一章就是主要圍繞著這個問題展開的。
我們將會發現,不同層的學習速率是不一樣的。
例如,在後面的網路層訓練正在順利學習的時候,前面網路層的學習卻卡住幾乎不動了。
而且我們會發現這並不是偶然的,
而是在理論上由梯度下降演算法導致的。隨著我們對問題的深入瞭解,我們會發現相反的情況也是可能發生的,就是前面網路層學習正常,而後面網路層學習停止。
這雖然看上去都是壞訊息,不過深入探索這些問題也是幫助我們設計更好的更高效的深度神經網路的訓練方法。
一. 梯度消失問題
先回到之前的程式上,當我們選擇一個隱藏層的時候得到準確率為96.48%。
接著增加一個隱藏層得到96.90%的結果。
看上去結果不錯,畢竟提升了。接著再加上一個隱藏層,卻只得到了96.57%的結果。這個結果雖說下降了沒多少,
但是我們模型變複雜了,我們期望得到一個更好的結果,但是卻事與願違了。
這個結果看上去是奇怪的,而外的隱藏層理應使得模型可以處理更復雜的分類函式,不說結果提升多少,但是至少不能下降吧。為了搞清楚這期間到底是出了什麼問題,我們回到兩個隱藏層的情況,下面的圖中,神經元上的柱形的長度表現的是其引數的更新速率,是當引數初始化完成後得到的結果:
大致看上去,
第二層整體的更新速率要比第一層的快很多
。但是由於權重的初始化也是隨機的,我們很難判斷這是不是一種巧合。
為了驗證這是巧合還是事實,我們先定義,
然後可以看作是一個向量,其中每個分量表示第層中該神經元上引數更新的速率。
於是就可以將看作是層整體的學習速率,利用該速率的大小就可以比較不同層學習速率間的差別。
根據這些定義,我們發現和,這的確印證了一開始觀察到的結果,第二層整體比第一層快。
三層隱藏層的時候呢?結果為0.012, 0.060和0.283,也是一樣的結果:
後面的層比前面的層快。四層的時候為0.003,0.017,0.070和0.285,也是一樣。
我們已經驗證了引數剛初始完時的情形,也就是訓練剛剛開始的情形,那麼隨著訓練的進行,它們之間速率會發生什麼變化呢?
先看兩層的情形:
也是一樣的結果,速率都是前面的層要慢於後面的層。
我們於是可以得到一個重要的觀察現象:
在某些神經網路中,通過隱藏層從後向前看,梯度會變的越來越小。這也意味著,前面層的學習會顯著慢於後面層的學習。這就是梯度消失問題。
那麼是什麼導致了梯度消失呢?是否可以避免這樣的問題呢?事實上,的確存在替代方案,
但是會導致另外一個問題:前面層的梯度會變的很大而不是消失。
這就是梯度爆炸問題。
也就是說深度神經網路上的梯度要麼傾向於爆炸要麼傾向於消失,這都是不穩定的。
而這個不穩定性也是基於梯度的學習演算法都要面臨的一個基本問題。
不過我們也許會有疑問,為什麼梯度消失就是問題,梯度是不是說明學習已經夠了,這個神經元的引數已經被正確學習到了呢?
事實當然不是這樣的,我們一開始初始化產生的引數肯定不可能那麼巧合是最優的引數。
前層的學習速率慢,證明已經到了最優引數?no因為最開始的初始化肯定不能是最好的引數啊)
然而從三層隱藏層的那個例子看到,隨機初始化意味著第一層會錯過很多的重要資訊(會錯過好多資訊),
即使後面的層訓練的再好(前面和後面試分開的?)
,也很難識別輸入影象。(前面的層次無法識別輸入的影象)
並不是第一層已經訓練好了,而是它們無法得到足夠的訓練。
如果我們想要訓練這樣的神經網路,就必須解決梯度消失問題。
二. 是什麼導致了梯度消失問題?
看一個簡單的例子,一個每層只有一個神經元的神經網路:
不過注意到這裡的其實表示的是損失函式,其輸出分別為:。
根據求導的鏈式法則有:
為什麼會發生梯度消失:
其實看到這樣一個式子:
如果還記得前面章節神經元saturated發生的原因的話也能知道這裡究竟是什麼導致了梯度消失。
注意到其間有一系列的項,先看一下sigmoid函式的導數影象:
最大值也才0.25,然後由於引數的初始化使用的高斯分佈,常常會導致,這樣就會導致。然後一系列這些小值的積也會變得更小。
當然這並不是一個嚴格的數學證明,我們很容易就會舉出很多反例。
比如在訓練過程中權重是可能變大的,如果大到使得不再滿足,
或者說大於1,梯度就不會消失了,
它將指數增長,從而導致另外一個問題:
梯度爆炸問題。
梯度爆炸問題:
再來看一個梯度爆炸發生的例子。
我們選擇大的權重:
然後選擇偏差使得不太小。
這個並不難做到,例如我們可以選擇使得時的bias,於是得到,這樣就會導致梯度爆炸了。
梯度的不穩定性問題:
經過這些討論我們就會發現,梯度消失也好,梯度爆炸也好,歸根結底是由於層數的增加,多個項相乘,勢必就會導致不穩定的情況。
除非這些積能恰到好處的相等,才可以讓不同層之間的學習速率相近。不過實際上,這幾乎是不可能發生的。總之,只要我們使用基於梯度的學習演算法,不同層的學習速率勢必是有很大差距的。
練習:
問題:
之前我們基於的事實討論了梯度消失的問題,那麼是否可以使用另外一個啟用函式,使得其導數足夠大,來幫助我們解決梯度不穩定的問題呢?
答案:
這個當然是不可以的,不管一開始的值是怎麼樣的,因為多個項相乘,這就會導致積是指數增長或者指數下降,可能淺層時不明顯,但是隨著層數的增加,都會導致這個問題出現。
梯度消失問題很難消除的原因:
之前已經發現了在深層網路的前幾層會出現梯度或者消失或者爆炸的問題。
事實上,當使用sigmoid函式作為啟用函式的時候,梯度消失幾乎是總會出現的。
考慮到避免梯度消失
,要滿足條件。
我們也許會覺得這還不簡單,只要大不就可以了,但是注意到大,也會導致也大,然後就會很小。唯一的方法就是還需要保證只出現在一個很小的範圍內,這在實際情況下顯然是很難發生的。所以說就總是會導致梯度消失的問題。
拓展:
拓展一:
考慮,假設
(1) 證明這隻可能在時成立
之前已經知道在0處取最大值0.25,所以成立的話勢必需要 。
(2)假設,考慮到,證明此時的的變化區間被限制在寬度 內
這個就是純數學問題解方程了,利用一元二次方程的求根公式可以求得和,然後求對數後相減,稍微變換一下形式就可以得到這個結果。
(3)證明上面的範圍的最大值大約為0.45,在處得到。於是可以看到即使所有這些條件都滿足,啟用函式的符合要求的輸入範圍還是非常窄,還是很難避免梯度消失的問題。
求導算導數為0的點求得。
拓展二:identity神經元
考慮一個單輸入的神經元,中間層引數為和,然後輸出層引數為,證明通過選擇適當的權重和偏差,可以使得對任意成立。這個神經元可以被認為是一種identity神經元,其輸出和輸入一樣(只差一個權重因子的放縮)。提示:可以將寫為, 假設很小,使用處的泰勒展開。
之前討論sigmoid函式形狀的時候知道,當增大的時候,函式會變得越來越窄,逼近解約函式。當非常小的時候,函式越來越寬,在某個區間內會逼近線性函式,但是既然是sigmoid函式,當時,函式都是會趨向於1或0的。
這裡的證明我沒有用泰勒展開,我想的是既然要證明該函式在某個區間的線性,只要證明它導數在該區間趨近於常數即可。
求的導數為。
不妨令則上式變為:
,由於, 而是很小的數,於是可將上式展開為為常數,通過適當調整就可以使其輸出恰好為。
三. 複雜神經網路中的梯度不穩定問題

Deep Residual Learning
(2)初始化:
我們設深度網路中某隱含層為
H(x)-x→F(x),
如果可以假設多個非線性層組合可以近似於一個複雜函式
,那麼也同樣可以
假設
隱含層的殘差
近似於某個複雜函式[6]
。即那麼我們可以將隱含層表示為H(x)=F(x)+ x。
這樣一來,我們就可以得到一種全新的殘差結構單元
,如圖3所示。可以看到,
殘差單元的輸出
由多個卷積層級聯的
輸出和輸入元素間相加(保證卷積層輸出和輸入元素維度相同),
再經過ReLU啟用後得到。
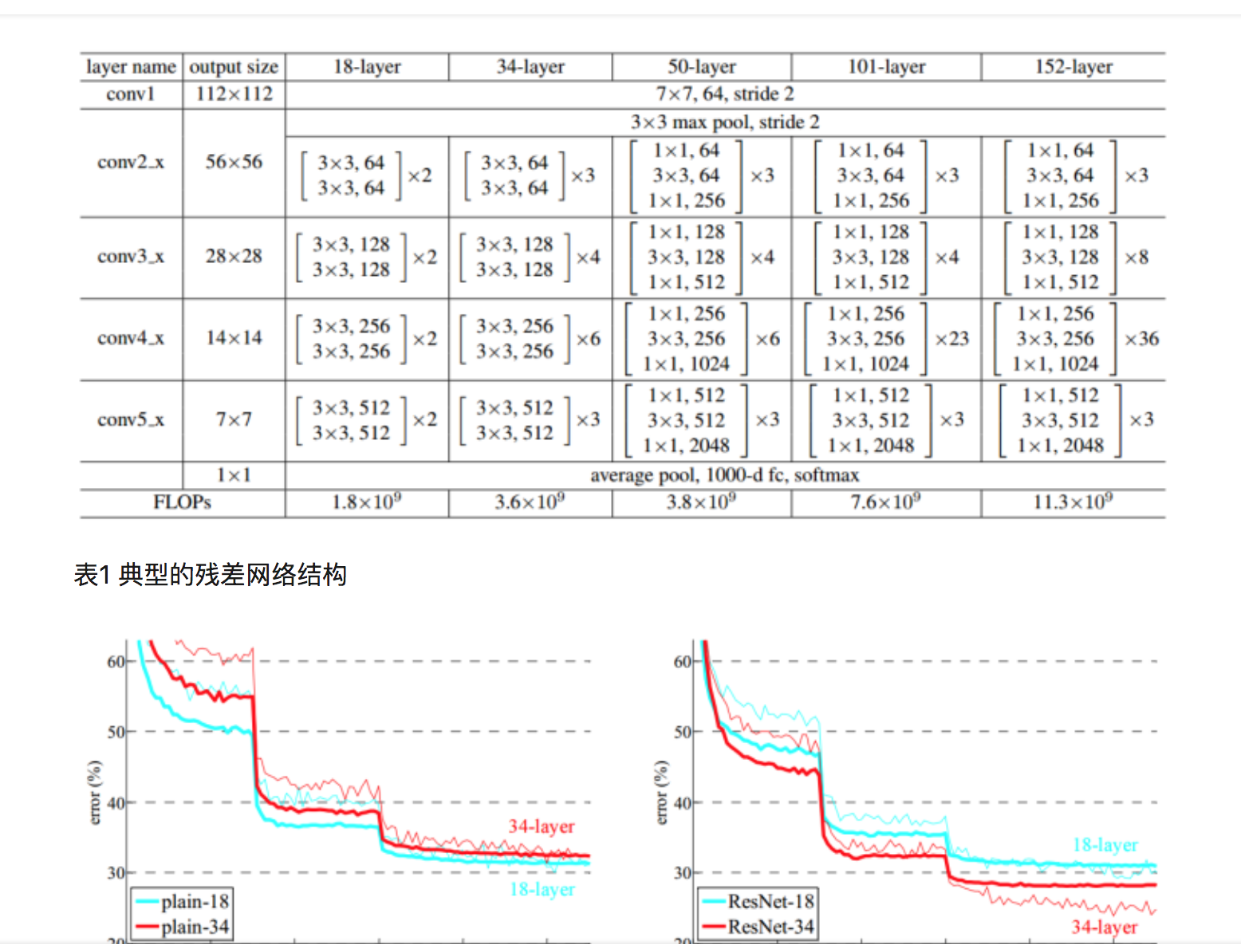
將這種結構級聯起來,就得到了殘差網路。典型網路結構表1所示。
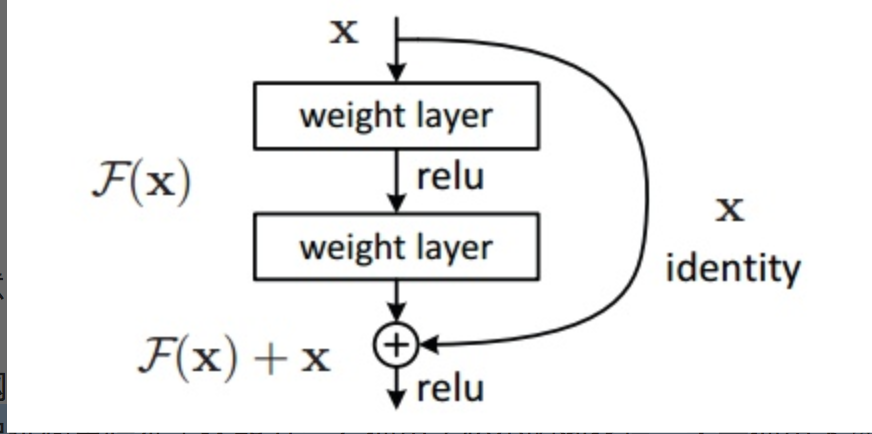
圖3 殘差單元示意圖
可以注意到殘差網路有這樣幾個特點:
1. 網路較瘦,控制了引數數量;
2. 存在明顯層級,特徵圖個數逐層遞進,保證輸出特徵表達能力
3. 使用了較少的池化層,大量使用下采樣,提高傳播效率;
4. 沒有使用Dropout,利用BN和全域性平均池化進行正則化,加快了訓練速度;
5. 層數較高時減少了3x3卷積個數,並用1x1卷積控制了3x3卷積的輸入輸出特徵圖數量,稱這種結構為“瓶頸”(bottleneck)。
網路響應:圖7中可以看出,
殘差網路中大部分層的響應方差都處在較低水平,
這一定程度上印證了我們的假設:
這些響應方差較低的層響應較為固定,
很有可能權重近似於零,
這也就是說
其所對應的殘差結構可能近似於單位對映,
網路的實際有效層數是要比全部層數要少一些的
,產生了跳過連線(Skip-connection)的作用。
這樣也就是網路為什麼在較深的深度下仍可以保持並提升效能,
且沒有過多增加訓練難度的原因。
ResDeeper more
何愷明等人基於深度殘差結構,進一步設計了一些其他的殘差網路模型,用於Cifar-10資料集上的分類任務,分類錯誤率如圖8所示。可以看到,110層以下的殘差網路中均表現出了較強的分類效能。但在使用1202層殘差網路模型時,分類效能出現了退化,甚至不如32層殘差網路的表現。由於Cifar-10資料集尺寸和規模相對較小,此處1202層模型也並未使用Dropout等強正則化手段,1202層的網路有可能已經產生過擬合,但也不能排除和之前“平整”網路情況類似的原因導致的效能退化。
圖8 Cifar-10資料集上殘差網路和其他網路分類測試錯誤率對比
何愷明等人經過一段時間的研究,認為極其深的深度網路可能深受梯度消失問題的困擾,BN、ReLU等手段對於這種程度的梯度消失緩解能力有限,並提出了
單位對映的殘差結構[7]。
這種結構從本源上杜絕了梯度消失的問題:
基於反向傳播法計算梯度優化的神經網路,
由於反向傳播求隱藏層梯度時利用了鏈式法則,
梯度值會進行一系列的連乘,導致淺層隱藏層的梯度會出現劇烈的衰減,這也就是梯度消失問題的本源,這種問題對於Sigmoid啟用尤為嚴重,故後來深度網路均使用ReLU啟用來緩解這個問題,但即使是ReLU啟用也無法避免由於網路單元本身輸出的尺度關係,在極深度條件下成百上千次的連乘帶來的梯度消失。