
殘差網路的理解
網路深度是影響深度卷積神經網路效能的一大因素,但是研究者發現當網路不斷加深時,訓練的結果並不好。這不是因為過擬合,因為過擬合的話應該是訓練集上結果好,測試集不好,但深度網路出現的現象是訓練集上的效果就不好。而且這種現象還會隨著深度加深而變差。這並不符合邏輯,因為深層網路在訓練時,可以是在淺層網路的函式上加上一個恆等變換。而深層網路顯然沒有把這種恆等變換學習到。因此,提出了Resnet。
網路結構是有好多個block組成,每個block的構成如下圖,加入了一個shortcut connections 從函式上來看就是加入了一個恆等變換。
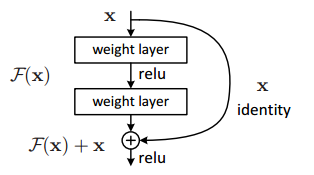 從正向傳播上來看,引入恆等變換可以使網路引數調整作用更大。這個地方引用下知乎上一個特別好的回答(
從正向傳播上來看,引入恆等變換可以使網路引數調整作用更大。這個地方引用下知乎上一個特別好的回答(
在統計和最優引數選取時,統計誤差以及殘差是兩個緊密相關,但同時又極易混淆的概念.兩者都是對"樣本值偏離均值"的測量. 樣本誤差是指樣本對母本(無法觀察到的)均值及真實值的均值的偏離. 殘差則是指樣本和觀察值(樣本總體)或迴歸值(擬合)的差額. 擬合值是統計模型的擬合結果,是依據擬合模型得出的,應該是的值; 誤差和殘差的差異distinction在迴歸中尤其重要, 精細的殘差即通常所說的學生化殘差…(後一句不理解) 簡單理解為: 誤差:即觀測值與真實值的偏離; 殘差:觀測值與擬合值的偏離.
誤差與殘差,這兩個概念在某程度上具有很大的相似性,都是衡量不確定性的指標,可是兩者又存在區別。 誤差與測量有關,誤差大小可以衡量測量的準確性,誤差越大則表示測量越不準確。
誤差分為兩類:系統誤差與隨機誤差。其中,系統誤差與測量方案有關,通過改進測量方案可以避免系統誤差。隨機誤差與觀測者,測量工具,被觀測物體的性質有關,只能儘量減小,卻不能避免。 殘差――與預測有關,殘差大小可以衡量預測的準確性。殘差越大表示預測越不準確。殘差與資料本身的分佈特性,迴歸方程的選擇有關。 誤差: 所有不同樣本集的均值的均值,與真實總體均值的偏離.由於真實總體均值通常無法獲取或觀測到,因此通常是假設總體為某一分佈型別,則有N個估算的均值; 表徵的是觀測/測量的精確度; 誤差大,由異常值引起.表明資料可能有嚴重的測量錯誤;或者所選模型不合適,; 殘差: 某樣本的均值與所有樣本集均值的均值, 的偏離; 表徵取樣的合理性,即該樣本是否具代表意義; 殘差大,表明樣本不具代表性,也有可能由特徵值引起. 反正要看一個模型是否合適,看誤差;要看所取樣本是否合適,看殘差;