
svm原理詳細推導
筆者在查閱了大量資料和閱讀大佬的講解之後,終於對svm有了比較深一點的認識,先將理解的推導過程分享如下:
本文主要從如下五個方面進行介紹:基本推導,鬆弛因子,核函式,SMO演算法,小結五個方面以%%為分隔,同時有些地方需要解釋或者注意一下即在畫有---------符號的部分內。
本文主要介紹的是理論,並沒有涉及到程式碼,關於程式碼的具體實現,可以在閱讀完本文,掌握了SVM演算法的核心內容後去看一下筆者另一篇SVM程式碼剖析:
https://blog.csdn.net/weixin_42001089/article/details/83420109
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
基本推導
svm原理並不難理解,其可以歸結為一句話,就是最大化離超平面最近點(支援向量)到該平面的距離。
如下圖
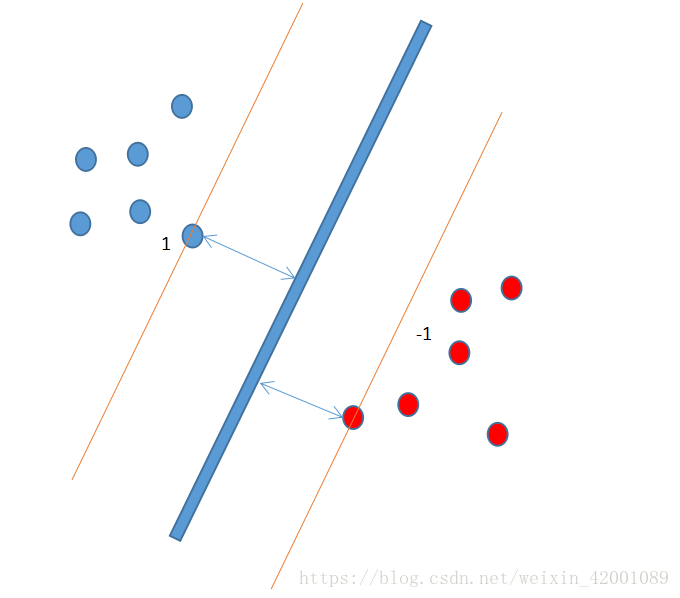
開門見山就是下面的最值優化問題:
注意
(1)這裡的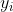 就是標籤假設這裡是二分類問題,其值是1和-1,其保證了不論樣本屬於哪一類
就是標籤假設這裡是二分類問題,其值是1和-1,其保證了不論樣本屬於哪一類 都是大於0的
都是大於0的
(2)稱為函式距離, 稱為幾何距離,這裡之所以要使用幾何距離是因為,當
稱為幾何距離,這裡之所以要使用幾何距離是因為,當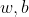 成倍增加時,函式距離也會相應的成倍的增加,而幾何函式則不會
成倍增加時,函式距離也會相應的成倍的增加,而幾何函式則不會
這裡涉及到求兩個最值問題,比較棘手,正如上面所說,幾何距離不受成倍增加的影響,這裡不妨就將最近點到超平面的函式距離設為1,自然其他非最近點的函式距離便是大於1,於是以上問題轉化為:
這是一個在有不等式約束下,最小值優化的問題,這裡可以使用kkt條件
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
這裡簡單介紹一下kkt和拉格朗日乘子法(一般是用來求解最小值的優化問題的)
在求優化問題的時候,可以分為有約束和無約束兩種情況。
針對有約束的情況又有兩種情況即約束條件是等式或者是不等式
當是等式的時候:
首先寫出其拉格朗日函式:
需滿足的條件是:
而當約束條件是不等式時,便可以使用kkt條件,其實kkt條件就是拉格朗日乘子法的泛化
同理首先寫出拉格朗日函式:
好了,接著往下走介紹拉格朗日對偶性:
上面問題可以轉化為(稱為原始問題):
為什麼可以轉化呢?這裡是最難理解的:筆者還沒有完全透徹的理解,這裡試著解釋一下吧,也是網上最流行的解釋方法:
這裡分兩種情況進行討論:
當g(x)或者h(x)不滿足約束條件時:
那麼顯然:因為當
時我們可令
,
時我們令
或者
當g(x)或者h(x)滿足約束條件時:
綜上所述:
所以如果考慮極小值問題那麼就可以轉化為:
還有一種比較直觀的方法,這裡不再證明,可以參考:https://www.zhihu.com/question/58584814/answer/159863739第二個回答
對偶問題:
上面關於拉格朗日最小最大值問題可以轉化為求其對偶問題解決:
兩者關係:
假設原始問題的最優解是,其對偶問題的最優解是
,那麼容易得到:
即其對偶問題的解小於等於原始問題的解,現在我們要通過其對偶問題來求的原始問題的解對吧,所以我們希望的是
那麼什麼時候才能相等呢?這就必須滿足的kkt條件:
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
說了這麼多拉格朗日的東西,其實其本質作用就是,將有不等式約束問題轉化為無約束問題(極小極大值問題),然後又進一步在滿足kkt條件下將問題轉化為了其對偶問題,使之更容易求解,下面要用到的就是上面紫色的部分,關於更深的拉格朗日求解問題大家可以去收集資料參看。
對應到SVM的拉格朗日函式便是:
-----------------------------------------------------------------------------------------------------------------------------------------------------------
注意上面給的不等式約束是即小於等於,而這裡的不等式約束是大於等於所以紅色部分是減法
----------------------------------------------------------------------------------------------------------------------------------------------------------
於是問題轉化為:
根據對偶轉化:
好啦,這裡沒什麼說的就是根據kkt條件求偏導令其為0:
於是就得到:
將上述兩公式帶入到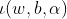 如下:
如下:
於是問題轉化為:
所以最後就得出這樣的步驟:
1首先根據上面的最優化問題求出一些列的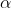
2然後求出w和b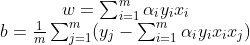
所以當一個樣本進來的時候即值便是:
3根據如下進行分類:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
鬆弛因子
上面是SVM最基本的推導,下面說一下這種情況就是有一個點由於採集錯誤或者其他原因,導致其位置落在了別的離別當中,而svm是找最近的點,所以這時候找出的超平面就會過擬合,解決的辦法就是忽略掉這些點(離群點),即假如鬆弛因子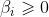 ,使幾何距離不那麼大於1
,使幾何距離不那麼大於1
數學化後的約束條件即變為:
這裡簡單來理解一些C的含義:這是一個在使用SVM時需要調的引數,代表離群點到底離群點有多遠,而C就是我們對這些點的重視程度,假設現在
是一個定值,那麼當C越大,就代表我們越重視這些點,越不想捨棄這些點,即極端的當
時,優化是求min,則無解,即對應的直觀理解就是:這時線性不可分,大家都混在一起,這時又不想捨棄任何一個點,自然就不能找到適合的超平面(當然可以使用核函式進行對映分類,後面說明)
接下來還是使用上面拉格朗日對偶問題進行求解,這裡就不詳細說明了,直接給出過程:
令
求導令其為0:
將其帶入最終問題可得:
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
這裡得到的和沒加鬆弛變數時是一樣的
------------------------------------------------------------------------------------------------------------------------------------------------
對應的kkt條件為:
注意如下幾點:
一:對比最開始的kkt條件模板
這裡的(1)(8)(9)是求偏導的結果即一二三公式,(6)(7)是拉格朗日乘子即相當於模板的第五公式,(2)(4)相當於模板第六個公式,(3)(5)是原始約束條件即相當於模板的第七個公式
二:可以將kkt中部分條件進行總結歸納:(6)(7)(8)三個條件:
所以可以總結為:
可以看到這裡和沒加鬆弛變數相比,唯一不同的就是有了上界C,它代表著我們對那些離群點的重視程度
三:說一下 取不同值時意義
取不同值時意義
對比模板
當時,對應的
即
邊界點
當時,對應的
即
非邊界點
當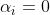 時:
時:
由(8)可得:
又有公式(4)可得:
最後又公式(3)可得:
當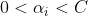 時:
時:
同理
又(2)可得:
最後:
當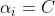 時:
時:
進而這裡還是隻能得到即
最後:
綜上所述可以總結為:
在點在兩條間隔線外則,對應前面的係數為0,在兩條間隔線裡面的對應的係數為C,在兩條間隔線上的點對應的係數在0和C之間。
通過上面也可以看出,最後求出的所有按理說為0的居多,畢竟大部分資料點應該是在間隔線外的對吧。
所以對應到鬆弛遍歷這裡的步驟就是:
1首先根據上面的最優化問題求出一些列的
2然後求出w和b
注意這裡是隨便取一個點i就可以算出b,但是實際中往往取所有點的平均
3得出超平面
注意這裡說一下的意義,由前面基本推導的kkt部分討論可知:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
核函式:
出現的背景:
對於一些線性不可分的情況,比如一些資料混合在一起,我們可以將資料先對映到高緯,然後在使用svm找到當前高緯度的超平面,進而將資料進行有效的分離,一個直觀的例子:
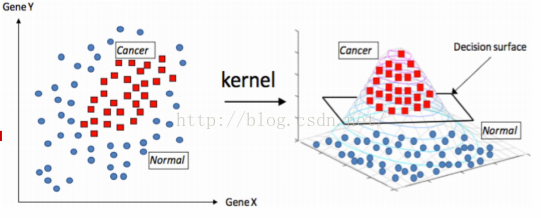
圖片來源七月演算法
比如原來是:
則現在為:
其中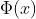 就是對映公式,即先對映到高緯再進行內積
就是對映公式,即先對映到高緯再進行內積
但是問題來了,那就是假設原始資料維度就好高,再進一步對映到高緯,那麼最後的維度可能就非常之高,再進行內積等這一系列計算要求太高,很難計算。
因此我們可以令
這裡的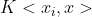 便是核函式,其意義在於我們不用去對映到高緯再內積,而是直接在低緯使用一種核函式計算
便是核函式,其意義在於我們不用去對映到高緯再內積,而是直接在低緯使用一種核函式計算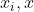 ,使其結果和對映到高緯再內積效果一樣,這就是核函式的威力,大部分是內積,而SVM的奇妙之處就在於所有的運算都可以寫成內積的形式,但是這種核函式具體該怎麼選取呢?別慌,已經有前輩們幫我們找到了很多核函式,我們直接拿過來用就可以啦。
,使其結果和對映到高緯再內積效果一樣,這就是核函式的威力,大部分是內積,而SVM的奇妙之處就在於所有的運算都可以寫成內積的形式,但是這種核函式具體該怎麼選取呢?別慌,已經有前輩們幫我們找到了很多核函式,我們直接拿過來用就可以啦。
下面介紹幾種常見的吧:更多的大家可以自行查閱:
(1)線性核函式 :也是首選的用來測試效果的核函式
其維度與原來相同,主要用於線性可分的情況,其實就是原始匯出的結果
(2)多項式核函式
其實現將低維的輸入空間對映到高緯的特徵空間,但多項式的階數也不能太高,否則核矩陣的元素值將趨於無窮大或者無窮小,計算複雜度同樣會大到無法計算。而且它還有一個缺點就是超引數過多
(3)徑向基高斯(RBF)核函式
高斯(RBF)核函式核函式效能較好,適用於各種規模的資料點,而且引數要少,因此大多數情況下優先使用高斯核函式。
(4)sigmoid核函式
不難看出這裡有點深度學習當中,一個簡單的神經網路層
總的來說就是,當樣本足夠多時,維度也足夠高即本身維度已經滿足線性可分,那麼可以考慮使用線性核函式,當樣本足夠多但是維度不高時,可以考慮認為的增加一定的維度,再使用線性核函式,當樣本也不多,維度也不高時,這時候可以考慮使用高斯(RBF)核函式。
關於SVM ,python中有一個機器學習庫sklearn,其中集成了很多機器學習方法,包括SVM,筆者這裡也做過一個簡單直觀的呼叫,可以參看https://blog.csdn.net/weixin_42001089/article/details/79952399
再者就是我們雖然可以直接拿sklearn庫下整合好的介面來用,但是其具體實現細節,還是有必要了解一下,換句話說:
上面我們最後得到的結果是:
我們求出一些列便可,可是
具體怎麼求呢?落實到程式碼上面應該怎麼搞呢?下面就來說說這個事情
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
SMO演算法
現在的問題是:
首先要明確我們的目的是求一些列的,其思路也是很簡單就是固定一個引數即以此為自變數,然後將其他的變數看成常數,只不過因為這裡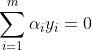 約束條件,所以我們一次取出兩個作為自變數進行優化,然後外面就是一個大的迴圈,不停的取不停的優化,知道達到某個條件(後面介紹)停止優化。
約束條件,所以我們一次取出兩個作為自變數進行優化,然後外面就是一個大的迴圈,不停的取不停的優化,知道達到某個條件(後面介紹)停止優化。
思路框架就是上面這麼簡單,下面來看一下理論方面的精確推導:
假設我們首先取出了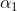 和
和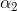 ,那麼後面的便可以整體視為一個常數即:
,那麼後面的便可以整體視為一個常數即:
先將用表示出來,也很簡單:
帶入到原始優化的目標方程中可得:
即關於的一元二次方程(其中a,b,c都是常數)
--------------------------------------------------------------------------------------------------------------------------------------------------------------
為什麼是二元一次方程呢?很簡單由原始優化目標可以看出基本單元就是,然後就是組合相加,所以最高次數就是2次,前面還有單次項,後面有常數項,所以最後歸結起來就是一個一元二次方程
-------------------------------------------------------------------------------------------------------------------------------------------------------------
好啦,求一元二次方程最值應該很簡單啦吧,即:
相應的根據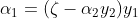 便可以求出
便可以求出
這樣就完成啦一對值的優化,接著找下一對值就行優化即可
-------------------------------------------------------------------------------------------------------------------------------------------------------------
介紹到這裡也許會發現還有一個約束條件沒有用即:
是的我們在算的時候,最後還應該加一步就是將其值約束到[0,C]
回到:
我們分類討論:
(1)當和
是同號時:
則是一個斜率為-1的直線即
那麼可以畫出如下圖。橫座標是,縱座標是
,可以看到直線有如下兩種情況

現在要保證範圍,即的最大值在兩種情況下分別是
和C,最小值分別是
和
所以最後綜合一下即
(2)噹噹和
是異號時:
則是一個斜率為1的直線即
那麼可以畫出如下圖。橫座標是,縱座標是
,可以看到直線有如下兩種情況

現在要保證範圍,即的最大值在兩種情況下分別是
和C,最小值分別是
和
所以最後綜合一下即
所以在我們通過一元二次方程求得的並不是最終的
而是經過以下:
注意這裡有時候L=H這代表都在邊界(值等於0或者C)則不用對這一對
進行優化啦,因為他們已經在邊界啦,因此不再能夠減少或者增大(其值太大會被強行賦值為H,同理太小為L),因此也就不值得再對他們進行優化啦,直接跳過尋找下一對需要優化的
對即可
--------------------------------------------------------------------------------------------------------------------------------------------------------------
好的我們接著往下走,剛才說得到一個一元二次方程組那麼係數a,b,c是多少呢?我們來求一下:
我們先將和帶入:
公式太多就不用編輯器啦,字跡有點潦草==

現在我們進一步化簡一下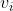 :
:

我們將本次要優化的引數標為*即規範一下就是:
