
CS229 6.6 Neurons Networks PCA主成分分析
主成分分析(PCA)是一種經典的降維演算法,基於基變換,資料原來位於標準座標基下,將其投影到前k個最大特徵值對應的特徵向量所組成的基上,使得資料在新基各個維度有最大的方差,且在新基的各個維度上資料是不相關的,PCA有幾個關鍵的點:
1)歸一化均值與方差,均值歸一化後便於計算,方差歸一化後便於對各個維度進行比較
2)新基為正交基,即各個座標軸是相互獨立的(可理解為垂直),只需要取新基上取方差最大的前幾個維度即可
3)PCA的前提是隻對服從高斯分佈的資料特徵提取效果較好,這就大大限制了它的應用範圍。如果資料呈任意分佈,那麼不論在原始空間中如何做正交變換,都不可能找到一組最優的特徵方向,找到所謂的“主分量”也就不能表達資料的特徵結構了(比如說資料呈現正方形)。
引入
假設有一條淘寶物品記錄,格式如下:
( 瀏覽量, 訪客數, 下單數, 成交數, 成交金額)
這五個屬性可以代表五個維度,分別對應座標系中的五個座標軸(基),給定在這組基上的一組樣本點:
(500,240,25,13,2312.15)T
可以看到這就是一條物品的記錄,五個維度的計算並不複雜,但當處理的資料的維度上萬,甚至十萬、百萬時,(比如1000*1000的圖片)這種情況下會帶來非常大的計算量,所以有必要對資料進行降維。降維意味著資訊的丟失,比如對於以上資料,去掉下成交金額這一個維度,將丟失很多關於物品的資訊,所以PCA只能儘量避免資訊的丟失。
相關性:維度教高的資料在某幾個維度間兩輛一般會存在一些相關性,比如如上的瀏覽量與訪客數往往成正比關係,這種情況下去掉其中一個維度,往往不會丟失太多資訊。以上給出的只是直觀的描述,我們到底刪除哪一列損失的資訊才最小?亦或根本不是單純刪除幾列,而是通過某些變換將原始資料變為更少的列但又使得丟失的資訊最小?到底如何度量丟失資訊的多少?如何根據原始資料決定具體的降維操作步驟?
線性代數基礎
下面先來看一個高中就學過的向量運算:內積。兩個維數相同的向量的內積被定義為:

內積運算會將向量對映為實數,下面看內積的幾何意義,二維向量A,B,其中A=(x1,y1),B=(x2,y2),

現在從A點向B所在直線引一條垂線。這條垂線與B的交點叫做A在B上的投影,再設A與B的夾角是a,則投影的向量長度為 ,其中
,其中![]() ,是線段A的長度
,是線段A的長度
把內積表示為一種熟悉的形式有:

A與B的內積等於A到B的投影長度乘以B的模。再進一步,如果我們假設B的模為1,即讓|B|=1,那麼就變成了:

也就是說,設向量B的模為1,則A與B的內積值等於A向B所在直線投影的向量長度
再來看基的概念,我們對二維平面上的向量(x,y)非常熟悉,如以上的A、B就是兩個向量,仔細看就知道(x,y)分別表示在x軸上的投影為x,在y週上的投影為y。也就是說這裡有一個隱含定義,現在分別取x軸正向、y軸正向一個模為1的向量,向量(x,y)分別在x軸投影為x,在y軸投影為y,注意投影也為向量。準確的表示為向量x,y的線性組合:

此時(1,0)T與(0,1)T可以稱作向量的一組基。

所以要準確描述向量,首先要給定一組基,然後給向量在基的各個直線上的投影即可。標準座標系下經常忽略第一步以(1,0)和(0,1)為基。
例如,(1,1)和(-1,1)也可以成為一組基。一般來說,我們希望基的模是1,因為從內積的意義可以看到,如果基的模是1,那麼就可以方便的用向量點乘基而直接獲得其在新基上的座標了!實際上,對應任何一個向量我們總可以找到其同方向上模為1的向量,只要讓兩個分量分別除以模就好了。上面的基就可以變為
現在,我們想獲得(3,2)在新基上的座標,即在兩個方向上的投影向量值,那麼根據內積的幾何意義,我們只要分別計算(3,2)和兩個基的內積,可以得到新基的座標為: ,下圖給出點(3,2)在新基的圖:
,下圖給出點(3,2)在新基的圖:

另外這裡要注意的是,例子中的基都是正交的(即內積為0,或直觀說相互垂直),但可以成為一組基的唯一要求就是線性無關,非正交的基也是可以的。不過因為正交基有較好的性質,所以一般使用的基都是正交的。
下面我們找一種簡便的方式來表示基變換。還是拿上面的例子,想一下,將(3,2)變換為新基上的座標,就是用(3,2)與第一個基做內積運算,作為第一個新的座標分量,然後用(3,2)與第二個基做內積運算,作為第二個新座標的分量。實際上,我們可以用矩陣相乘的形式簡潔的表示這個變換:

於是一組向量的基變換被幹淨的表示為矩陣的相乘。
一般的,如果我們有M個N維向量,想將其變換為由R個N維向量表示的新空間中,那麼首先將R個基按行組成矩陣A,然後將向量按列組成矩陣B,那麼兩矩陣的乘積AB就是變換結果,其中AB的第m列為A中第m列變換後的結果。

特別要注意的是,這裡R可以小於N,而R決定了變換後資料的維數。也就是說,我們可以將一N維資料變換到更低維度的空間中去,變換後的維度取決於基的數量。因此這種矩陣相乘的表示也可以表示降維變換。
最後,上述分析同時給矩陣相乘找到了一種物理解釋:兩個矩陣相乘的意義是將右邊矩陣中的每一列列向量變換到左邊矩陣中每一行行向量為基所表示的空間中去。更抽象的說,一個矩陣可以表示一種線性變換。很多同學在學線性代數時對矩陣相乘的方法感到奇怪,但是如果明白了矩陣相乘的物理意義,其合理性就一目瞭然了。
根據以上的基變換可以看出,如果給定一組新基,其維度小於向量本身的維度,則變換後的資料就是原始資料再新基中的地維表示,降維的目的就達到了,但對於PCA還有一個問題:即如何選取一組合理的基以最大化的保留原始資訊?
先看一個例子,對於五條二維資料:
(1 ,1) (1 ,3) (2, 3) (4 ,4) (2 ,4)
將其表示為矩陣形式:

為了便於處理,把每個維度的的資料都減去對應維度的均值,這樣每個維度均變為0均值。

可以看到,歸一化為0均值後(注意,省略了方差歸一化的步驟,因為資料在兩個維度方差相同),樣本在直角座標系的圖為

要把如上資料降低為1維,如何找到一個新的方向,使得資訊儘可能不丟失呢?直觀的做法是,投影后的點儘量分散,這種分散程度,可以用方差來度量,方差的公式如下:

對於每個維度都變化為0均值後,方差可以表示為:

於是問題轉變為,尋找一組基,使得資料變化到這組基之後,方差最大。
對於n維資料降低到k維時,為了讓兩個維度儘可能多的保留初始資訊,他們之間應該是獨立的,不相關的,因為相關代表兩個維度間存在冗餘資訊,對於均值歸一化為0之後的資料,度量兩個維度的相關性可以用協方差來表示:

當協方差為0時,表示兩個欄位完全獨立。為了讓協方差為0,我們選擇第二個基時只能在與第一個基正交的方向上選擇。因此最終選擇的兩個方向一定是正交的。
至此,我們得到了降維問題的優化目標:將一組N維向量降為K維(K大於0,小於N),其目標是選擇K個單位(模為1)正交基,使得原始資料變換到這組基上後,各欄位兩兩間協方差為0,而欄位的方差則儘可能大(在正交的約束下,取最大的K個方差)。
根據以上推倒,需要將協方差矩陣對角化,使得資料每個維度本身之間有最大的方差,而兩兩維度之間的協方差為0,即盡最大量減少資料的冗餘,假設變化後的資料為Y,協方差矩陣為D,D為一個對角陣,且主對線線元素按大小排列,原始資料X的協方差矩陣為C,D與C的關係如下:

現在事情很明白了!我們要找的P不是別的,而是能讓原始協方差矩陣對角化的P。
換句話說,優化目標變成了尋找一個矩陣P,滿足PCPT是一個對角矩陣,並且對角元素按從大到小依次排列,那麼P的前K行就是要尋找的基,用P的前K行組成的矩陣乘以X就使得X從N維降到了K維並滿足上述優化條件。
由上文知道,協方差矩陣C是一個是對稱矩陣,線上性代數上,實對稱矩陣有一系列非常好的性質:
1)實對稱矩陣不同特徵值對應的特徵向量必然正交。
2)設特徵向量λλ重數為r,則必然存在r個線性無關的特徵向量對應於λ,因此可以將這r個特徵向量單位正交化。

其中Λ為對角矩陣,其對角元素為各特徵向量對應的特徵值(可能有重複)。
到這裡,我們發現我們已經找到了需要的矩陣P:

P是協方差矩陣的特徵向量單位化後按行排列出的矩陣,其中每一行都是C的一個特徵向量。如果設P按照ΛΛ中特徵值的從大到小,將特徵向量從上到下排列,則用P的前K行組成的矩陣乘以原始資料矩陣X,就得到了我們需要的降維後的資料矩陣Y。
假設現在輸入資料集表示為 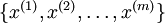 ,維度
,維度 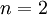 即
即 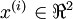 。假設我們想把資料從2維降到1維。(在實際應用中,我們也許需要把資料從256維降到50維;在這裡使用低維資料,主要是為了更好地視覺化演算法的行為)。下圖為資料集:
。假設我們想把資料從2維降到1維。(在實際應用中,我們也許需要把資料從256維降到50維;在這裡使用低維資料,主要是為了更好地視覺化演算法的行為)。下圖為資料集:

這些資料已經進行了預處理,使得每個特徵 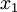 和
和 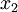 具有相同的均值(零)和方差。預處理的方式如下:
具有相同的均值(零)和方差。預處理的方式如下:
![clip_image017[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110465879.png "clip_image017[4]")
注意:這裡1,2步是把資料各個維度的均值歸一到0,而3,4步是把資料的方差歸一為單位方差,這樣各個維度間即可進行合理比較,否則資料各個維度規模不一致會導致方差的規模不一致(對於一些資料比如灰度影象,其在各個維度上的取值均為0-255之間的數值,所以對其進行方差歸一化沒有必要的,可以省略3,4步),為了使資料方差最大化,且降低資料之間的相關性,根據之前的分析,可以得到以下兩個方向,根據圖中顯示,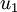 是資料變化的主方向,而
是資料變化的主方向,而 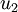 是次方向。
是次方向。

也就是說,資料在 方向上的變化要比在 方向上大。為更形式化地找出方向 和 ,首先計算出矩陣 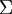 ,如下所示:
,如下所示:
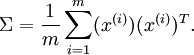
假設資料為三維,其協方差矩陣 為:
![clip_image003[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110404031.png "clip_image003[4]")
注意協方差矩陣的計算,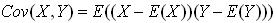 ,對於均值歸一化後,直接在對應維度上相乘即可,先計算出協方差矩陣的特徵向量,按列排放,而組成矩陣
,對於均值歸一化後,直接在對應維度上相乘即可,先計算出協方差矩陣的特徵向量,按列排放,而組成矩陣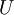 :
:
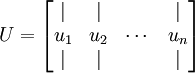
在本例中,向量 和 構成了一個新基,可以用來表示資料。令 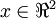 為訓練樣本,那麼
為訓練樣本,那麼 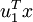 就是樣本點
就是樣本點  在維度 上的投影的長度(幅值)。同樣的,
在維度 上的投影的長度(幅值)。同樣的, 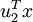 是 投影到 維度上的長度(幅值)。
是 投影到 維度上的長度(幅值)。
至此,我們可以把 用 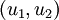 基表達為:
基表達為:
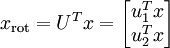
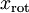 即為在新基下的座標,在新基上,資料的方差可以表示為:
即為在新基下的座標,在新基上,資料的方差可以表示為:
對資料集中的每個樣本  分別進行旋轉:
分別進行旋轉: 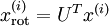 for every ,然後把變換後的資料 顯示在座標圖上,可得:
for every ,然後把變換後的資料 顯示在座標圖上,可得:

這就是把訓練資料集旋轉到 , 基後的結果。一般而言,運算 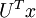 表示旋轉到基 ,, ...,
表示旋轉到基 ,, ...,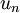 之上的訓練資料。矩陣 有正交性,即滿足
之上的訓練資料。矩陣 有正交性,即滿足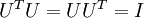 ,所以若想將旋轉後的向量 還原為原始資料 ,將其左乘矩陣即可:
,所以若想將旋轉後的向量 還原為原始資料 ,將其左乘矩陣即可: 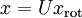 , 驗算一下:
, 驗算一下: 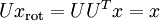 .
.
資料的主方向就是旋轉資料的第一維 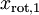 。因此,若想把這資料降到一維,可令:
。因此,若想把這資料降到一維,可令:
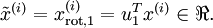
更一般的,假如想把資料 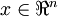 降到
降到  維表示
維表示 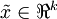 (令
(令 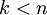 ),只需選取 的前 個成分,分別對應前 個數據變化的主方向。
),只需選取 的前 個成分,分別對應前 個數據變化的主方向。
PCA的另外一種解釋是: 是一個 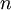 維向量,其中前幾個成分可能比較大(例如,上例中大部分樣本第一個成分
維向量,其中前幾個成分可能比較大(例如,上例中大部分樣本第一個成分 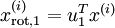 的取值相對較大),而後面成分可能會比較小(例如,上例中大部分樣本的
的取值相對較大),而後面成分可能會比較小(例如,上例中大部分樣本的 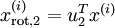 較小)。
較小)。
PCA演算法做的其實就是丟棄 中後面(取值較小)的成分,就是將這些成分的值近似為零。具體的說,設 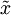 是
是 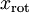 的近似表示,那麼將 除了前 個成分外,其餘全賦值為零,就得到:(這裡 與 分別表示樣本向量)
的近似表示,那麼將 除了前 個成分外,其餘全賦值為零,就得到:(這裡 與 分別表示樣本向量)
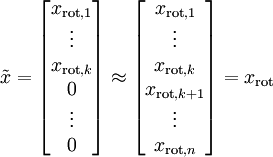
在本例中,可得 的點圖如下(取 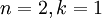 ):
):

然而,由於上面 的後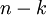 項均為零,沒必要把這些零項保留下來。所以,我們僅用前 個(非零)成分來定義 維向量 。
項均為零,沒必要把這些零項保留下來。所以,我們僅用前 個(非零)成分來定義 維向量 。
這也解釋了為什麼以 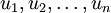 為基來表示資料:要決定保留哪些成分變得很簡單,只需取前 個成分即可。得到了原始資料 的低維“壓縮”表徵量 , 反過來,如果給定 ,應如何還原原始資料 呢? 的基為要轉換回來,只需 即可。把 看作將 的最後 個元素被置0所得的近似表示,給定 ,可以通過在其末尾新增 個0來得到對
為基來表示資料:要決定保留哪些成分變得很簡單,只需取前 個成分即可。得到了原始資料 的低維“壓縮”表徵量 , 反過來,如果給定 ,應如何還原原始資料 呢? 的基為要轉換回來,只需 即可。把 看作將 的最後 個元素被置0所得的近似表示,給定 ,可以通過在其末尾新增 個0來得到對 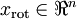 的近似,最後,左乘 便可近似還原出原資料 。計算如下:
的近似,最後,左乘 便可近似還原出原資料 。計算如下:
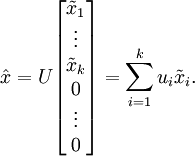
如下即為重構為原來基座標下的點:

在PCA中有一個問題是主成分數K的選取,K的取值過大資料壓縮效率不高,K的取值過小,資料資訊丟失就會嚴重。決定K值得選取通常會考慮k的方差百分比,如果 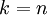 ,那麼我們得到的是對資料的完美近似,也就是保留了100%的方差,即原始資料的所有變化都被保留下來;相反,如果
,那麼我們得到的是對資料的完美近似,也就是保留了100%的方差,即原始資料的所有變化都被保留下來;相反,如果 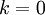 ,那等於是使用零向量來逼近輸入資料,也就是隻有0%的方差被保留下來。
,那等於是使用零向量來逼近輸入資料,也就是隻有0%的方差被保留下來。
一般而言,設 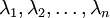 表示 的特徵值(按由大到小順序排列),使得
表示 的特徵值(按由大到小順序排列),使得 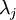 為對應於特徵向量
為對應於特徵向量 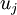 的特徵值。即 投影后第j個維度的方差。保留前 個成分,則保留的方差百分比可計算為:
的特徵值。即 投影后第j個維度的方差。保留前 個成分,則保留的方差百分比可計算為:
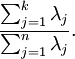
在上面簡單的二維實驗中,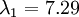 ,
,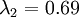 。因此,如果保留
。因此,如果保留 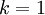 個主成分,等於我們保留了
個主成分,等於我們保留了 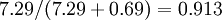 ,即91.3%的方差。
,即91.3%的方差。
容易證明,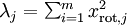 。因此,如果
。因此,如果 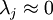 ,則說明
,則說明 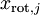 也就基本上接近於0,所以用0來近似它並不會產生多大損失。這也解釋了為什麼要保留前面的主成分(對應的 值較大)而不是末尾的那些。 這些前面的主成分 變化性更大,取值也更大,如果將其設為0勢必引入較大的近似誤差。
也就基本上接近於0,所以用0來近似它並不會產生多大損失。這也解釋了為什麼要保留前面的主成分(對應的 值較大)而不是末尾的那些。 這些前面的主成分 變化性更大,取值也更大,如果將其設為0勢必引入較大的近似誤差。
以處理影象資料為例,一個慣常的經驗法則是選擇 以保留99%的方差,換句話說,我們選取滿足以下條件的最小 值:
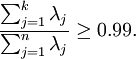
對其它應用,如不介意引入稍大的誤差,有時也保留90-98%的方差範圍。若向他人介紹PCA演算法詳情,告訴他們你選擇的 保留了95%的方差,比告訴他們你保留了前120個(或任意某個數字)主成分更好理解。
協方差矩陣為PCA變換後資料在新基上的方差,取前K個特徵值對應前K維最大的方差方向,且資料在新基的方向為特徵值對應的特徵向量方向:
![clip_image042[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110572804.png "clip_image042[4]")
中間那部分很熟悉啊,不就是樣本特徵的協方差矩陣麼(![]() 的均值為0,一般協方差矩陣都除以m-1,這裡用m)。用
的均值為0,一般協方差矩陣都除以m-1,這裡用m)。用![]() 來表示
來表示![]() ,
,![]() 表示
表示![]() ,那麼上式寫作,
,那麼上式寫作,![]() 。由於u是單位向量,即
。由於u是單位向量,即![]() ,上式兩邊都左乘u得,
,上式兩邊都左乘u得,![]() ,即
,即![]() ,
,![]() 就是
就是![]() 的特徵值,u是特徵向量。最佳的投影直線是特徵值
的特徵值,u是特徵向量。最佳的投影直線是特徵值![]() 最大時對應的特徵向量,其次是
最大時對應的特徵向量,其次是![]() 第二大對應的特徵向量,依次類推。因此,我們只需要對協方差矩陣進行特徵值分解,得到的前k大特徵值對應的特徵向量就是最佳的k維新特徵,而且這k維新特徵是正交的。得到前k個u以後,樣例
第二大對應的特徵向量,依次類推。因此,我們只需要對協方差矩陣進行特徵值分解,得到的前k大特徵值對應的特徵向量就是最佳的k維新特徵,而且這k維新特徵是正交的。得到前k個u以後,樣例![]() 通過以下變換可以得到新的樣本。
通過以下變換可以得到新的樣本。
![clip_image059[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182111054945.png "clip_image059[4]") 其中的第j維就是
其中的第j維就是![]() 在
在![]() 上的投影。
上的投影。
參考:
1) http://blog.codinglabs.org/articles/pca-tutorial.html
2) UFLDL
3) http://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html