
深入淺出ML之Factorization家族
因子分解機
因子分解機(Factorization Machine,簡稱FM),又稱分解機器。是由Konstanz大學(德國康斯坦茨大學)Steffen Rendle(現任職於Google)於2010年最早提出的,旨在解決大規模稀疏資料下的特徵組合問題。在系統介紹FM之前,我們先了解一下在實際應用場景中,稀疏資料是怎樣產生的?
使用者在網站上的行為資料會被Server端以日誌的形式記錄下來,這些資料通常會存放在多臺儲存機器的硬碟上。
以新~浪為例,各產品線紀錄的使用者行為日誌會通過flume等日誌收集工具交給資料中心託管,它們負責把資料定時上傳至HDFS上,或者由資料中心生成Hive表。
我們會發現日誌中大多數出現的特徵是categorical型別的,這種特徵型別的取值僅僅是一個標識,本身並沒有實際意義,更不能用其取值比較大小。比如日誌中記錄了使用者訪問的頻道(channel)資訊,如”news”, “auto”, “finance”等。
假設channel特徵有10個取值,分別為{“auto”,“finance”,“ent”,“news”,“sports”,“mil”,“weather”,“house”,“edu”,“games”}。部分訓練資料如下:
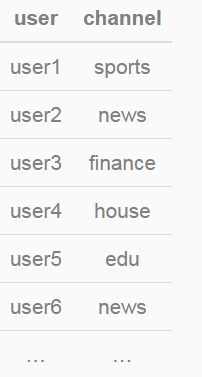
特徵ETL過程中,需要對categorical型特徵進行one-hot編碼(獨熱編碼),即將categorical型特徵轉化為數值型特徵。channel特徵轉化後的結果如下:

可以發現,由one-hot編碼帶來的資料稀疏性會導致特徵空間變大。上面的例子中,一維categorical特徵在經過one-hot編碼後變成了10維數值型特徵。真實應用場景中,未編碼前特徵總維度可能僅有數十維或者到數百維的categorical型特徵,經過one-hot編碼後,達到數千萬、數億甚至更高維度的數值特徵在業內都是常有的。
我組廣告和推薦業務的點選預估系統,編碼前是特徵不到100維,編碼後(包括feature hashing)的維度達百萬維量級。
此外也能發現,特徵空間增長的維度取決於categorical型特徵的取值個數。在資料稀疏性的現實情況下,我們如何去利用這些特徵來提升learning performance?
或許在學習過程中考慮特徵之間的關聯資訊。針對特徵關聯,我們需要討論兩個問題:1. 為什麼要考慮特徵之間的關聯資訊?2. 如何表達特徵之間的關聯?
為什麼要考慮特徵之間的關聯資訊?
大量的研究和實際資料分析結果表明:某些特徵之間的關聯資訊(相關度)對事件結果的的發生會產生很大的影響。從實際業務線的廣告點選資料分析來看,也正式了這樣的結論。
如何表達特徵之間的關聯?
表示特徵之間的關聯,最直接的方法的是構造組合特徵。樣本中特徵之間的關聯資訊在one-hot編碼和淺層學習模型(如LR、SVM)是做不到的。目前工業界主要有兩種手段得到組合特徵:
人工特徵工程(資料分析+人工構造);
通過模型做組合特徵的學習(深度學習方法、FM/FFM方法)
FM模型表達
為了更好的介紹FM模型,我們先從多項式迴歸、交叉組合特徵說起,然後自然地過度到FM模型。
二階多項式迴歸模型
我們先看二階多項式模型的表示式:
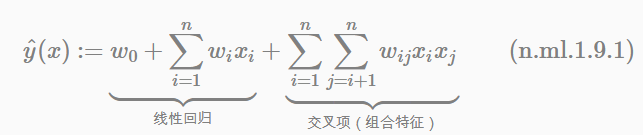
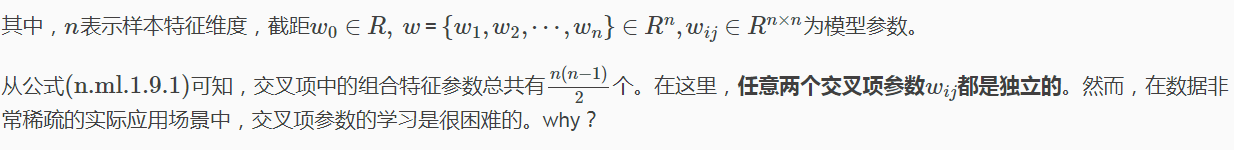
因為我們知道,迴歸模型的引數w的學習結果就是從訓練樣本中計算充分統計量(凡是符合指數族分佈的模型都具有此性質),而在這裡交叉項的每一個引數wij的學習過程需要大量的xi、xj同時非零的訓練樣本資料。由於樣本資料本來就很稀疏,能夠滿足“xi和xj都非零”的樣本數就會更少。訓練樣本不充分,學到的引數wij就不是充分統計量結果,導致引數wij不準確,而這會嚴重影響模型預測的效果(performance)和穩定性。How to do it ?
那麼,如何在降低資料稀疏問題給模型效能帶來的重大影響的同時,有效地解決二階交叉項引數的學習問題呢?矩陣分解方法已經給出瞭解決思路。這裡借用CMU討論課中提到的FM課件和美團-深入FFM原理與實踐中提到的矩陣分解例子。
在基於Model-Based的協同過濾中,一個rating矩陣可以分解為user矩陣和item矩陣,每個user和item都可以採用一個隱向量表示。如下圖所示。


這裡我們只討論二階FM模型(degree=2),其表示式為:

公式解讀:
線性模型+交叉項
直觀地看FM模型表示式,前兩項是線性迴歸模型的表示式,最後一項是二階特徵交叉項(又稱組合特徵項),表示模型將兩個互異的特徵分量之間的關聯資訊考慮進來。用交叉項表示組合特徵,從而建立特徵與結果之間的非線性關係。
交叉項係數 → 隱向量內積

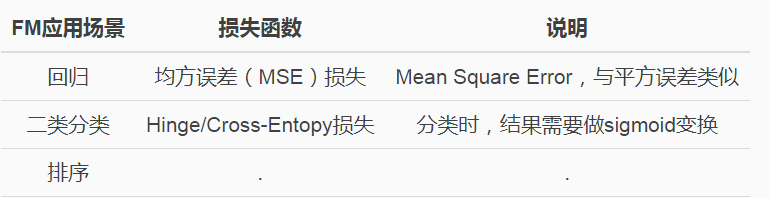
論文中還提到FM模型的應用場景,並且說公式(ml.1.9.1)作為一個通用的擬合模型(Generic Model),可以採用不同的損失函式來解決具體問題。比如:
FM引數學習
等式變換
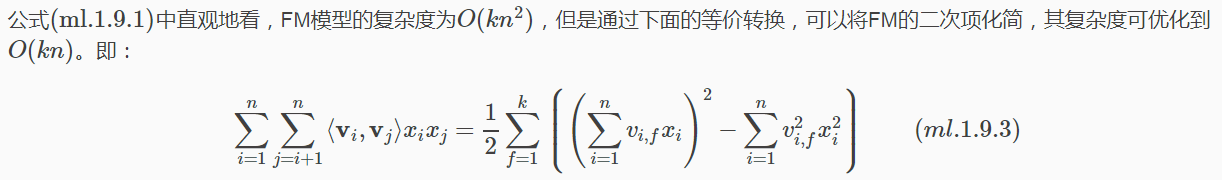
下面給出詳細推導:

解讀第(1)步到第(2)步,這裡用A表示係數矩陣V的上三角元素,B表示對角線上的交叉項係數。由於係數矩陣V是一個對稱陣,所以下三角與上三角相等,有下式成立:
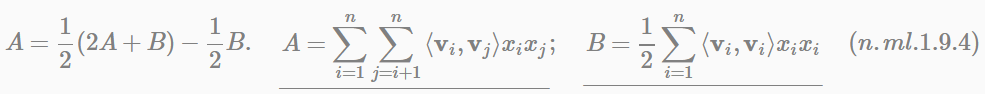
如果用隨機梯度下降(Stochastic Gradient Descent)法學習模型引數。那麼,模型各個引數的梯度如下:

FM訓練複雜度

綜上可知,FM演算法可以線上性時間內完成模型訓練,以及對新樣本做出預測,所以說FM是一個非常高效的模型。
FM總結
上面我們主要是從FM模型引入(多項式開始)、模型表達和引數學習的角度介紹的FM模型,這裡我把我認為FM最核心的精髓和價值總結出來,與大家討論。FM模型的核心作用可以概括為以下3個:
-
FM降低了交叉項引數學習不充分的影響
one-hot編碼後的樣本資料非常稀疏,組合特徵更是如此。為了解決交叉項引數學習不充分、導致模型有偏或不穩定的問題。作者借鑑矩陣分解的思路:每一維特徵用k維的隱向量表示,交叉項的引數wij用對應特徵隱向量的內積表示,即⟨vi,vj⟩(也可以理解為平滑技術)。這樣引數學習由之前學習交叉項引數wij的過程,轉變為學習n個單特徵對應k維隱向量的過程。
很明顯,單特徵引數(k維隱向量vi)的學習要比交叉項引數wij學習得更充分。示例說明:

<女性,汽車>的含義是女性看汽車廣告。可以看到,單特徵對應的樣本數遠大於組合特徵對應的樣本數。訓練時,單特徵引數相比交叉項特徵引數會學習地更充分。
因此,可以說FM降低了因資料稀疏,導致交叉項引數學習不充分的影響。 -
FM提升了模型預估能力
依然看上面的示例,樣本中沒有<男性,化妝品>交叉特徵,即沒有男性看化妝品廣告的資料。如果用多項式模型來建模,對應的交叉項引數w男性,化妝品是學不出來的,因為資料中沒有對應的共現交叉特徵。那麼多項式模型就不能對出現的男性看化妝品廣告場景給出準確地預估。
FM模型是否能得到交叉項引數w男性,化妝品呢?答案是肯定的。由於FM模型是把交叉項引數用對應的特徵隱向量內積表示,這裡表示為w男性,化妝品=⟨v男性,v化妝品⟩。
用男性特徵隱向量v男性和化妝品特徵隱向量v化妝品的內積表示交叉項引數w男性,化妝品。
由於FM學習的引數就是單特徵的隱向量,那麼男性看化妝品廣告的預估結果可以用⟨v男性,v化妝品⟩得到。這樣,即便訓練集中沒有出現男性看化妝品廣告的樣本,FM模型仍然可以用來預估,提升了預估能力。 -
FM提升了引數學習效率
這個顯而易見,引數個數由(n2+n+1)變為(nk+n+1)個,模型訓練複雜度也由O(mn2)變為O(mnk)。m為訓練樣本數。對於訓練樣本和特徵數而言,都是線性複雜度。
此外,就FM模型本身而言,它是在多項式模型基礎上對引數的計算做了調整,因此也有人把FM模型稱為多項式的廣義線性模型,也是恰如其分的。
從互動項的角度看,FM僅僅是一個可以表示特徵之間互動關係的函式表法式,可以推廣到更高階形式,即將多個互異特徵分量之間的關聯資訊考慮進來。例如在廣告業務場景中,如果考慮User-Ad-Context三個維度特徵之間的關係,在FM模型中對應的degree為3。
最後一句話總結,FM最大特點和優勢:
FM模型對稀疏資料有更好的學習能力,通過互動項可以學習特徵之間的關聯關係,並且保證了學習效率和預估能力。
場感知分解機
場感知分解機器(Field-aware Factorization Machine ,簡稱FFM)最初的概念來自於Yu-Chin Juan與其比賽隊員,它們借鑑了辣子Michael Jahrer的論文中field概念,提出了FM的升級版模型。
通過引入field的概念,FFM吧相同性質的特徵歸於同一個field。在FM開頭one-hot編碼中提到用於訪問的channel,編碼生成了10個數值型特徵,這10個特徵都是用於說明使用者PV時對應的channel類別,因此可以將其放在同一個field中。那麼,我們可以把同一個categorical特徵經過one-hot編碼生成的數值型特徵都可以放在同一個field中。
同一個categorical特徵可以包括使用者屬性資訊(年齡、性別、職業、收入、地域等),使用者行為資訊(興趣、偏好、時間等),上下文資訊(位置、內容等)以及其它資訊(天氣、交通等)。

這裡以NTU_FFM.pdf和美團-深入FFM原理與實踐都提到的例子,給出FFM-Fields特徵組合的工作過程。
給出一下輸入資料:
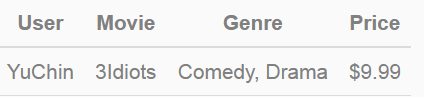
Price是數值型特徵,實際應用中通常會把價格劃分為若干個區間(即連續特徵離散化),然後再one-hot編碼,這裡假設$9.99對應的離散化區間tag為”2”。當然不是所有的連續型特徵都要做離散化,比如某廣告位、某類廣告/商品、抑或某類人群統計的歷史CTR(pseudo-CTR)通常無需做離散化。
該條記錄可以編碼為5個數值特徵,即User^YuChin, Movie^3Idiots, Genre^Comedy, Genre^Drama, Price2。其中GenreComedy, Genre^Drama屬於同一個field。為了說明FFM的樣本格式,我們把所有的特徵和對應的field對映成整數編號。

其中,紅色表示Field編碼,藍色表示Feature編碼,綠色表示樣本的組合特徵取值(離散化後的結果)。二階交叉項的係數是通過與Field相關的隱向量的內積得到的。如果單特徵有n個,全部做二階特徵組合的話,會有
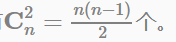
FFM應用場景
在我們的廣告業務系統、商業推薦以及自媒體-推薦系統中,FFM模型作為點選預估系統中的核心演算法之一,用於預估廣告、商品、文章的點選率(CTR)和轉化率(CVR)。
在鄙司廣告演算法團隊,點選預估系統已成為基礎設施,支援並服務於不同的業務線和應用場景。預估模型都是離線訓練,然後定時更新到線上實時計算,因此預估問題最大的差異就體現在資料場景和特徵工程。以廣告的點選率為例,特徵主要分為如下幾類:
- 使用者屬性與行為特徵:
- 廣告特徵:
- 上下文環境特徵:
為了使用開源的FFM模型,所以的特徵必須轉化為field_id:feat_id:value格式,其中field_id表示特徵所屬field的編號,feat_id表示特徵編號,value為特徵取值。數值型的特徵如果無需離散化,只需分配單獨的field編號即可,如歷史pseudo-ctr。categorical特徵需要經過one-hot編碼轉化為數值型,編碼產生的所有特徵同屬於一個field,特徵value只能是0/1, 如使用者年齡區間、性別、興趣、人群等。
開源工具FFM使用時,注意事項(參考新浪廣告演算法組的實戰經驗和美團-深入FFM原理與實踐):
樣本歸一化:
特徵歸一化:
省略0值特徵:
迴歸、分類、排序等。推薦演算法,預估模型(如CTR預估等)
更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/
