
深入淺出ML之Tree-Based家族
寫在前面
本章我想以一個例子作為直觀引入,來介紹決策樹的結構、學習過程以及具體方法在學習過程中的差異。(注:構造下面的成績示例資料,來說明決策樹的構造過程)

定義劃分等級的標準:
“等級1”把資料劃分為4個區間:

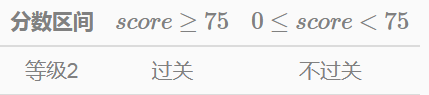
“等級2”的劃分 假設這次考試,成績超過75分算過關;小於75分不過關。得到劃分標準如下:
我們按照樹結構展示出來,如下圖所示:

如果按照“等級1”作為劃分標準,取值“優秀”,“良好”,“中等”和“較差”分別對應4個分支,如圖4.1所示。由於只有一個劃分特徵,它對應的是一個單層決策樹,亦稱作“決策樹樁”(Decision Stump)。
決策樹樁的特點是:只有一個非葉節點,或者說它的根節點等於內部節點(我們在下面介紹決策樹多層結構時再介紹)。
“等級1”取值型別是category,而在實際資料中,一些特徵取值可能是連續值(如這裡的score特徵)。如果用決策樹模型解決一些迴歸或分類問題的化,在學習的過程中就需要有將連續值轉化為離散值的方法在裡面,在特徵工程中稱為特徵離散化。
在圖4.2中,我們把連續值劃分為兩個區域,分別是score≥75 和 0≤score<75
圖4.3和圖4.4屬於CART(Classification and Regression Tree,分類與迴歸樹)模型。CART假設決策樹是二叉樹,根節點和內部節點的特徵取值為”是”或”否”,節點的左分支對應”是”,右分支對應“否”,每一次劃分特徵選擇都會把當前特徵對應的樣本子集劃分到兩個區域。
在CART學習過程中,不論特徵原有取值是連續值(如圖4.2)或離散值(圖4.3,圖4.4),也要轉化為離散二值形式。
直觀上看,迴歸樹與分類樹的區別取決於實際的應用場景(迴歸問題還是分類問題)以及對應的“Label”取值型別。
Label是連續值,通常對應的是迴歸樹;當Label是category時,對應分類樹模型;
後面會提到,CART學習的過程中最核心的是通過遍歷選擇最優劃分特徵及對應的特徵值。那麼二者的區別也體現在具體最優劃分特徵的方法上。
同樣,為了直觀瞭解本節要介紹的內容,這裡用一個表格來說明:

除了具體介紹這3個具體演算法對應的特徵選擇方法外,還會簡要的介紹決策樹學習過程出現的模型和資料問題,如過擬合問題,連續值和缺失值問題等。
決策樹學習過程
圖4.1~圖4.4給出的僅僅是單層決策樹,只有一個非葉節點(對應一個特徵)。那麼對於含有多個特徵的分類問題來說,決策樹的學習過程通常是一個通過遞迴選擇最優劃分特徵,並根據該特徵的取值情況對訓練資料進行分割,使得切割後對應的資料子集有一個較好的分類的過程。
為了更直觀的解釋決策樹的學習過程,這裡參考《資料探勘-實用機器學習技術》一書中P69頁提供的天氣資料,根據天氣情況決定是否出去玩,資料資訊如下:

利用ID3演算法中的資訊增益特徵選擇方法,遞迴的學習一棵決策樹,得到樹結構,如圖4.5所示:


這樣最終結果是每個子集都被分到葉節點上,對應著一個明確的類別。那麼,遞迴生成的層級結構即為一棵決策樹。我們將上面的文字描述用虛擬碼形式表達出來,即為:

決策樹學習過程中遞迴的每一步,在選擇最優特徵後,根據特徵取值切割當前節點的資料集,得到若干資料子集。由於決策樹學習過程是遞迴的選擇最優特徵,因此可以理解為這是一個特徵空間劃分的過程。每一個特徵子空間對應決策樹中的一個葉子節點,特徵子空間相應的類別就是葉子節點對應資料子集中樣本數最多的類別。
特徵選擇方法
上面多次提到遞迴地選擇最優特徵,根據特徵取值切割資料集,使得對應的資料子集有一個較好的分類。從虛擬碼中也可以看出,在決策樹學習過程中,最重要的是第07行,即如何選擇最優特徵?也就是我們常說的特徵選擇選擇問題。
顧名思義,特徵選擇就是將特徵的重要程度量化之後再進行選擇,而如何量化特徵的重要性,就成了各種方法間最大的區別。
例如卡方檢驗、斯皮爾曼法(Spearman)、互資訊等使用<feature, label>之間的關聯性來進行量化feature的重要程度。關聯性越強,特徵得分越高,該特徵越應該被優先選擇。
在這裡,希望隨著特徵選擇過程地不斷進行,決策樹的分支節點所包含的樣本儘可能屬於同一類別,即希望節點的”純度(purity)”越來越高。
如果子集中的樣本都屬於同一個類別,當然是最好的結果;如果說大多數的樣本型別相同,只有少部分樣本不同,也可以接受。
那麼如何才能做到選擇的特徵對應的樣本子集純度最高呢?
ID3演算法用資訊增益來刻畫樣例集的純度;C4.5演算法採用增益率;
CART演算法採用基尼指數來刻畫樣例集純度
資訊增益
資訊增益(Information Gain,簡稱IG)衡量特徵的重要性是根據當前特徵為劃分帶來多少資訊量,帶來的資訊越多,該特徵就越重要,此時節點的”純度”也就越高。
對一個分類系統來說,假設類別C可能的取值為c1,c2,⋯,ck(k是類別總數),每一個類別出現的概率分別是p(c1),p(c2),⋯,p(ck)。此時,分類系統的熵可以表示為:
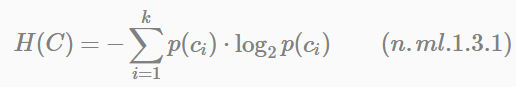
分類系統的作用就是輸出一個特徵向量(文字特徵、ID特徵、特徵特徵等)屬於哪個類別的值,而這個值可能是c1,c2,⋯,ck,因此這個值所攜帶的資訊量就是公式(n.ml.1.3.1)這麼多。


下面以天氣資料為例,介紹通過資訊增益選擇最優特徵的工作過程:
根據陰晴、溫度、溼度和颳風來決定是否出去玩。樣本中總共有14條記錄,取值為“是”和“否”的樣本數分別是9和5,即9個正樣本、5個負樣本,用S(9+,5−)表示,S表示樣本(sample)的意思。
(1). 分類系統的熵:
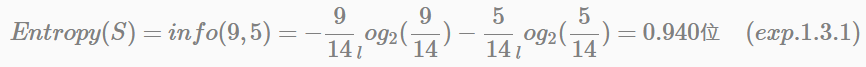
(2). 如果以特徵”陰晴”作為根節點。“陰晴”取值為{sunny, overcast, rainy}, 分別對應的正負樣本數分別為(2+,3-), (4+,0-), (3+,2-),那麼在這三個節點上的資訊熵分別為:
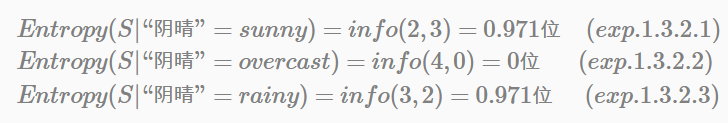
以特“陰晴”為根節點,平均資訊值(即條件熵)為:
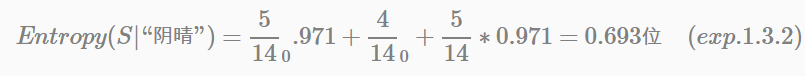
以特徵“陰晴”為條件,計算得到的條件熵代表了期望的資訊總量,即對於一個新樣本判定其屬於哪個類別所必需的資訊量。
(3). 計算特徵“陰晴”對應的資訊增益:
IG(“陰晴”)=Entropy(S)−Entropy(S|“陰晴”)=0.247位 (exp.1.3.3.1)
同樣的計算方法,可得每個特徵對應的資訊增益,即
IG(“颳風”)=Entropy(S)−Entropy(S|“颳風”)=0.048位 (exp.1.3.3.2)
IG(“溼度”)=Entropy(S)−Entropy(S|“溼度”)=0.152位 (exp.1.3.3.3)
IG(“溫度”)=Entropy(S)−Entropy(S|“溫度”)=0.029位 (exp.1.3.3.4)
顯然,特徵“陰晴”的資訊增益最大,於是把它作為劃分特徵。基於“陰晴”對根節點進行劃分的結果,如圖4.5所示(決策樹學習過程部分)。決策樹學習演算法對子節點進一步劃分,重複上面的計算步驟。
用資訊增益選擇最優特徵,並不是完美的,存在問題或缺點主要有以下兩個:
傾向於選擇擁有較多取值的特徵
尤其特徵集中包含ID類特徵時,ID類特徵會最先被選擇為分裂特徵,但在該類特徵上的分支對預測未知樣本的類別並無意義,降低了決策樹模型的泛化能力,也容易使模型易發生過擬合。
只能考察特徵對整個系統的貢獻,而不能具體到某個類別上
資訊增益只適合用來做所謂“全域性”的特徵選擇(指所有的類都使用相同的特徵集合),而無法做“本地”的特徵選擇(對於文字分類來講,每個類別有自己的特徵集合,因為有的詞項(word item)對一個類別很有區分度,對另一個類別則無足輕重)。
為了彌補資訊增益這一缺點,一個被稱為增益率(Gain Ratio)的修正方法被用來做最優特徵選擇。
增益率
與資訊增益不同,資訊增益率的計算考慮了特徵分裂資料集後所產生的子節點的數量和規模,而忽略任何有關類別的資訊。
以資訊增益示例為例,按照特徵“陰晴”將資料集分裂成3個子集,規模分別為5、4和5,因此不考慮子集中所包含的類別,產生一個分裂資訊為:
SplitInfo(“陰晴”)=info(5,4,5)=1.577位(exp.1.3.4)
分裂資訊熵(Split Information)可簡單地理解為表示資訊分支所需要的資訊量。
那麼資訊增益率:
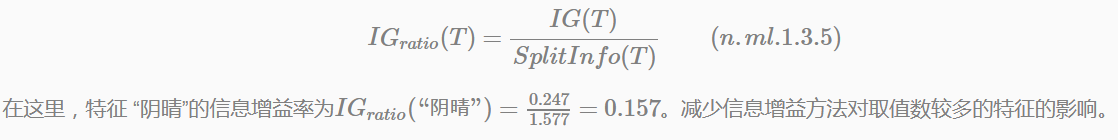
基尼指數(Gini Index)是CART中分類樹的特徵選擇方法。這部分會在下面的“分類與迴歸樹-二叉分類樹”一節中介紹。
分類與迴歸樹
分類與迴歸樹(Classification And Regression Tree, 簡稱CART)模型在Tree-Based家族中是應用最廣泛的學習方法之一。它既可以用於分類也可以用於迴歸。
一句話概括CART模型:
CART模型是在給定輸入隨機變數X條件下求得輸出隨機變數Y的條件概率分佈的學習方法。
在“寫在前面”也提到,CART假設決策樹時二叉樹結構,內部節點特徵取值為“是”和“否”,左分支對應取值為“是”的分支,右分支對應為否的分支,如圖4.3所示。這樣CART學習過程等價於遞迴地二分每個特徵,將輸入空間(在這裡等價特徵空間)劃分為有限個字空間(單元),並在這些字空間上確定預測的概率分佈,也就是在輸入給定的條件下輸出對應的條件概率分佈。
可以看出CART演算法在葉節點表示上不同於ID3、C4.5方法,後二者葉節點對應資料子集通過“多數表決”的方式來確定一個類別(固定一個值);而CART演算法的葉節點對應類別的概率分佈。如此看來,我們可以很容易地用CART來學習一個multi-label / multi-class / multi-task的分類任務。
與其它決策樹演算法學習過程類別,CART演算法也主要由兩步組成:
- 決策樹的生成:基於訓練資料集生成一棵二分決策樹;
- 決策樹的剪枝:用驗證集對已生成的二叉決策樹進行剪枝,剪枝的標準為損失函式最小化。
由於分類樹與迴歸樹在遞迴地構建二叉決策樹的過程中,選擇特徵劃分的準則不同。二叉分類樹構建過程中採用基尼指數(Gini Index)為特徵選擇標準;二叉迴歸樹採用平方誤差最小化作為特徵選擇標準。
二叉分類樹
二叉分類樹中用基尼指數(Gini Index)作為最優特徵選擇的度量標準。基尼指數定義如下:
同樣以分類系統為例,資料集D中類別C可能的取值為c1,c2,⋯,ck(k是類別數),一個樣本屬於類別ci的概率為p(i)。那麼概率分佈的基尼指數公式表示為:
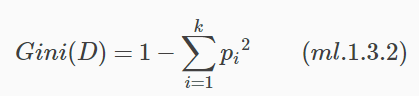

在實際操作中,通過遍歷所有特徵(如果是連續值,需做離散化)及其取值,選擇基尼指數最小所對應的特徵和特徵值。
這裡仍然以天氣資料為例,給出特徵“陰晴”的基尼指數計算過程。

二叉迴歸樹

下面要解決的問題是:如何劃分特徵空間?
一個啟發式的方式就是選擇特徵空間中第k個特徵fk和它的取值s,作為劃分特徵和劃分點。定義兩個區域(對應內部節點兩個分支):

