
深入淺出ML之Boosting家族
寫在前面
提升(boosting)方法是一類應用廣泛且非常有效的統計學習方法。
在2006年,Caruana和Niculescu-Mizil等人完成了一項實驗,比較當今世界上現成的分類器(off-the-shelf classifiers)中哪個最好?實現結果表明Boosted Decision Tree(提升決策樹)不管是在misclassification error還是produce well-calibrated probabilities方面都是最好的分離器,以ROC曲線作為衡量指標。(效果第二好的方法是隨機森林)
下圖給出的是Adaboost演算法(Decision Stump as Weak Learner)在處理二類分類問題時,隨著弱分類器的個數增加,訓練誤差與測試誤差的曲線圖。
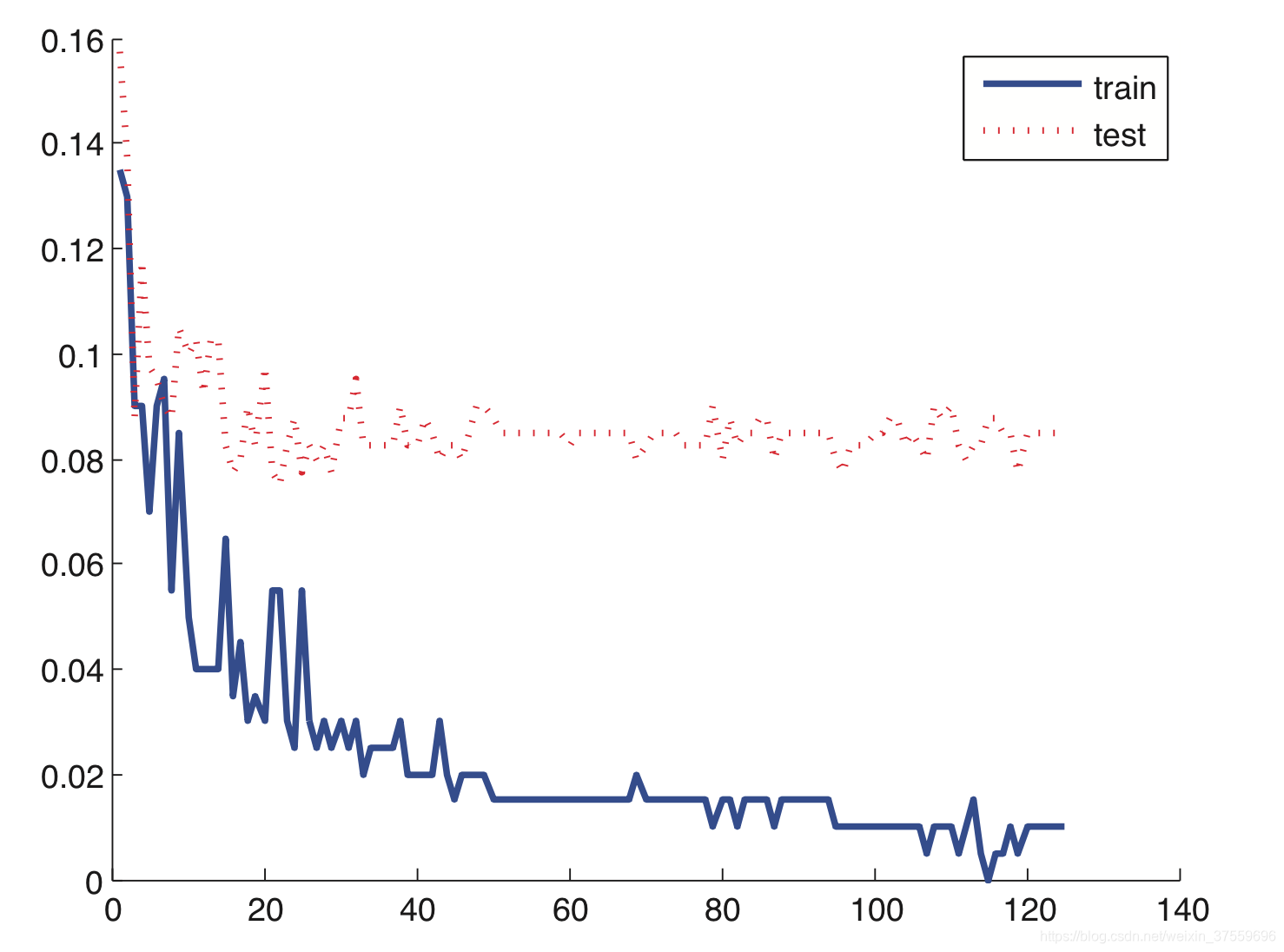
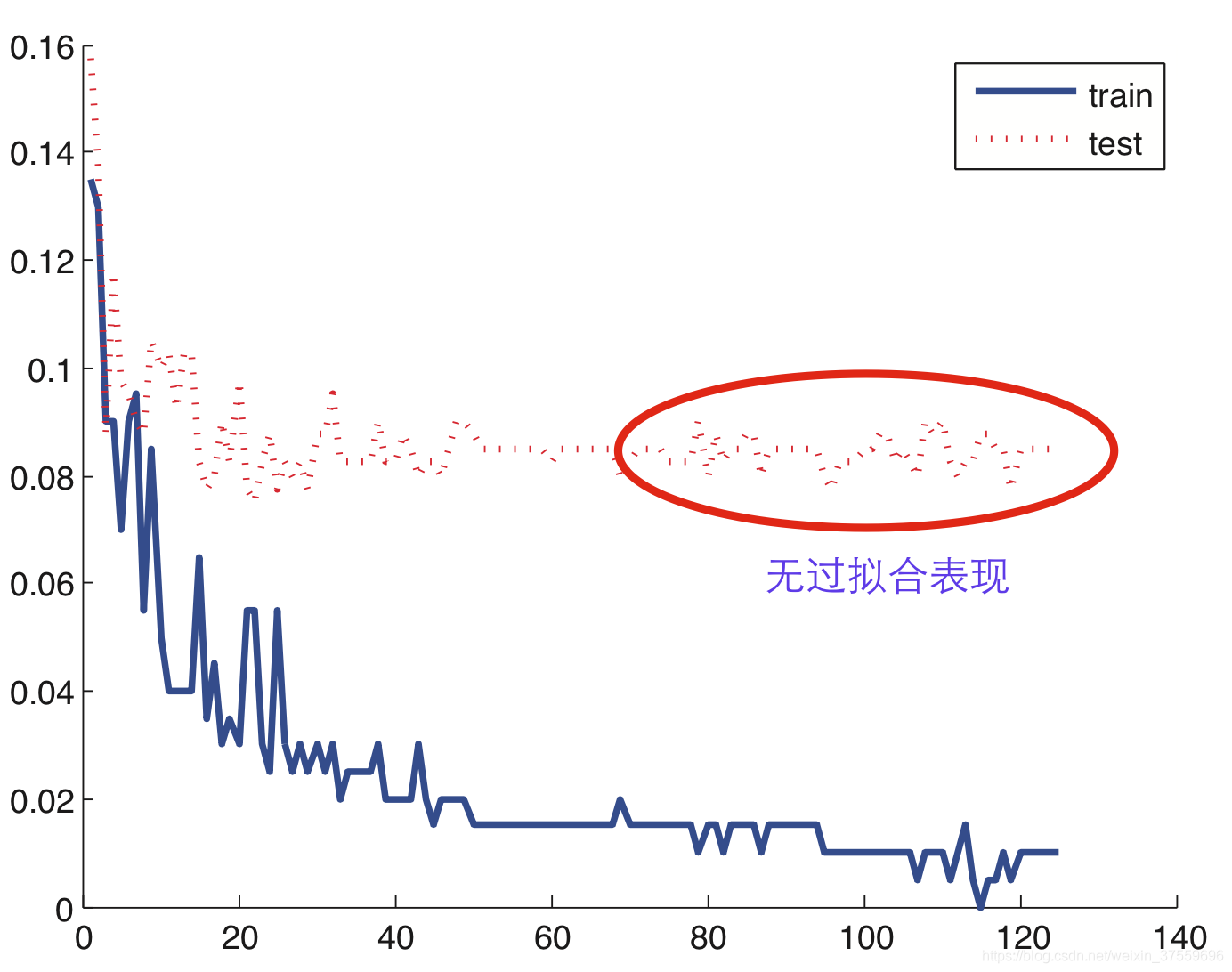
從圖中可以看出,Adaboost演算法隨著模型複雜度的增加,測試誤差(紅色點線)基本保持穩定,並沒有出現過擬合的現象。
其實不僅是Adaboost演算法有這種表現,Boosting方法的學習思想和模型結構上可以保證其不容易產生過擬合(除非Weak Learner本身出現過擬合)。
下面我們主要是從損失函式的差異,來介紹Boosting的家族成員;然後我們針對每個具體的家族成員,詳細介紹其學習過程和核心公式;最後從演算法應用場景和工具方法給出簡單的介紹。
Boosting
Boosting介紹
基本思想
Boosting方法基於這樣一種思想:
對於一個複雜任務來說,將多個專家的判定進行適當的綜合得出的判斷,要比其中任何一個專家單獨的判斷好。很容易理解,就是”三個臭皮匠頂個諸葛亮”的意思
歷史由來
歷史上,Kearns和Valiant首先提出了”強可學習(strongly learnable)”和“弱可學習(weakly learnable)”的概念。他們指出:
在概率近似正確(probably approximately correct,PAC)學習框架中:
- 一個概念(一個類,label),如果存在一個多項式的學習演算法能夠學習它,並且正確率很高,那麼就稱這個概念是強可學習的;
- 一個概念(一個類,label),如果存在一個多項式的學習演算法能夠學習它,學習的正確率僅比隨機猜測略好,那麼就稱這個概念是弱可學習的。
Schapire後來證明了: 強可學習和弱可學習是等價的。 也就是說,在PAC學習的框架下,一個概念是強可學習的 充分必要條件 是這個概念是弱可學習的。 表示如下:
強可學習⇔弱可學習
如此一來,問題便成為:在學習中,如果已經發現了”弱學習演算法”,那麼能否將它提升為”強學習演算法”? 通常的,發現弱學習演算法通常要比發現強學習演算法容易得多。那麼如何具體實施提升,便成為開發提升方法時所要解決的問題。關於提升方法的研究很多,最具代表性的當數AdaBoost演算法(是1995年由Freund和Schapire提出的)。
Boosting學習思路
對於一個學習問題來說(以分類問題為例),給定訓練資料集,求一個弱學習演算法要比求一個強學習演算法要容易的多。Boosting方法就是從弱學習演算法出發,反覆學習,得到一系列弱分類器,然後組合弱分類器,得到一個強分類器。Boosting方法在學習過程中通過改變訓練資料的權值分佈,針對不同的資料分佈呼叫弱學習演算法得到一系列弱分類器。
這裡面有兩個問題需要回答:
- 在每一輪學習之前,如何改變訓練資料的權值分佈?
- 如何將一組弱分類器組合成一個強分類器?
具體不同的boosting實現,主要區別在弱學習演算法本身和上面兩個問題的回答上。
針對第一個問題,Adaboost演算法的做法是:
- 提高那些被前一輪弱分類器錯誤分類樣本的權值,而降低那些被正確分類樣本的權值。
- 如此,那些沒有得到正確分類的樣本,由於其權值加大而受到後一輪的弱分類器的更大關注。
第二個問題,弱分類器的組合,AdaBoost採取加權多數表決的方法。具體地:
- 加大 分類誤差率小 的弱分類器的權值,使其在表決中起較大的作用;減小分類誤差率大的弱分類器的權值,使其在表決中起較小的作用。
- AdaBoost演算法的巧妙之處就在於它將這些學習思路自然並且有效地在一個演算法裡面實現。
前向分步加法模型
英文名稱:Forward Stagewise Additive Modeling
加法模型(addtive model)

前向分步演算法
在給定訓練資料及損失函式L(y,f(x))的條件下,學習加法模型f(x)成為經驗風險極小化即損失函式極小化的問題:
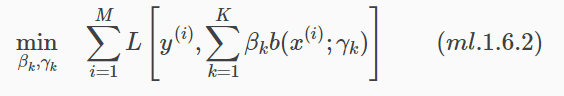
通常這是一個複雜的優化問題。前向分佈演算法(forward stagwise algorithm)求解這一優化問題的思路是:因為學習的是加法模型,如果能夠從前向後,每一步只學習一個基函式及其係數,逐步逼近優化目標函式式(ml.1.6.1),那麼就可以簡化優化的複雜度。具體地,每步只需優化如下損失函式:
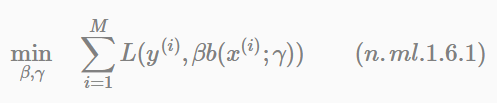

Boosting四大家族
Boosting並非是一個方法,而是一類方法。這裡按照損失函式的不同,將其細分為若干類演算法,下表給出了4種不同損失函式對應的Boosting方法:

二分類問題時損失函式示意圖:
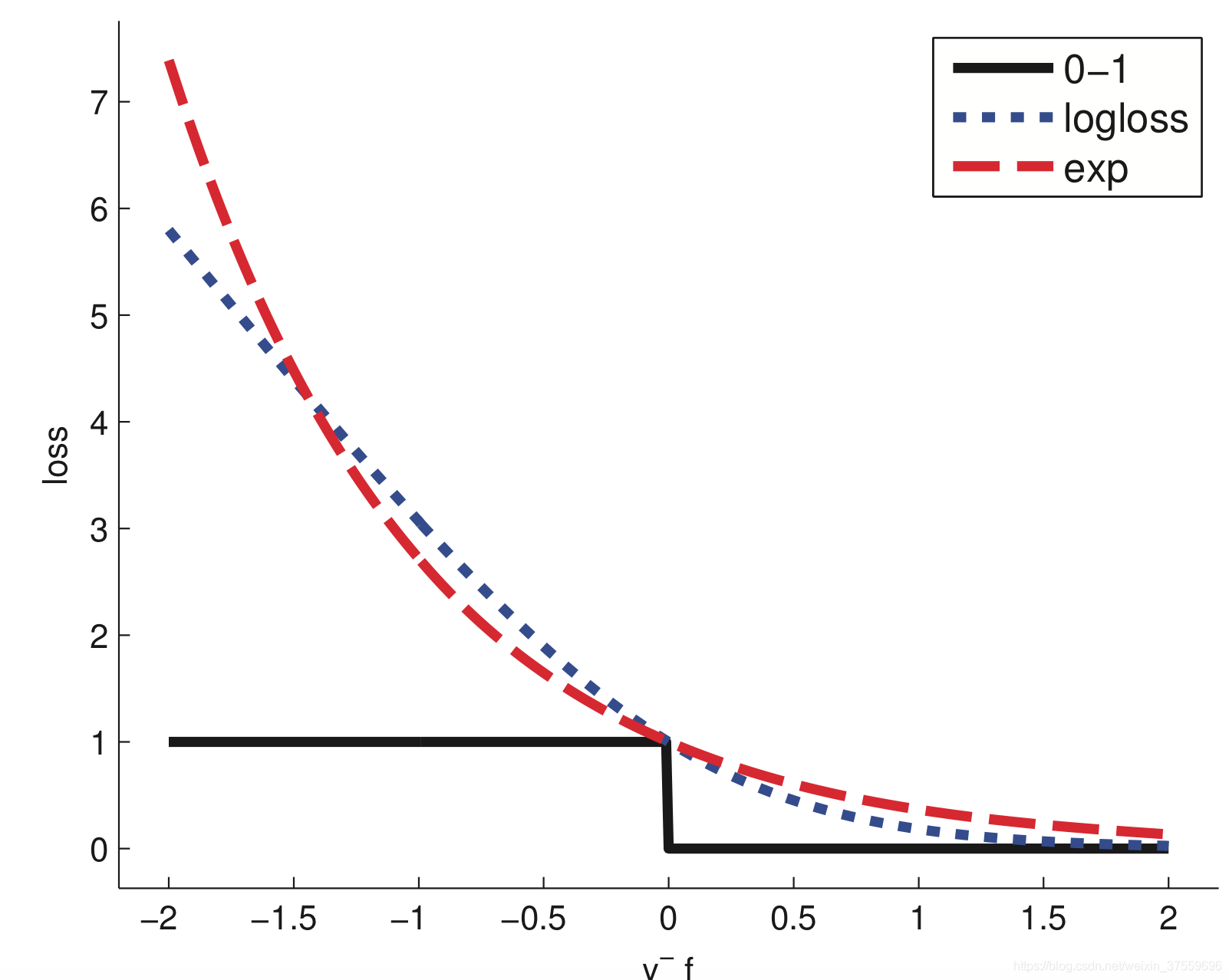
下面主要以AdaBoost演算法作為示例,給出以下3個問題的解釋:
- AdaBoost為什麼能夠提升學習精度?
- 如何解釋AdaBoost演算法?
- Boosting方法更具體的例項-Boosting Tree。
Adaboost
演算法學習過程
Adaboost演算法在分類問題中的主要特點:通過改變訓練樣本的權重,學習多個分類器,並將這些分類器進行線性組合,提高分類效能。 AdaBoost-演算法描述(虛擬碼)如下:


AdaBoost演算法描述說明



示例:AdaBoost演算法




訓練誤差分析
AdaBoost演算法最基本的性質是它能在學習過程中不斷減少訓練誤差,即在訓練資料集上的分類誤差率。 對於這個問題,有個定理可以保證分類誤差率在減少-AdaBoost的訓練誤差界。
定理:AdaBoost訓練誤差界
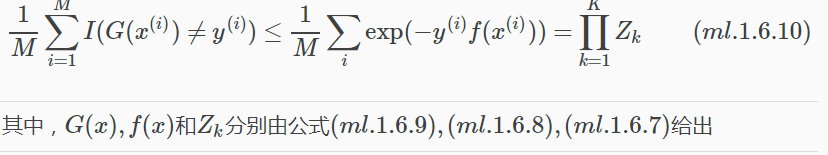
證明如下:


定理:二類分類問題AdaBoost訓練誤差界
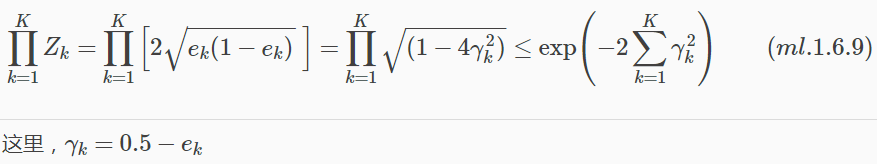

AdaBoost訓練誤差指數速率下降

推論表明,在此條件下,AdaBoost的訓練誤差是以指數速率下降的。這一性質對於AdaBoost計算(迭代)效率是利好訊息。
注意:AdaBoost演算法不需要知道下界γ,這正是Freund和Schapire設計AdaBoost時所考慮的。與一些早期的提升方法不同,AdaBoost具有適應性,即它能適應弱分類器各自的訓練誤差率。這也是其演算法名稱的由來(適應的提升)。Ada是Adaptive的簡寫。
前向分步加法模型與Adaboost
AdaBoost演算法還有另一個解釋,即可以認為AdaBoost演算法是模型為加法模型、損失函式為指數函式、學習演算法為前向分步演算法時的學習方法。
根據前向分步演算法可以推匯出AdaBoost,用一句話敘述這一關係.
AdaBoost演算法是前向分步加法演算法的特例
此時,模型是由基本分類器組成的加法模型,損失函式是指數函式。
證明:前向分步演算法學習的是加法模型,當基函式為基本分類器時,該加法模型等價於AdaBoost的最終分類器:


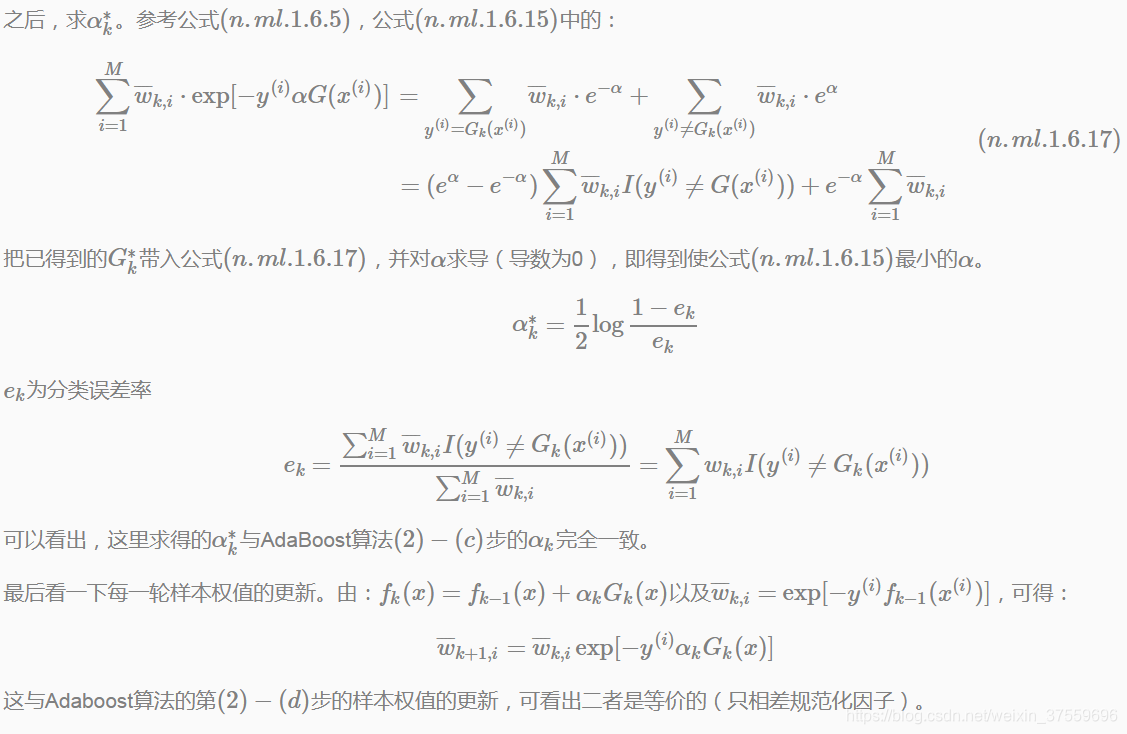
AdaBoost演算法缺點

Boosted Decision Tree
提升決策樹是指以分類與迴歸樹(CART)為基本分類器的提升方法,被認為是統計學習中效能最好的方法之一。
提升決策樹簡稱提升樹,Boosting Tree.
提升樹模型
提升樹模型實際採用加法模型(即基函式的線性組合)與前向分步演算法,以決策樹為基函式的提升方法稱為提升樹(Boosting Tree)。
對分類問題決策樹是二叉分類樹,對迴歸問題決策樹是二叉迴歸樹。

提升樹演算法

由於樹的線性組合可以很好的擬合訓練資料,即使資料中的輸入和輸出之間的關係很複雜也是如此,所以提升樹是一個高功能的學習演算法。
提升樹家族
不同問題的提升樹學習演算法,其主要區別在於損失函式不同。平方損失函式常用於迴歸問題,用指數損失函式用於分類問題,以及絕對損失函式用於決策問題。
二叉分類樹
對於二類分類問題,提升樹演算法只需要將AdaBoost演算法例子中的基本分類器限制為二叉分類樹即可,可以說此時的決策樹演算法時AdaBoost演算法的特殊情況。
損失函式仍為指數損失,提升樹模型仍為前向加法模型。
二叉迴歸樹

迴歸問題提升樹-前向分步演算法

迴歸問題提升樹-演算法描述

Gradient Boosting
提升樹方法是利用加法模型與前向分佈演算法實現整個優化學習過程。Adaboost的指數損失和迴歸提升樹的平方損失,在前向分佈中的每一步都比較簡單。但對於一般損失函式而言(比如絕對損失),每一個優化並不容易。
針對這一問題。Freidman提出了梯度提升(gradient boosting)演算法。該演算法思想:
利用損失函式的負梯度在當前模型的值作為迴歸問題提升樹演算法中殘差的近似值,擬合一個迴歸樹。
損失函式的負梯度為:
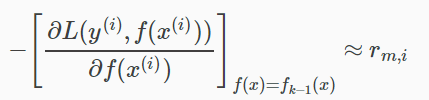
Gradient Boosting-演算法描述

演算法解釋:
第(1)步初始化,估計使損失函式極小化的常數值(是一個只有根結點的樹);
第(2)(a)步計算損失函式的負梯度在當前模型的值,將它作為殘差的估計。(對於平方損失函式,他就是殘差;對於一般損失函式,它就是殘差的近似值)
第(2)(b)步估計迴歸樹的結點區域,以擬合殘差的近似值;
第(2)©步利用線性搜尋估計葉結點區域的值,使損失函式極小化;
第(2)(d)步更新迴歸樹。
更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/
