
深入淺出ML之Entropy-Based家族
基本概念
熵與資訊熵
如何理解熵的含義?
自然界的事物,如果任其自身發展,最終都會達到儘可能的平衡或互補狀態。舉例:
一盒火柴,(人為或外力)有序地將其擺放在一個小盒子裡,如果不小心火柴盒打翻了,火柴會“散亂”地灑在地板上。此時火柴雖然很亂,但這是它自身發展的結果。
上面描述的其實是自然界的熵。在自然界中,熵可以這樣表述:
熵是描述事物無序性的引數,熵越大則無序性越強。
那麼,在資訊理論中,我們用熵表示一個隨機變數的不確定性,那麼如何量化資訊的不確定性呢?
資訊熵公式定義

條件熵
設X,Y為兩個隨機變數,在X發生的前提下,Y發生所新帶來的熵 定義為Y的條件熵(Conditional Entropy),用H(Y|X)表示,計算公式如下:
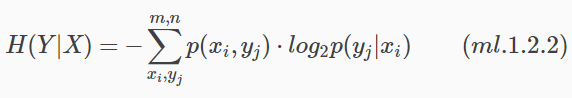
其物理含義是當變數X已知時,變數Y的平均不確定性是多少。公式(ml.1.2.2)推導如下:

聯合熵
一個隨機變數的不確定性可以用熵來表示,這一概念可以直接推廣到多個隨機變數。
聯合熵計算(Joint Entropy)

聯合熵特點

相對熵、KL距離
相對熵概念
相對熵,又稱為交叉熵或KL距離,是Kullback-Leibler散度(Kullback-Leibler Divergence)的簡稱。它主要用於衡量相同事件空間裡的兩個概率分佈的差異。簡單介紹其背景:

從公式(ml.1.2.4)可以看出,當兩個概率分佈完全相同時,KL距離為0。概率分佈P(x)的資訊熵如公式(ml.1.2.1)所示,說的是如果按照概率分佈P(x)編碼時,描述這個隨機事件至少需要多少位元編碼。
因此,KL距離的物理意義可以這樣表達:
在相同的事件空間裡,概率分佈為P(x)的事件空間,若用概率分佈Q(x)編碼時,平均每個基本事件(符號)編碼長度增加了多少位元數。
通過資訊熵可知,不存在其它比按照隨機事件本身概率分佈更好的編碼方式了,所以D(P||Q)始終是大於等於0的。
雖然KL被稱為距離,但是其不滿足距離定義的3個條件:1) 非負性;2) 對稱性(不滿足);3) 三角不等式(不滿足)。
KL距離示例

從示例中,我們可以得出結論:對於一個資訊源進行編碼,按照其本身的概率分佈進行編碼,每個字元的平均位元數最少。 這也是資訊熵的概念,用於衡量資訊源本身的不確定性。
此外可以看出,KL距離不滿足對稱性,即D(P||Q)不一定等於D(Q||P)。
相對熵應用場景
推薦系統-物品之間相似度

如果說相對熵(KL)距離衡量的是相同事件空間裡的兩個事件的相似度大小,那麼,互資訊通常用來衡量不同事件空間裡的兩個資訊(隨機事件、變數)的相關性大小。
互資訊計算公式
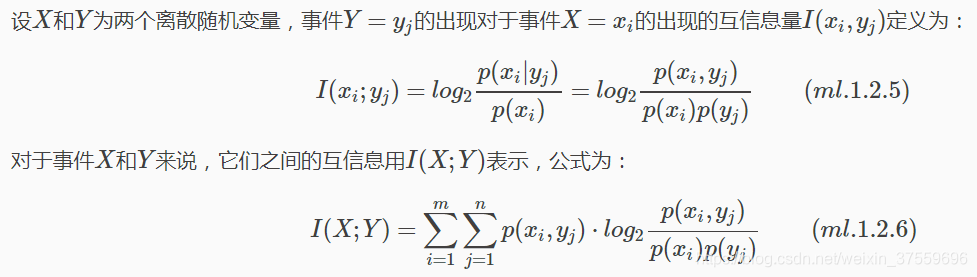
公式解釋:
互資訊就是隨機事件X的不確定性(即熵H(X)),以及在給定隨機變數Y條件下的不確定性(即條件熵H(X|Y))之間的差異,即I(X;Y)=H(X)−H(X|Y)(n.ml.1.2.7)
互資訊與決策樹中的資訊增益等價: 互資訊 ⟺ 資訊增益.
所謂兩個事件相關性的量化度量,就是在瞭解了其中一個事件Y的前提下,對消除另一個事件X不確定性所提供的資訊量。
互資訊與其它熵之間的關係
H(X|Y)=H(X,Y)−H(Y)
I(X;Y)=H(X)+H(Y)−H(X,Y)
I(X;Y)=H(X)−H(X|Y)
I(X;X)=H(X)
互資訊應用場景

最大熵模型(Maximum Entropy Model)
最大熵原理
在介紹最大熵模型之前,我們先了解一下最大熵原理,因為最大熵原理是選擇最優概率模型的一個準則。
最大熵原理:在概率模型空間集合中,在滿足給定約束條件的前提下,使資訊熵最大化得到的概率模型,就是最優的模型。
通常用約束條件來確定概率模型的集合。
理解最大熵原理
假設離散隨機變數X的概率分佈是P(X),其資訊熵可用公式(ml.1.2.1) 表示,並且熵滿足以下不等式:
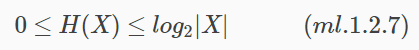
其中,|X|是X的取值個數,當且僅當X的分佈是均勻分佈時右邊的等號才成立。也就是說,當X服從均勻分佈時,熵最大。
根據最大熵原理學習概率模型堅持的原則:首先必須滿足已有的事實,即約束條件;但對不確定的部分不做任何假設,堅持無偏原則。最大熵原理通過熵的最大化來表示等可能性。
最大熵原理舉例(本示例來自《統計學習方法》第6章-李航老師)

最大熵模型定義
最大熵原理是統計學習的一般原理,將它應用到分類問題中,即得到最大熵模型。
最大熵模型引入

首先,考慮模型應滿足的條件

特徵函式(Feature Function)
定義特徵函式 f(x,y)用於描述輸入x和輸出y之間滿足的某一種事實:

最大熵模型定義
假設滿足所有約束條件的模型集合為:
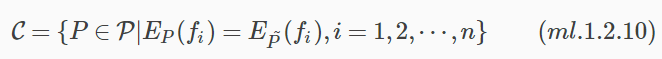
定義在條件概率分佈P(y|x)上的條件熵為:
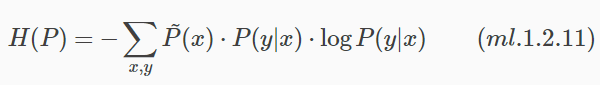
模型集合C中條件熵H§最大的模型稱為最大熵模型。
注:最大熵模型中log是指以e為底的對數,與資訊熵公式中以2為底不同。本文如無特殊說明,log均指自然對數。
最大熵模型引數學習
最大熵模型學習過程即為求解最大熵模型的過程,最大熵模型的學習問題可以表示為帶有約束的最優化問題。
示例:學習《最大熵原理》示例中的最大熵模型
為了簡便,這裡分別以y1,y2,y3,y4,y5表示A,B,C,D和E,最大熵模型學習的最優化問題可以表示為:
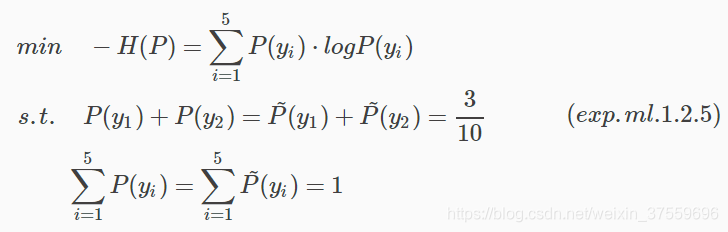



最大熵模型學習一般流程

求解約束最優化問題(ml.1.2.13)所得出的解,就是最大熵模型學習的解。
將約束最優化的原始問題轉換為無約束最優化的對偶問題。具體推導過程如下:

通俗的講,由_最小最大問題_轉化為_最大最小問題_。
由於最大熵模型對應的朗格朗日函式L(P,w)是引數P的凸函式,所以原始問題(ml.1.2.15)的解與對偶問題(ml.1.2.16)的解是等價的。因此,可以通過求解對偶問題來得到原始問題的解。



最後,求解對偶問題外部的極大化問題
對偶問題外部極大化表示式:

對偶函式極大化與極大似然估計等價
從最大熵模型的學習過程可以看出,最大熵模型是由n.ml.1.2.14和n.ml.1.2.15表示的條件概率分佈。下面證明:對偶函式的極大化等價於最大熵模型的極大似然估計。
對偶函式極大化=極大似然估計

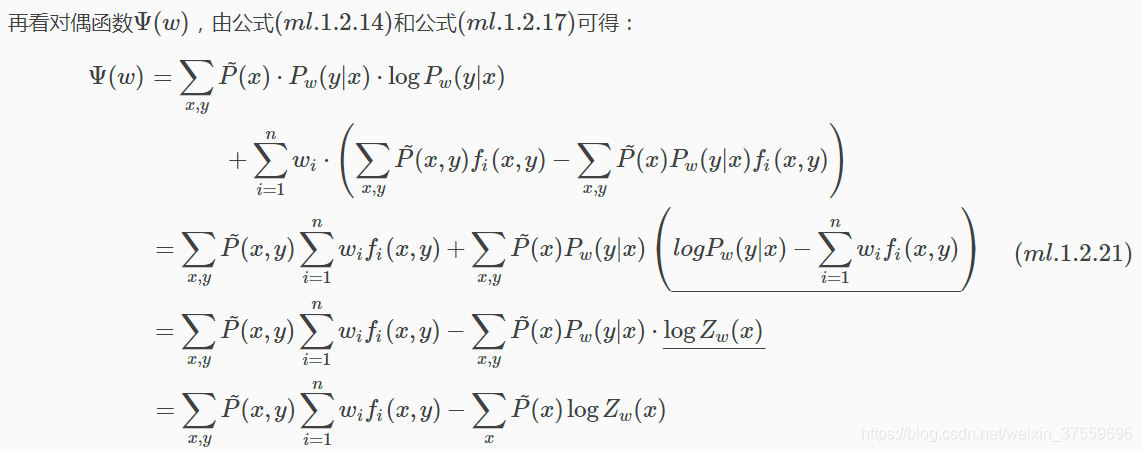

比較公式(ml.1.2.20)和(ml.1.2.21),可以發現:

總結:最大熵模型的學習問題就轉化為具體求解對數似然函式極大化或對偶函式極大化的問題。
可以將最大熵模型寫成更為一般的形式:

小結:
①. 最大熵模型與LR模型有類似的形式,它們又稱為對數線性模型(Log Linear Model)。
②. 模型學習就是在給定的訓練資料條件下對模型進行極大似然估計或正則化的極大似然估計。
引數學習的最優化問題
已知偶函式極大化與極大似然估計等價,那麼LR模型、最大熵模型的學習問題可以歸結為以似然函式為目標函式的最優化問題,通常通過迭代演算法求解(非閉式解)。
從最優化的角度來,此時的目標函式具有良好的性質:光滑的凸函式。因此多種最優化方法都適用,並且能保證找到全域性最優解。常用的方法有改進的迭代尺度法(Improved Iterative Scaling, IIS)、梯度下降法(SGD、mini-batch GD等)、共軛梯度法、擬牛頓法等。
更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/